「生成對抗網路」這個名稱中的「生成」是什麼意思?「生成式」是指一類統計模型,與判別式模型相對。
非正式:
- 生成式模型可產生新的資料實例。
- 判別式模型則用來區分不同種類的資料實例。
生成式模型可產生看起來像真實動物的新動物相片,而判別式模型則可分辨狗和貓。GAN 只是一種生成式模型。
更正式地說,假設有 X 組資料例項和 Y 組標籤:
- 生成式模型會擷取聯合機率 p(X, Y),如果沒有標籤,則只擷取 p(X)。
- 判別式模型會擷取條件機率 p(Y | X)。
生成式模型包含資料本身的分布,並會告訴您特定範例的可能性。舉例來說,預測序列中下一個字詞的模型通常是生成式模型 (通常比 GAN 簡單許多),因為這類模型可以為字詞序列指派機率。
判別式模型會忽略特定例項是否可能的問題,只會告訴您標籤套用至例項的可能性。
請注意,這是非常一般性的定義。生成式模型的類型繁多,GAN 只是一種生成式模型。
模擬機率
無論是哪一種模型,都不需要傳回代表機率的數字。您可以模仿該分布情形,建立資料分布的模型。
舉例來說,決策樹等區別式分類器可以標記例項,但不為該標籤指派機率。由於所有預測標籤的分布會模擬資料中標籤的實際分布,因此這類分類器仍會是模型。
同樣地,生成式模型可以產生令人信服的「假」資料,讓資料看起來像是從該分布圖繪製而成,進而模擬分布圖。
生成式模型很難
生成式模型要處理的任務比類似的判別模型更為困難。生成式模型必須模擬更多。
圖片生成式模型可能會擷取相關性,例如「看起來像船的物體可能會出現在看起來像水的物體附近」,以及「眼睛不太可能出現在額頭上」。這些是相當複雜的分布情形。
相較之下,判別式模型可能只需尋找幾個明顯的模式,就能學習「帆船」或「非帆船」之間的差異。這可能會忽略生成式模型必須正確處理的許多相關性。
判別式模型會嘗試在資料空間中劃出界線,而生成式模型則會嘗試模擬資料在整個空間中的放置方式。舉例來說,下圖顯示手寫阿拉伯數字的判別式和生成式模型:
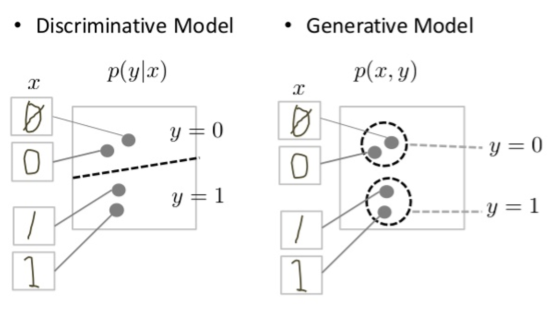
圖 1:手寫數字的判別式和生成式模型。
判別式模型會在資料空間中劃出分隔線,藉此區分手寫 0 和 1 的差異。如果它正確取得線條,就能區分 0 和 1,而無須模擬實例在線條兩側資料空間中的確切位置。
相反地,生成式模型會嘗試產生可信的 1 和 0,方法是產生與資料空間中實際對應項目相近的數字。必須模擬整個資料空間的分布情形。
GAN 提供了一種有效方法,可訓練這類豐富的模型,使其類似於實際分布。為了瞭解 GAN 的運作方式,我們需要先瞭解 GAN 的基本結構。
檢查您的理解程度:生成式模型與判別式模型
- 擲出三個六面骰子。
- 將滾動值乘以常數 w。
- 重複 100 次,並計算所有結果的平均值。