"Generative" ในชื่อ "Generative Adversarial Network" หมายความว่าอย่างไร "Generative" อธิบายคลาสของโมเดลทางสถิติที่ตรงข้ามกับโมเดลการแยกแยะ
ไม่เป็นทางการ
- โมเดล Generative สร้างอินสแตนซ์ข้อมูลใหม่ได้
- โมเดลแยกแยะจะแยกแยะอินสแตนซ์ข้อมูลประเภทต่างๆ
โมเดล Generative อาจสร้างรูปภาพสัตว์ใหม่ๆ ที่ดูเหมือนสัตว์จริง ขณะที่โมเดลการแยกแยะอาจแยกสุนัขออกจากแมวได้ GAN เป็นเพียงโมเดล Generative เพียงประเภทเดียว
ในทางที่เป็นทางการมากขึ้น เมื่อพิจารณาชุดอินสแตนซ์ข้อมูล X และชุดป้ายกำกับ Y
- โมเดลGenerative จะจับคู่ความน่าจะเป็นร่วม p(X, Y) หรือเพียงแค่ p(X) หากไม่มีป้ายกำกับ
- โมเดลที่แยกแยะจะจับความน่าจะเป็นแบบมีเงื่อนไข p(Y | X)
โมเดล Generative จะมีข้อมูลการแจกแจงของข้อมูลเอง และบอกความน่าจะเป็นของตัวอย่างหนึ่งๆ ให้คุณทราบ เช่น โมเดลที่คาดคะเนคำถัดไปในลำดับมักจะเป็นโมเดล Generative (มักจะง่ายกว่า GAN มาก) เนื่องจากสามารถกำหนดความน่าจะเป็นให้กับลำดับคำได้
โมเดลการแยกแยะจะไม่สนใจคำถามที่ว่าอินสแตนซ์หนึ่งๆ มีแนวโน้มหรือไม่ และจะบอกคุณเพียงว่าป้ายกำกับมีแนวโน้มที่จะใช้กับอินสแตนซ์นั้นมากน้อยเพียงใด
โปรดทราบว่านี่เป็นคำจำกัดความทั่วไป โมเดล Generative มีอยู่หลายประเภท GAN เป็นเพียงโมเดล Generative ประเภทหนึ่งเท่านั้น
การประมาณความน่าจะเป็น
โมเดลทั้ง 2 ประเภทไม่จำเป็นต้องแสดงผลตัวเลขที่แสดงถึงความน่าจะเป็น คุณจําลองการแจกแจงข้อมูลได้โดยเลียนแบบการแจกแจงนั้น
เช่น ตัวแยกประเภทแบบแบ่งกลุ่ม เช่น ต้นไม้การตัดสินใจ สามารถติดป้ายกำกับอินสแตนซ์ได้โดยไม่ต้องกำหนดความน่าจะเป็นให้กับป้ายกำกับนั้น เครื่องมือจัดประเภทดังกล่าวจะยังคงเป็นโมเดลอยู่ เนื่องจากความถี่ของป้ายกำกับที่คาดการณ์ทั้งหมดจะจําลองความถี่จริงของป้ายกำกับในข้อมูล
ในทํานองเดียวกัน โมเดล Generative สามารถสร้างการแจกแจงได้โดยสร้างข้อมูล "จําลอง" ที่สมจริงซึ่งดูเหมือนว่าดึงมาจากการแจกแจงนั้น
โมเดล Generative เป็นเรื่องยาก
โมเดล Generative ทำงานได้ยากกว่าโมเดลการแยกแยะในลักษณะเดียวกัน โมเดล Generative ต้องจําลองมากขึ้น
โมเดล Generative สำหรับรูปภาพอาจจับความสัมพันธ์ เช่น "สิ่งที่ดูเหมือนเรือมีแนวโน้มที่จะปรากฏใกล้กับสิ่งที่ดูเหมือนน้ำ" และ "ดวงตามีแนวโน้มที่จะไม่ปรากฏบนหน้าผาก" ข้อมูลเหล่านี้เป็นการแจกแจงที่ซับซ้อนมาก
ในทางตรงกันข้าม โมเดลการแยกแยะอาจเรียนรู้ความแตกต่างระหว่าง "เรือใบ" กับ "ไม่ใช่เรือใบ" โดยการมองหารูปแบบที่บ่งบอกเพียงไม่กี่แบบ และอาจละเว้นความสัมพันธ์หลายอย่างที่โมเดล Generative ต้องถูกต้อง
โมเดลการแยกแยะจะพยายามวาดขอบเขตในพื้นที่ข้อมูล ขณะที่โมเดลการสร้างจะพยายามจำลองวิธีจัดวางข้อมูลในพื้นที่ ตัวอย่างเช่น แผนภาพต่อไปนี้แสดงโมเดลการแยกแยะและโมเดลการสร้างตัวเลขที่เขียนด้วยมือ
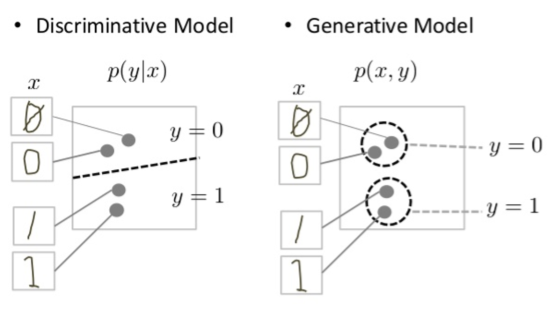
รูปที่ 1: โมเดลการแยกแยะและโมเดลการสร้างข้อมูลใหม่ (Generative model) ของตัวเลขที่เขียนด้วยลายมือ
โมเดลการแยกแยะจะพยายามแยกความแตกต่างระหว่าง 0 และ 1 ที่เขียนด้วยมือโดยการลากเส้นในพื้นที่ข้อมูล หากสามารถหาเส้นแบ่งได้ ก็จะแยก 0 ออกจาก 1 ได้โดยไม่ต้องจําลองตําแหน่งอินสแตนซ์ในพื้นที่ข้อมูลของเส้นแบ่ง
ในทางตรงกันข้าม โมเดล Generative จะพยายามสร้าง 1 และ 0 ที่สมเหตุสมผลโดยสร้างตัวเลขที่ใกล้เคียงกับตัวเลขจริงในพื้นที่ข้อมูล โดยต้องจําลองการแจกแจงทั่วทั้งพื้นที่ข้อมูล
GAN เป็นวิธีที่มีประสิทธิภาพในการฝึกโมเดลที่สมบูรณ์แบบดังกล่าวให้คล้ายกับข้อมูลจริง หากต้องการทำความเข้าใจวิธีการทำงานของ GAN เราจะต้องเข้าใจโครงสร้างพื้นฐานของ GAN
ตรวจสอบความเข้าใจของคุณ: โมเดล Generative กับ Discriminative
- ทอยลูกเต๋า 6 ด้าน 3 ลูก
- คูณจำนวนเงินที่โอนด้วยค่าคงที่ w
- ทำซ้ำ 100 ครั้ง แล้วหาค่าเฉลี่ยของผลลัพธ์ทั้งหมด