“生成对抗网络”中的“生成”是什么意思? “生成”描述了与判别模型相对的一类统计模型。
非正式:
- 生成模型可以生成新的数据实例。
- 判别模型可以区分不同类型的数据实例。
生成式模型可以生成看起来像真实动物的新动物照片,而判别式模型可以区分狗和猫。GAN 只是一种生成式模型。
更正式地说,给定一组数据实例 X 和一组标签 Y:
- 生成模型会捕获联合概率 p(X, Y),如果没有标签,则仅捕获 p(X)。
- 判别模型可捕获条件概率 p(Y | X)。
生成式模型包含数据本身的分布,并告知您给定示例的可能性。例如,用于预测序列中下一个字词的模型通常是生成式模型(通常比 GAN 简单得多),因为它们可以为一系列字词分配概率。
判别模型会忽略给定实例是否可能属于某个类别的问题,而只会告诉您某个标签适用于该实例的可能性。
请注意,这是一个非常笼统的定义。生成式模型有很多种。GAN 只是一种生成模型。
建模概率
这两种模型都无需返回表示概率的数字。您可以通过模仿该分布来对数据分布进行建模。
例如,决策树等判别分类器可以为实例分配标签,而无需为该标签分配概率。这样的分类器仍然是一种模型,因为所有预测标签的分布都将模拟数据中标签的实际分布。
同样,生成式模型可以通过生成看起来像是从该分布中提取的逼真的“虚假”数据来对分布进行建模。
生成模型很难
与类似的判别模型相比,生成式模型要解决更难的任务。生成模型必须模拟更多。
图像生成式模型可能会捕获“看起来像船的东西可能出现在看起来像水的东西附近”和“眼睛不太可能出现在额头上”等相关性。这些是极其复杂的分布。
与之相反,分类模型只需查找一些特征模式,即可学会区分“帆船”与“非帆船”。它可能会忽略生成式模型必须正确处理的许多相关性。
判别模型会尝试在数据空间中划定边界,而生成式模型会尝试对数据在整个空间中的放置方式进行建模。例如,下图显示了手写数字的辨别式和生成式模型:
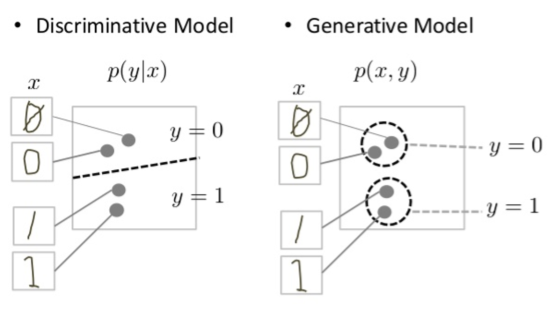
图 1:手写数字的判别模型和生成模型。
判别模型会尝试在数据空间中绘制一条线,以区分手写的 0 和 1。如果它能正确找到分界线,则可以区分 0 和 1,而无需对实例在数据空间中位于分界线两侧的确切位置进行建模。
与之相反,生成式模型会尝试生成逼真的 1 和 0,方法是生成与数据空间中的真实数字相近的数字。它必须对整个数据空间中的分布进行建模。
GAN 提供了一种有效的方法来训练此类丰富的模型,使其类似于真实分布。为了了解它们的运作方式,我们需要了解 GAN 的基本结构。
检查您的理解情况:生成式模型与判别模型
- 掷三个六面骰子。
- 将滚动量乘以常数 w。
- 重复 100 次,然后计算所有结果的平均值。