این صفحه شامل اصطلاحات واژهنامه هوش مصنوعی مولد است. برای مشاهده همه اصطلاحات واژهنامه، اینجا کلیک کنید .
الف
انطباق
مترادف برای تنظیم یا تنظیم دقیق .
عامل
نرمافزاری که میتواند ورودیهای کاربر را تحلیل کند تا بتواند اقداماتی را از طرف کاربر برنامهریزی و اجرا کند.
در یادگیری تقویتی ، یک عامل، موجودیتی است که از یک سیاست برای به حداکثر رساندن بازده مورد انتظار حاصل از انتقال بین حالتهای محیط استفاده میکند.
عامل
صفت فاعل . Agentic به ویژگیهایی که فاعلها دارند (مانند خودمختاری) اشاره دارد.
گردش کار عاملی
فرآیندی پویا که در آن یک عامل به طور مستقل اقداماتی را برای دستیابی به یک هدف برنامهریزی و اجرا میکند. این فرآیند ممکن است شامل استدلال، فراخوانی ابزارهای خارجی و خوداصلاحی برنامه خود باشد.
شیب هوش مصنوعی
خروجی از یک سیستم هوش مصنوعی مولد که کمیت را بر کیفیت ترجیح میدهد. به عنوان مثال، یک صفحه وب با شیب هوش مصنوعی پر از محتوای بیکیفیت، تولید شده توسط هوش مصنوعی و ارزان است.
ارزیابی خودکار
استفاده از نرمافزار برای قضاوت در مورد کیفیت خروجی یک مدل.
وقتی خروجی مدل نسبتاً سرراست باشد، یک اسکریپت یا برنامه میتواند خروجی مدل را با یک پاسخ طلایی مقایسه کند. این نوع ارزیابی خودکار گاهی اوقات ارزیابی برنامهریزیشده نامیده میشود. معیارهایی مانند ROUGE یا BLEU اغلب برای ارزیابی برنامهریزیشده مفید هستند.
وقتی خروجی مدل پیچیده است یا هیچ پاسخ صحیحی ندارد، گاهی اوقات یک برنامه یادگیری ماشین جداگانه به نام autorater ارزیابی خودکار را انجام میدهد.
در تضاد با ارزیابی انسانی .
ارزیابی خودکار
یک مکانیزم ترکیبی برای قضاوت در مورد کیفیت خروجی یک مدل هوش مصنوعی مولد که ارزیابی انسانی را با ارزیابی خودکار ترکیب میکند. یک autorater یک مدل یادگیری ماشینی است که بر روی دادههای ایجاد شده توسط ارزیابی انسانی آموزش دیده است. در حالت ایدهآل، یک autorater یاد میگیرد که از یک ارزیاب انسانی تقلید کند.ارزیابهای خودکار از پیش ساخته شده در دسترس هستند، اما بهترین ارزیابهای خودکار به طور خاص برای کاری که ارزیابی میکنید تنظیم شدهاند.
مدل خودرگرسیون
مدلی که پیشبینی را بر اساس پیشبینیهای قبلی خود استنتاج میکند. برای مثال، مدلهای زبانی خودرگرسیو، توکن بعدی را بر اساس توکنهای پیشبینیشده قبلی پیشبینی میکنند. همه مدلهای زبانی بزرگ مبتنی بر Transformer خودرگرسیو هستند.
در مقابل، مدلهای تصویر مبتنی بر GAN معمولاً خود-همبسته نیستند زیرا تصویر را در یک مسیر رو به جلو تولید میکنند و نه به صورت تکراری در مراحل مختلف. با این حال، برخی از مدلهای تولید تصویر خود-همبسته هستند زیرا تصویر را در مراحل مختلف تولید میکنند.
ب
مدل پایه
یک مدل از پیش آموزشدیده که میتواند به عنوان نقطه شروع برای تنظیم دقیق جهت رسیدگی به وظایف یا برنامههای خاص عمل کند.
همچنین به مدل از پیش آموزشدیده و مدل پایه مراجعه کنید.
سی
القای زنجیرهای افکار
یک تکنیک مهندسی سریع که یک مدل زبان بزرگ (LLM) را تشویق میکند تا استدلال خود را گام به گام توضیح دهد. برای مثال، دستور زیر را در نظر بگیرید و به جمله دوم توجه ویژهای داشته باشید:
راننده در خودرویی که در عرض ۷ ثانیه از ۰ به ۶۰ مایل در ساعت میرسد، چند نیروی گرانش را تجربه میکند؟ در پاسخ، تمام محاسبات مربوطه را نشان دهید.
پاسخ LLM احتمالاً این خواهد بود:
- دنبالهای از فرمولهای فیزیک را نشان دهید و مقادیر ۰، ۶۰ و ۷ را در مکانهای مناسب قرار دهید.
- توضیح دهید که چرا آن فرمولها را انتخاب کرده و متغیرهای مختلف چه معنایی دارند.
ایجاد زنجیره فکری، LLM را مجبور میکند تا تمام محاسبات را انجام دهد که ممکن است منجر به پاسخ صحیحتری شود. علاوه بر این، ایجاد زنجیره فکری کاربر را قادر میسازد تا مراحل LLM را بررسی کند تا مشخص شود که آیا پاسخ منطقی است یا خیر.
چت
محتوای یک گفتگوی رفت و برگشتی با یک سیستم یادگیری ماشینی، معمولاً یک مدل زبانی بزرگ . تعامل قبلی در یک چت (آنچه تایپ کردهاید و نحوه پاسخ مدل زبانی بزرگ) زمینهای برای بخشهای بعدی چت میشود.
یک چتبات (chatbot) کاربردی از یک مدل زبانی بزرگ است.
تعبیه زبان متنی
تعبیهای که به «درک» کلمات و عبارات به شیوهای که گویندگان مسلط انسانی میتوانند، نزدیک میشود. تعبیههای زبانیِ بافتارمحور میتوانند نحو، معناشناسی و بافت پیچیده را درک کنند.
برای مثال، جاسازیهای کلمه انگلیسی cow را در نظر بگیرید. جاسازیهای قدیمیتر مانند word2vec میتوانند کلمات انگلیسی را به گونهای نمایش دهند که فاصله در فضای جاسازی از cow تا bull مشابه فاصله ewe (گوسفند ماده) تا ram (گوسفند نر) یا از ماده تا نر باشد. جاسازیهای زبانیِ بافتدار میتوانند با تشخیص اینکه انگلیسیزبانان گاهی اوقات به طور اتفاقی از کلمه cow به معنای cow یا bull استفاده میکنند، یک قدم فراتر بروند.
پنجره زمینه
تعداد توکنهایی که یک مدل میتواند در یک اعلان داده شده پردازش کند. هرچه پنجره زمینه بزرگتر باشد، مدل میتواند از اطلاعات بیشتری برای ارائه پاسخهای منسجم و سازگار به اعلان استفاده کند.
کدگذاری محاورهای
یک گفتگوی تکراری بین شما و یک مدل هوش مصنوعی مولد به منظور ایجاد نرمافزار. شما یک دستورالعمل ارائه میدهید که برخی از نرمافزارها را توصیف میکند. سپس، مدل از آن توضیحات برای تولید کد استفاده میکند. سپس، شما یک دستورالعمل جدید برای رفع نقصهای دستورالعمل قبلی یا کد تولید شده ارائه میدهید و مدل کد بهروز شده را تولید میکند. شما دو نفر به عقب و جلو میروید تا زمانی که نرمافزار تولید شده به اندازه کافی خوب باشد.
کدگذاری مکالمه اساساً معنای اصلی کدگذاری ارتعاشی است.
با کدگذاری مشخصات مقایسه کنید.
دی
تذکر مستقیم
مترادف برای تحریک بدون هدف (zero-shot prompting ).
تقطیر
فرآیند کاهش اندازه یک مدل (که به عنوان معلم شناخته میشود) به یک مدل کوچکتر (که به عنوان دانشآموز شناخته میشود) که پیشبینیهای مدل اصلی را تا حد امکان با دقت شبیهسازی میکند. تقطیر مفید است زیرا مدل کوچکتر دو مزیت کلیدی نسبت به مدل بزرگتر (معلم) دارد:
- زمان استنتاج سریعتر
- کاهش مصرف حافظه و انرژی
با این حال، پیشبینیهای دانشآموز معمولاً به خوبی پیشبینیهای معلم نیست.
تقطیر، مدل دانشآموز را آموزش میدهد تا یک تابع زیان را بر اساس تفاوت بین خروجیهای پیشبینیهای مدلهای دانشآموز و معلم به حداقل برساند.
تقطیر را با اصطلاحات زیر مقایسه و تضاد کنید:
برای اطلاعات بیشتر به بخش LLM: تنظیم دقیق، خلاصهسازی و مهندسی سریع در دوره فشرده یادگیری ماشین مراجعه کنید.
ای
ارزیابیها
در درجه اول به عنوان مخفف ارزیابیهای LLM استفاده میشود. به طور گستردهتر، evals مخفف هر نوع ارزیابی است.
ارزیابی
فرآیند اندازهگیری کیفیت یک مدل یا مقایسه مدلهای مختلف با یکدیگر.
برای ارزیابی یک مدل یادگیری ماشین تحت نظارت ، معمولاً آن را در برابر یک مجموعه اعتبارسنجی و یک مجموعه تست ارزیابی میکنید. ارزیابی یک LLM معمولاً شامل ارزیابیهای گستردهتر کیفیت و ایمنی است.
ف
واقعیت
در دنیای یادگیری ماشین، ویژگیای که مدلی را توصیف میکند که خروجی آن مبتنی بر واقعیت است. واقعیتگرایی یک مفهوم است نه یک معیار. برای مثال، فرض کنید دستور زیر را به یک مدل زبانی بزرگ ارسال میکنید:
فرمول شیمیایی نمک خوراکی چیست؟
مدلی که واقعیت را بهینه میکند، پاسخ خواهد داد:
نمک طعام
وسوسهانگیز است که فرض کنیم همه مدلها باید مبتنی بر واقعیت باشند. با این حال، برخی از دستورالعملها، مانند موارد زیر، باید باعث شوند که یک مدل هوش مصنوعی مولد، خلاقیت را به جای واقعیت بهینه کند.
یه شعر طنز در مورد یه فضانورد و یه کرم ابریشم بگو.
بعید است که شعر لیمریک حاصل بر اساس واقعیت باشد.
با استواری و ثبات قدم در تضاد است.
پوسیدگی سریع
یک تکنیک آموزشی برای بهبود عملکرد LLMها . کاهش سریع شامل کاهش سریع نرخ یادگیری در طول آموزش است. این استراتژی به جلوگیری از بیشبرازش مدل به دادههای آموزشی کمک میکند و تعمیمپذیری را بهبود میبخشد.
چند شات باعث
یک اعلان که شامل بیش از یک ("چند") مثال است که نحوه پاسخ مدل زبان بزرگ را نشان میدهد. برای مثال، اعلان طولانی زیر شامل دو مثال است که نحوه پاسخ به یک پرسوجو توسط یک مدل زبان بزرگ را نشان میدهد.
| بخشهایی از یک دستورالعمل | یادداشتها |
|---|---|
| واحد پول رسمی کشور مشخص شده چیست؟ | سوالی که میخواهید LLM به آن پاسخ دهد. |
| فرانسه: یورو | یک مثال. |
| بریتانیا: پوند انگلیس | یک مثال دیگر. |
| هند: | پرس و جوی واقعی. |
معمولاً روش ترغیب با تعداد کم، نتایج مطلوبتری نسبت به روشهای ترغیب بدون تعداد و ترغیب یکباره ایجاد میکند. با این حال، روش ترغیب با تعداد کم، به یک روش ترغیب طولانیتر نیاز دارد.
روش هدایت چند مرحلهای، نوعی از یادگیری چند مرحلهای است که در یادگیری مبتنی بر هدایت به کار میرود.
برای اطلاعات بیشتر به دوره فشرده مهندسی سریع در یادگیری ماشین مراجعه کنید.
تنظیم دقیق
یک مرحله آموزشی دوم، مختص به یک وظیفه خاص، که بر روی یک مدل از پیش آموزش دیده انجام میشود تا پارامترهای آن برای یک مورد استفاده خاص اصلاح شود. به عنوان مثال، توالی کامل آموزش برای برخی از مدلهای زبانی بزرگ به شرح زیر است:
- پیشآموزش: یک مدل زبانی بزرگ را روی یک مجموعه داده عمومی وسیع، مانند تمام صفحات ویکیپدیا به زبان انگلیسی، آموزش دهید.
- تنظیم دقیق: مدل از پیش آموزشدیده را برای انجام یک کار خاص ، مانند پاسخ به پرسشهای پزشکی، آموزش دهید. تنظیم دقیق معمولاً شامل صدها یا هزاران مثال متمرکز بر روی یک کار خاص است.
به عنوان مثالی دیگر، توالی کامل آموزش برای یک مدل تصویر بزرگ به شرح زیر است:
- پیشآموزش: یک مدل تصویر بزرگ را روی یک مجموعه داده تصویر عمومی گسترده، مانند تمام تصاویر موجود در ویکیمدیا کامنز، آموزش دهید.
- تنظیم دقیق: مدل از پیش آموزشدیده را برای انجام یک کار خاص ، مانند تولید تصاویر نهنگ قاتل، آموزش دهید.
تنظیم دقیق میتواند شامل ترکیبی از استراتژیهای زیر باشد:
- اصلاح تمام پارامترهای موجود مدل از پیش آموزشدیده. این عمل گاهی اوقات تنظیم دقیق کامل نامیده میشود.
- اصلاح تنها برخی از پارامترهای موجود مدل از پیش آموزشدیده (معمولاً لایههای نزدیک به لایه خروجی )، در حالی که سایر پارامترهای موجود بدون تغییر باقی میمانند (معمولاً لایههای نزدیک به لایه ورودی ). به تنظیم پارامتر-کارآمد مراجعه کنید.
- اضافه کردن لایههای بیشتر، معمولاً روی لایههای موجود نزدیک به لایه خروجی.
تنظیم دقیق نوعی یادگیری انتقالی است. به همین دلیل، تنظیم دقیق ممکن است از یک تابع زیان یا نوع مدل متفاوت از آنچه برای آموزش مدل از پیش آموزش دیده استفاده شده است، استفاده کند. به عنوان مثال، میتوانید یک مدل تصویر بزرگ از پیش آموزش دیده را تنظیم دقیق کنید تا یک مدل رگرسیون تولید کنید که تعداد پرندگان را در یک تصویر ورودی برمیگرداند.
تنظیم دقیق را با اصطلاحات زیر مقایسه و تضاد کنید:
برای اطلاعات بیشتر به دوره فشرده تنظیم دقیق در یادگیری ماشین مراجعه کنید.
مدل فلش
خانوادهای از مدلهای نسبتاً کوچک Gemini که برای سرعت و تأخیر کم بهینه شدهاند. مدلهای Flash برای طیف وسیعی از کاربردها که در آنها پاسخ سریع و توان عملیاتی بالا بسیار مهم است، طراحی شدهاند.
مدل فونداسیون
یک مدل از پیش آموزشدیده بسیار بزرگ که روی یک مجموعه آموزشی عظیم و متنوع آموزش دیده است. یک مدل پایه میتواند هر دو کار زیر را انجام دهد:
- به طیف وسیعی از درخواستها به خوبی پاسخ دهید.
- به عنوان یک مدل پایه برای تنظیم دقیقتر یا سایر سفارشیسازیها عمل میکند.
به عبارت دیگر، یک مدل پایه از قبل به طور کلی بسیار توانمند است، اما میتواند بیشتر سفارشی شود تا برای یک کار خاص مفیدتر شود.
کسری از موفقیتها
معیاری برای ارزیابی متن تولید شده توسط یک مدل یادگیری ماشین. کسر موفقیتها، تعداد خروجیهای متنی تولید شده "موفق" تقسیم بر تعداد کل خروجیهای متنی تولید شده است. برای مثال، اگر یک مدل زبانی بزرگ 10 بلوک کد تولید کند که پنج تای آنها موفق باشند، کسر موفقیتها 50٪ خواهد بود.
اگرچه کسر موفقیتها در آمار بهطور گسترده مفید است، اما در یادگیری ماشین، این معیار در درجه اول برای اندازهگیری وظایف قابل تأیید مانند تولید کد یا مسائل ریاضی مفید است.
جی
جوزا
اکوسیستمی که پیشرفتهترین هوش مصنوعی گوگل را در بر میگیرد. عناصر این اکوسیستم عبارتند از:
- مدلهای مختلف جمینی
- رابط مکالمهای تعاملی برای مدل Gemini. کاربران پیامهایی را تایپ میکنند و Gemini به آنها پاسخ میدهد.
- API های مختلف Gemini.
- محصولات تجاری متنوعی مبتنی بر مدلهای Gemini؛ برای مثال، Gemini برای Google Cloud .
مدلهای جمینی
مدلهای چندوجهی پیشرفته گوگل مبتنی بر Transformer . مدلهای Gemini به طور خاص برای ادغام با عاملها طراحی شدهاند.
کاربران میتوانند از طرق مختلفی با مدلهای Gemini تعامل داشته باشند، از جمله از طریق رابط گفتگوی تعاملی و از طریق SDKها.
جما
خانوادهای از مدلهای باز سبک وزن که از همان تحقیقات و فناوری مورد استفاده برای ایجاد مدلهای Gemini ساخته شدهاند. چندین مدل مختلف Gemma در دسترس است که هر کدام ویژگیهای متفاوتی مانند بینایی، کد و دنبال کردن دستورالعمل را ارائه میدهند. برای جزئیات بیشتر به Gemma مراجعه کنید.
GenAI یا genAI
مخفف هوش مصنوعی مولد (generative AI) است.
متن تولید شده
به طور کلی، متنی که یک مدل یادگیری ماشینی تولید میکند. هنگام ارزیابی مدلهای زبانی بزرگ، برخی معیارها متن تولید شده را با متن مرجع مقایسه میکنند. به عنوان مثال، فرض کنید میخواهید تعیین کنید که یک مدل یادگیری ماشینی چقدر مؤثر از فرانسوی به هلندی ترجمه میکند. در این مورد:
- متن تولید شده، ترجمه هلندی است که مدل ML آن را خروجی میدهد.
- متن مرجع ، ترجمه هلندی است که یک مترجم انسانی (یا نرمافزار) آن را ایجاد میکند.
توجه داشته باشید که برخی از استراتژیهای ارزیابی شامل متن مرجع نمیشوند.
هوش مصنوعی مولد
یک حوزه متحولکننده نوظهور بدون تعریف رسمی. با این حال، اکثر متخصصان موافقند که مدلهای هوش مصنوعی مولد میتوانند محتوایی را ایجاد کنند ("تولید") که همه موارد زیر را داشته باشد:
- پیچیده
- منسجم
- اصلی
نمونههایی از هوش مصنوعی مولد عبارتند از:
- مدلهای زبانی بزرگ ، که میتوانند متن اصلی پیچیده تولید کنند و به سوالات پاسخ دهند.
- مدل تولید تصویر، که میتواند تصاویر منحصر به فردی تولید کند.
- مدلهای تولید صدا و موسیقی، که میتوانند موسیقی اصیل بسازند یا گفتار واقعگرایانه تولید کنند.
- مدلهای تولید ویدیو، که میتوانند ویدیوهای بدیع تولید کنند.
برخی از فناوریهای اولیه، از جمله LSTMها و RNNها ، نیز میتوانند محتوای اصیل و منسجم تولید کنند. برخی از کارشناسان این فناوریهای اولیه را به عنوان هوش مصنوعی مولد میبینند، در حالی که برخی دیگر احساس میکنند که هوش مصنوعی مولد واقعی به خروجی پیچیدهتری نسبت به آنچه فناوریهای اولیه میتوانند تولید کنند، نیاز دارد.
در تضاد با یادگیری ماشینی پیشبینیکننده .
پاسخ طلایی
پاسخی که به عنوان پاسخ خوب شناخته میشود. برای مثال، با توجه به سوال زیر:
۲ + ۲
پاسخ طلایی امیدوارانه این است:
۴
GPT (ترانسفورماتور مولد از پیش آموزشدیده)
خانوادهای از مدلهای زبان بزرگ مبتنی بر Transformer که توسط OpenAI توسعه داده شدهاند.
انواع GPT میتوانند در چندین حالت اعمال شوند، از جمله:
- تولید تصویر (برای مثال، ImageGPT)
- تولید متن به تصویر (برای مثال، DALL-E ).
ح
توهم
تولید خروجی ظاهراً باورپذیر اما در واقع نادرست توسط یک مدل هوش مصنوعی مولد که ادعا میکند در مورد دنیای واقعی ادعایی دارد. به عنوان مثال، یک مدل هوش مصنوعی مولد که ادعا میکند باراک اوباما در سال ۱۸۶۵ درگذشته است، توهمزا است.
ارزیابی انسانی
فرآیندی که در آن افراد کیفیت خروجی یک مدل یادگیری ماشین را قضاوت میکنند؛ برای مثال، قضاوت افراد دوزبانه در مورد کیفیت یک مدل ترجمه یادگیری ماشین. ارزیابی انسانی بهویژه برای قضاوت در مورد مدلهایی که هیچ پاسخ صحیحی ندارند، مفید است.
مقایسه با ارزیابی خودکار و ارزیابی خودکار ارزیاب .
انسان در حلقه (HITL)
اصطلاحی با تعریفی کلی که میتواند به یکی از معانی زیر باشد:
- سیاستی که خروجی هوش مصنوعی مولد را با دید انتقادی یا تردیدآمیز بررسی میکند.
- یک استراتژی یا سیستم برای اطمینان از اینکه افراد به شکلدهی، ارزیابی و اصلاح رفتار یک مدل کمک میکنند. نگه داشتن یک انسان در حلقه، هوش مصنوعی را قادر میسازد تا از هوش ماشینی و هوش انسانی بهرهمند شود. به عنوان مثال، سیستمی که در آن یک هوش مصنوعی کدی را تولید میکند که مهندسان نرمافزار سپس آن را بررسی میکنند، یک سیستم انسان در حلقه است.
من
یادگیری در بافتار
مترادف برای تحریک با چند ضربه .
استنباط
در یادگیری ماشین سنتی، فرآیند انجام پیشبینیها با اعمال یک مدل آموزشدیده بر روی نمونههای بدون برچسب . برای کسب اطلاعات بیشتر به یادگیری نظارتشده در دوره مقدماتی یادگیری ماشین مراجعه کنید.
در مدلهای زبانی بزرگ ، استنتاج فرآیند استفاده از یک مدل آموزشدیده برای تولید پاسخ به یک ورودی فوری است.
استنباط در آمار معنای تا حدودی متفاوتی دارد. برای جزئیات بیشتر به مقاله ویکی پدیا در مورد استنباط آماری مراجعه کنید.
تنظیم دستورالعمل
نوعی تنظیم دقیق که توانایی یک مدل هوش مصنوعی مولد را در دنبال کردن دستورالعملها بهبود میبخشد. تنظیم دستورالعمل شامل آموزش یک مدل بر اساس مجموعهای از دستورالعملهای سریع است که معمولاً طیف گستردهای از وظایف را پوشش میدهند. سپس مدل تنظیمشده بر اساس دستورالعمل حاصل، تمایل به تولید پاسخهای مفید به دستورالعملهای سریع در طیف وسیعی از وظایف دارد.
مقایسه و تطبیق با:
ل
مدل زبان بزرگ
حداقل، یک مدل زبانی با تعداد پارامترهای بسیار بالا. به طور غیررسمیتر، هر مدل زبانی مبتنی بر Transformer ، مانند Gemini یا GPT .
برای اطلاعات بیشتر به بخش مدلهای زبان بزرگ (LLM) در دوره فشرده یادگیری ماشین مراجعه کنید.
تأخیر
زمانی که طول میکشد تا یک مدل ورودی را پردازش کرده و پاسخی تولید کند. تولید یک پاسخ با تأخیر بالا ، نسبت به یک پاسخ با تأخیر کم، زمان بیشتری میبرد.
عواملی که بر تأخیر مدلهای زبانی بزرگ تأثیر میگذارند عبارتند از:
- طول توکنهای ورودی و خروجی
- پیچیدگی مدل
- زیرساختی که مدل روی آن اجرا میشود
بهینهسازی تأخیر برای ایجاد برنامههای واکنشگرا و کاربرپسند بسیار مهم است.
کارشناسی ارشد حقوق
مخفف مدل زبان بزرگ است.
ارزیابیهای LLM (ارزیابیها)
مجموعهای از معیارها و بنچمارکها برای ارزیابی عملکرد مدلهای زبانی بزرگ (LLM). در سطح بالا، ارزیابیهای LLM:
- به محققان کمک کنید تا حوزههایی را که LLMها نیاز به بهبود دارند، شناسایی کنند.
- در مقایسه LLM های مختلف و شناسایی بهترین LLM برای یک کار خاص مفید هستند.
- به اطمینان از ایمن و اخلاقی بودن استفاده از LLM ها کمک کنید.
برای اطلاعات بیشتر به بخش مدلهای زبان بزرگ (LLM) در دوره فشرده یادگیری ماشین مراجعه کنید.
لورا
مخفف سازگاری سطح پایین .
سازگاری رتبه پایین (LoRA)
یک تکنیک پارامتر-کارآمد برای تنظیم دقیق که وزنهای از پیش آموزشدیده مدل را "ثابت" میکند (به طوری که دیگر قابل تغییر نباشند) و سپس مجموعهای کوچک از وزنهای قابل آموزش را در مدل وارد میکند. این مجموعه از وزنهای قابل آموزش (که به عنوان "ماتریسهای بهروزرسانی" نیز شناخته میشوند) به طور قابل توجهی کوچکتر از مدل پایه است و بنابراین آموزش آن بسیار سریعتر است.
LoRA مزایای زیر را ارائه میدهد:
- کیفیت پیشبینیهای مدل را برای دامنهای که تنظیم دقیق در آن اعمال میشود، بهبود میبخشد.
- تنظیم دقیقتر، سریعتر از تکنیکهایی است که نیاز به تنظیم دقیق تمام پارامترهای مدل دارند.
- با فعال کردن امکان ارائه همزمان چندین مدل تخصصی که از یک مدل پایه مشترک استفاده میکنند، هزینه محاسباتی استنتاج را کاهش میدهد.
م
ترجمه ماشینی
استفاده از نرمافزار (معمولاً یک مدل یادگیری ماشین) برای تبدیل متن از یک زبان انسانی به زبان انسانی دیگر، مثلاً از انگلیسی به ژاپنی.
میانگین دقت متوسط در k (mAP@k)
میانگین آماری تمام میانگین دقتها در k در یک مجموعه داده اعتبارسنجی. یکی از کاربردهای میانگین میانگین دقت در k، قضاوت در مورد کیفیت توصیههای تولید شده توسط یک سیستم توصیهگر است.
اگرچه عبارت «میانگین میانگین» تکراری به نظر میرسد، اما نام این معیار مناسب است. گذشته از همه اینها، این معیار میانگین دقت چندین میانگین را در k مقدار پیدا میکند.
ترکیبی از متخصصان
طرحی برای افزایش کارایی شبکه عصبی با استفاده از تنها زیرمجموعهای از پارامترهای آن (که به عنوان متخصص شناخته میشود) برای پردازش یک نشانه یا مثال ورودی معین. یک شبکه دروازهای، هر نشانه یا مثال ورودی را به متخصص(های) مناسب هدایت میکند.
برای جزئیات، به یکی از مقالات زیر مراجعه کنید:
- شبکههای عصبی فوقالعاده بزرگ: لایه ترکیبی از متخصصان با دروازههای پراکنده
- ترکیبی از متخصصان با مسیریابی Expert Choice
ام ام آی تی
مخفف عبارت multimodal instruction-tuned (تنظیمشده با دستورالعمل چندوجهی) است.
مدل آبشاری
سیستمی که مدل ایدهآل را برای یک پرسوجوی استنتاجی خاص انتخاب میکند.
گروهی از مدلها را تصور کنید، از مدلهای بسیار بزرگ (با پارامترهای زیاد) تا مدلهای بسیار کوچکتر (با پارامترهای بسیار کمتر). مدلهای بسیار بزرگ در زمان استنتاج ، منابع محاسباتی بیشتری نسبت به مدلهای کوچکتر مصرف میکنند. با این حال، مدلهای بسیار بزرگ معمولاً میتوانند درخواستهای پیچیدهتری را نسبت به مدلهای کوچکتر استنتاج کنند. آبشاریسازی مدل، پیچیدگی پرسوجوی استنتاج را تعیین میکند و سپس مدل مناسب را برای انجام استنتاج انتخاب میکند. انگیزه اصلی آبشاریسازی مدل، کاهش هزینههای استنتاج با انتخاب مدلهای کوچکتر و انتخاب تنها یک مدل بزرگتر برای پرسوجوهای پیچیدهتر است.
تصور کنید که یک مدل کوچک روی یک تلفن اجرا میشود و نسخه بزرگتری از آن مدل روی یک سرور از راه دور اجرا میشود. آبشاری کردن مدل خوب، با قادر ساختن مدل کوچکتر برای رسیدگی به درخواستهای ساده و فراخوانی مدل از راه دور فقط برای رسیدگی به درخواستهای پیچیده، هزینه و تأخیر را کاهش میدهد.
همچنین به مدل روتر مراجعه کنید.
مدل روتر
الگوریتمی که مدل ایدهآل برای استنتاج در آبشاری کردن مدل را تعیین میکند. یک روتر مدل، خود معمولاً یک مدل یادگیری ماشین است که به تدریج یاد میگیرد چگونه بهترین مدل را برای یک ورودی مشخص انتخاب کند. با این حال، یک روتر مدل گاهی اوقات میتواند یک الگوریتم سادهتر و غیر یادگیری ماشینی باشد.
وزارت آموزش و پرورش
مخفف ترکیبی از متخصصان .
تن
مخفف ترجمه ماشینی است.
ن
نانو
یک مدل نسبتاً کوچک Gemini که برای استفاده روی دستگاه طراحی شده است. برای جزئیات بیشتر به Gemini Nano مراجعه کنید.
همچنین به نسخههای پرو و اولترا مراجعه کنید.
هیچ کس جواب درست نداد (نورا)
سوالی که چندین پاسخ صحیح دارد. برای مثال، سوال زیر هیچ پاسخ صحیحی ندارد:
یه جوک بامزه در مورد فیلها بگو.
ارزیابی پاسخها به سوالاتی که هیچ پاسخ درستی ندارند، معمولاً بسیار ذهنیتر از ارزیابی سوالاتی با یک پاسخ درست است. برای مثال، ارزیابی یک جوک در مورد فیل نیاز به یک روش سیستماتیک برای تعیین میزان خندهدار بودن آن دارد.
نورا
مخفف « هیچکس جواب درست نمیدهد ».
نوت بوک LM
ابزاری مبتنی بر Gemini که به کاربران امکان میدهد اسناد را بارگذاری کنند و سپس از دستورالعملها برای پرسیدن سؤال در مورد، خلاصه کردن یا سازماندهی آن اسناد استفاده کنند. به عنوان مثال، یک نویسنده میتواند چندین داستان کوتاه را بارگذاری کند و از Notebook LM بخواهد که مضامین مشترک آنها را پیدا کند یا مشخص کند که کدام یک بهترین فیلم را میسازد.
ای
یک پاسخ درست (ORA)
سوالی که فقط یک پاسخ صحیح دارد. برای مثال، سوال زیر را در نظر بگیرید:
درست یا غلط: زحل از مریخ بزرگتر است.
تنها پاسخ صحیح، حقیقت است.
در مقابل، هیچکس پاسخ درست نمیدهد .
راهنمایی تک مرحلهای
یک اعلان که شامل یک مثال است که نحوه پاسخگویی مدل زبان بزرگ را نشان میدهد. برای مثال، اعلان زیر شامل یک مثال است که نحوه پاسخگویی یک مدل زبان بزرگ به یک پرسوجو را نشان میدهد.
| بخشهایی از یک دستورالعمل | یادداشتها |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| France: EUR | One example. |
| India: | The actual query. |
Compare and contrast one-shot prompting with the following terms:
اورا
Abbreviation for one right answer .
پ
parameter-efficient tuning
A set of techniques to fine-tune a large pre-trained language model (PLM) more efficiently than full fine-tuning . Parameter-efficient tuning typically fine-tunes far fewer parameters than full fine-tuning, yet generally produces a large language model that performs as well (or almost as well) as a large language model built from full fine-tuning.
Compare and contrast parameter-efficient tuning with:
Parameter-efficient tuning is also known as parameter-efficient fine-tuning .
Pax
A programming framework designed for training large-scale neural network models so large that they span multiple TPU accelerator chip slices or pods .
Pax is built on Flax , which is built on JAX .

PLM
Abbreviation for pre-trained language model .
post-trained model
Loosely-defined term that typically refers to a pre-trained model that has gone through some post-processing, such as one or more of the following:
pre-trained model
Although this term could refer to any trained model or trained embedding vector , pre-trained model now typically refers to a trained large language model or other form of trained generative AI model.
See also base model and foundation model .
pre-training
The initial training of a model on a large dataset . Some pre-trained models are clumsy giants and must typically be refined through additional training. For example, ML experts might pre-train a large language model on a vast text dataset, such as all the English pages in Wikipedia. Following pre-training, the resulting model might be further refined through any of the following techniques:
حرفهای
A Gemini model with fewer parameters than Ultra but more parameters than Nano . See Gemini Pro for details.
سریع
Any text entered as input to a large language model to condition the model to behave in a certain way. Prompts can be as short as a phrase or arbitrarily long (for example, the entire text of a novel). Prompts fall into multiple categories, including those shown in the following table:
| Prompt category | مثال | یادداشتها |
|---|---|---|
| سوال | How fast can a pigeon fly? | |
| دستورالعمل | Write a funny poem about arbitrage. | A prompt that asks the large language model to do something. |
| مثال | Translate Markdown code to HTML. For example: Markdown: * list item HTML: <ul> <li>list item</li> </ul> | The first sentence in this example prompt is an instruction. The remainder of the prompt is the example. |
| نقش | Explain why gradient descent is used in machine learning training to a PhD in Physics. | The first part of the sentence is an instruction; the phrase "to a PhD in Physics" is the role portion. |
| Partial input for the model to complete | The Prime Minister of the United Kingdom lives at | A partial input prompt can either end abruptly (as this example does) or end with an underscore. |
A generative AI model can respond to a prompt with text, code, images, embeddings , videos…almost anything.
prompt-based learning
A capability of certain models that enables them to adapt their behavior in response to arbitrary text input ( prompts ). In a typical prompt-based learning paradigm, a large language model responds to a prompt by generating text. For example, suppose a user enters the following prompt:
Summarize Newton's Third Law of Motion.
A model capable of prompt-based learning isn't specifically trained to answer the previous prompt. Rather, the model "knows" a lot of facts about physics, a lot about general language rules, and a lot about what constitutes generally useful answers. That knowledge is sufficient to provide a (hopefully) useful answer. Additional human feedback ("That answer was too complicated." or "What's a reaction?") enables some prompt-based learning systems to gradually improve the usefulness of their answers.
prompt design
Synonym for prompt engineering .
مهندسی سریع
The art of creating prompts that elicit the desired responses from a large language model . Humans perform prompt engineering. Writing well-structured prompts is an essential part of ensuring useful responses from a large language model. Prompt engineering depends on many factors, including:
- The dataset used to pre-train and possibly fine-tune the large language model.
- The temperature and other decoding parameters that the model uses to generate responses.
Prompt design is a synonym for prompt engineering.
See Introduction to prompt design for more details on writing helpful prompts.
prompt set
A group of prompts for evaluating a large language model . For example, the following illustration shows a prompt set consisting of three prompts:
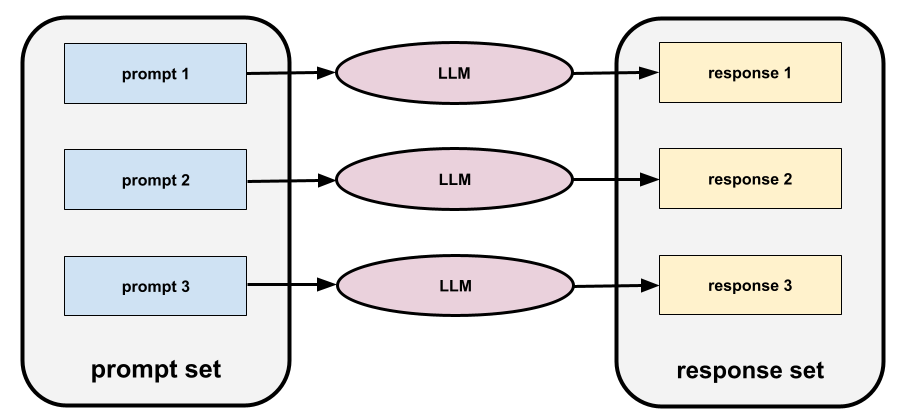
Good prompt sets consist of a sufficiently "wide" collection of prompts to thoroughly evaluate the safety and helpfulness of a large language model.
See also response set .
prompt tuning
A parameter efficient tuning mechanism that learns a "prefix" that the system prepends to the actual prompt .
One variation of prompt tuning—sometimes called prefix tuning —is to prepend the prefix at every layer . In contrast, most prompt tuning only adds a prefix to the input layer .
ر
reference text
An expert's response to a prompt . For example, given the following prompt:
Translate the question "What is your name?" from English to French.
An expert's response might be:
Comment vous appelez-vous?
Various metrics (such as ROUGE ) measure the degree to which the reference text matches an ML model's generated text .
بازتاب
A strategy for improving the quality of an agentic workflow by examining (reflecting on) a step's output before passing that output to the next step.
The examiner is often the same LLM that generated the response (though it could be a different LLM). How could the same LLM that generated a response be a fair judge of its own response? The "trick" is to put the LLM in a critical (reflective) mindset. This process is analogous to a writer who uses a creative mindset to write a first draft and then switches to a critical mindset to edit it.
For example, imagine an agentic workflow whose first step is to create text for coffee mugs. The prompt for this step might be:
You are a creative. Generate humorous, original text of less than 50 characters suitable for a coffee mug.
Now imagine the following reflective prompt:
You are a coffee drinker. Would you find the preceding response humorous?
The workflow might then only pass text that receives a high reflection score to the next stage.
Reinforcement Learning from Human Feedback (RLHF)
Using feedback from human raters to improve the quality of a model's responses . For example, an RLHF mechanism can ask users to rate the quality of a model's response with a 👍 or 👎 emoji. The system can then adjust its future responses based on that feedback.
پاسخ
The text, images, audio, or video that a generative AI model infers . In other words, a prompt is the input to a generative AI model and the response is the output .
response set
The collection of responses a large language model returns to an input prompt set .
role prompting
A prompt , typically beginning with the pronoun you , that tells a generative AI model to pretend to be a certain person or a certain role when generating the response . Role prompting can help a generative AI model get into the right "mindset" in order to generate a more useful response. For example, any of the following role prompts might be appropriate depending on the kind of response you are seeking:
You have a PhD in computer science.
You are a software engineer who enjoys giving patient explanations about Python to new programming students.
You are an action hero with a very particular set of programming skills. Assure me that you will find a particular item in a Python list.
س
soft prompt tuning
A technique for tuning a large language model for a particular task, without resource intensive fine-tuning . Instead of retraining all the weights in the model, soft prompt tuning automatically adjusts a prompt to achieve the same goal.
Given a textual prompt, soft prompt tuning typically appends additional token embeddings to the prompt and uses backpropagation to optimize the input.
A "hard" prompt contains actual tokens instead of token embeddings.
specificational coding
The process of writing and maintaining a file in a human language (for example, English) that describes software. You can then tell a generative AI model or another software engineer to create the software that fulfills that description.
Automatically-generated code generally requires iteration. In specificational coding, you iterate on the description file. By contrast, in conversational coding , you iterate within the prompt box. In practice, automatic code generation sometimes involves a combination of both specificational coding and conversational coding.
تی
دما
A hyperparameter that controls the degree of randomness of a model's output. Higher temperatures result in more random output, while lower temperatures result in less random output.
Choosing the best temperature depends on the specific application and or string values.
یو
فوق العاده
The Gemini model with the most parameters . See Gemini Ultra for details.
پنجم
ورتکس
Google Cloud's platform for AI and machine learning. Vertex provides tools and infrastructure for building, deploying, and managing AI applications, including access to Gemini models.vibe coding
Prompting a generative AI model to create software. That is, your prompts describe the software's purpose and features, which a generative AI model translates into source code. The generated code doesn't always match your intentions, so vibe coding usually requires iteration.
Andrej Karpathy coined the term vibe coding in this X post . In the X post, Karpathy describes it as "a new kind of coding...where you fully give in to the vibes..." So, the term originally implied an intentionally loose approach to creating software in which you might not even examine the generated code. However, the term has rapidly evolved in many circles to now mean any form of AI-generated coding.
For a more detailed description of vibe coding, seeWhat is vibe coding? .
In addition, compare and contrast vibe coding with:
ز
zero-shot prompting
A prompt that does not provide an example of how you want the large language model to respond. For example:
| Parts of one prompt | یادداشتها |
|---|---|
| What is the official currency of the specified country? | The question you want the LLM to answer. |
| India: | The actual query. |
The large language model might respond with any of the following:
- روپیه
- روپیه هند
- ₹
- Indian rupee
- The rupee
- The Indian rupee
All of the answers are correct, though you might prefer a particular format.
Compare and contrast zero-shot prompting with the following terms: