"همه مدل ها اشتباه هستند، اما برخی از آنها مفید هستند." - جورج باکس، 1978
اگرچه تکنیک های آماری قدرتمند، محدودیت های خود را دارند. درک این محدودیتها میتواند به محقق کمک کند تا از گافها و ادعاهای نادرست اجتناب کند، مانند ادعای بیاف اسکینر مبنی بر اینکه شکسپیر بیش از پیشبینی تصادفی از همسانسازی استفاده نکرده است. (مطالعه اسکینر ضعیف بود. 1 )
نوارهای عدم قطعیت و خطا
مهم است که عدم قطعیت را در تحلیل خود مشخص کنید. به همان اندازه مهم است که عدم قطعیت در تحلیل های دیگران را تعیین کنیم. نقاط داده ای که به نظر می رسد روندی را روی یک نمودار ترسیم می کنند، اما دارای نوارهای خطای همپوشانی هستند، ممکن است به هیچ وجه نشان دهنده هیچ الگوی نباشند. همچنین ممکن است عدم قطعیت برای نتیجه گیری مفید از یک مطالعه یا آزمون آماری خاص بسیار زیاد باشد. اگر یک مطالعه تحقیقاتی به دقت در سطح زیادی نیاز داشته باشد، یک مجموعه داده جغرافیایی با +/- 500 متر عدم قطعیت دارای عدم قطعیت زیادی است که قابل استفاده نیست.
از طرف دیگر، سطوح عدم قطعیت ممکن است در طول فرآیندهای تصمیم گیری مفید باشد. داده هایی که از یک تصفیه آب خاص با 20 درصد عدم قطعیت در نتایج پشتیبانی می کنند، ممکن است به توصیه ای برای اجرای آن تصفیه آب با نظارت مستمر برنامه برای رسیدگی به این عدم قطعیت منجر شود.
شبکههای عصبی بیزی میتوانند عدم قطعیت را با پیشبینی توزیع مقادیر به جای مقادیر منفرد تعیین کنند.
بی ربط بودن
همانطور که در مقدمه بحث شد، همیشه حداقل یک شکاف کوچک بین داده ها و واقعیت وجود دارد. پزشک زیرک ML باید مشخص کند که آیا مجموعه داده با سؤال مطرح شده مرتبط است یا خیر.
هاف یک مطالعه اولیه افکار عمومی را توصیف می کند که نشان می دهد پاسخ سفیدپوستان آمریکایی به این سوال که چقدر برای سیاهپوستان آمریکایی آسان است زندگی خوبی داشته باشند، به طور مستقیم و معکوس با سطح همدردی آنها با سیاهپوستان آمریکایی مرتبط است. با افزایش دشمنی نژادی، پاسخ ها در مورد فرصت های اقتصادی مورد انتظار بیشتر و بیشتر خوش بینانه شد. این ممکن است به عنوان نشانه ای از پیشرفت اشتباه درک شود. با این حال، این مطالعه نمیتوانست چیزی در مورد فرصتهای اقتصادی واقعی موجود برای سیاهپوستان آمریکایی در آن زمان نشان دهد، و برای نتیجهگیری در مورد واقعیت بازار کار - فقط نظرات پاسخدهندگان در نظرسنجی - مناسب نبود. داده های جمع آوری شده در واقع بی ربط به وضعیت بازار کار بود. 2
می توانید مدلی را بر روی داده های نظرسنجی مانند آنچه در بالا توضیح داده شد آموزش دهید، که در آن خروجی در واقع خوش بینی را به جای فرصت اندازه گیری می کند. اما از آنجایی که فرصتهای پیشبینیشده به فرصتهای واقعی بیربط هستند، اگر ادعا میکنید که این مدل فرصتهای واقعی را پیشبینی میکند، آنچه را که مدل پیشبینی میکند اشتباه نشان میدهید.
گیج می کند
متغیر مخدوش کننده ، مخدوش کننده یا کوفاکتور متغیری است که در حال مطالعه نیست و بر متغیرهای تحت مطالعه تأثیر می گذارد و ممکن است نتایج را مخدوش کند. به عنوان مثال، یک مدل ML را در نظر بگیرید که نرخ مرگ و میر را برای یک کشور ورودی بر اساس ویژگی های سیاست بهداشت عمومی پیش بینی می کند. فرض کنید که میانگین سنی یک ویژگی نیست. علاوه بر این، فرض کنید برخی از کشورها جمعیت مسنتری نسبت به سایرین دارند. با نادیده گرفتن متغیر مداخله گر سن متوسط، این مدل ممکن است نرخ مرگ و میر معیوب را پیش بینی کند.
در ایالات متحده، نژاد اغلب به شدت با طبقه اجتماعی-اقتصادی همبستگی دارد، اگرچه فقط نژاد، و نه طبقه، با داده های مرگ و میر ثبت می شود. آشفتگی های مربوط به طبقات، مانند دسترسی به مراقبت های بهداشتی، تغذیه، کار خطرناک و مسکن ایمن، ممکن است تأثیر قوی تری بر میزان مرگ و میر نسبت به نژاد داشته باشند، اما به دلیل اینکه در مجموعه داده ها گنجانده نشده اند، نادیده گرفته می شوند. 3 شناسایی و کنترل این آشفتگیها برای ساخت مدلهای مفید و نتیجهگیری معنادار و دقیق بسیار مهم است.
اگر مدلی بر اساس دادههای مرگومیر موجود، که شامل نژاد است، اما نه کلاس، آموزش دیده باشد، ممکن است مرگومیر را بر اساس نژاد پیشبینی کند، حتی اگر کلاس پیشبینیکننده قویتری برای مرگومیر باشد. این می تواند منجر به فرضیات نادرست در مورد علیت و پیش بینی های نادرست در مورد مرگ و میر بیماران شود. شاغلین ML باید بپرسند که آیا در داده های آنها آشفتگی وجود دارد و همچنین چه متغیرهای معناداری ممکن است در مجموعه داده آنها وجود نداشته باشد.
در سال 1985، مطالعه سلامت پرستاران، یک مطالعه کوهورت مشاهدهای از دانشکده پزشکی هاروارد و دانشکده بهداشت عمومی هاروارد، نشان داد که اعضای گروهی که درمان جایگزینی استروژن دریافت میکنند، در مقایسه با اعضای گروهی که هرگز استروژن مصرف نکردهاند، کمتر دچار حملات قلبی میشوند. در نتیجه، پزشکان برای چندین دهه برای بیماران یائسه و یائسه خود استروژن تجویز کردند تا اینکه یک مطالعه بالینی در سال 2002 خطرات سلامتی ناشی از استروژن درمانی طولانی مدت را شناسایی کرد. تجویز استروژن برای زنان یائسه متوقف شد، اما نه قبل از اینکه باعث مرگ زودرس ده ها هزار نفر شود.
سردرگمی های متعدد می توانست باعث ایجاد ارتباط شود. اپیدمیولوژیست ها دریافتند که زنانی که از درمان جایگزینی هورمون استفاده می کنند، در مقایسه با زنانی که این کار را نمی کنند، لاغرتر، تحصیلکرده تر، ثروتمندتر، آگاه تر از سلامتی خود و بیشتر ورزش می کنند. در مطالعات مختلف مشخص شد که تحصیلات و ثروت خطر ابتلا به بیماری قلبی را کاهش می دهد. این اثرات ممکن است ارتباط آشکار بین استروژن درمانی و حملات قلبی را مخدوش کند. 4
درصدهایی با اعداد منفی
در صورت وجود اعداد منفی، از استفاده از درصد خودداری کنید، زیرا 5 می تواند سود و زیان معنی دار را پنهان کند. برای ریاضی ساده فرض کنید صنعت رستوران داری 2 میلیون شغل دارد. اگر صنعت 1 میلیون نفر از این مشاغل را در اواخر مارس 2020 از دست بدهد، به مدت ده ماه هیچ تغییر خالصی را تجربه نکند و در اوایل فوریه 2021، 900000 شغل به دست آورد، مقایسه سال به سال در اوایل مارس 2021 تنها 5 درصد از دست دادن مشاغل رستوران را نشان می دهد. با فرض عدم تغییر دیگر، مقایسه سال به سال در پایان آوریل 2021 نشان دهنده افزایش 90 درصدی مشاغل رستوران است که تصویر بسیار متفاوتی از واقعیت است.
اعداد واقعی را ترجیح دهید، در صورت لزوم نرمال شده باشند. برای اطلاعات بیشتر به کار با داده های عددی مراجعه کنید.
مغالطه پسا هوک و همبستگی های غیرقابل استفاده
مغالطه پسا هوک این فرض است که، چون رویداد A با رویداد B همراه شد، رویداد A باعث رویداد B شد. به بیان ساده تر، فرض یک رابطه علت و معلولی در جایی است که یکی وجود ندارد. حتی ساده تر: همبستگی ها علیت را اثبات نمی کنند.
علاوه بر یک رابطه علت و معلولی واضح، همبستگی ها می توانند از موارد زیر نیز ناشی شوند:
- شانس محض (برای مثالها به همبستگیهای جعلی تایلر ویگن، از جمله همبستگی قوی بین میزان طلاق در مین و مصرف مارگارین مراجعه کنید).
- یک رابطه واقعی بین دو متغیر، اگرچه هنوز مشخص نیست که کدام متغیر مسبب است و کدام یک متأثر است.
- سومین علت مجزا که بر هر دو متغیر تأثیر می گذارد، اگرچه متغیرهای همبسته با یکدیگر ارتباطی ندارند. برای مثال تورم جهانی می تواند قیمت هر دو قایق تفریحی و کرفس را افزایش دهد. 6
همچنین برون یابی یک همبستگی گذشته از داده های موجود خطرناک است. هاف اشاره می کند که مقداری باران باعث بهبود محصولات می شود، اما باران زیاد به آنها آسیب می رساند. رابطه بین نتایج باران و محصول غیرخطی است. 7 (برای اطلاعات بیشتر در مورد روابط غیرخطی به دو بخش بعدی مراجعه کنید.) جونز خاطرنشان می کند که جهان پر از رویدادهای غیرقابل پیش بینی است، مانند جنگ و قحطی، که پیش بینی های آینده داده های سری زمانی را در معرض مقادیر زیادی از عدم قطعیت قرار می دهد. 8
علاوه بر این، حتی یک همبستگی واقعی بر اساس علت و معلول ممکن است برای تصمیم گیری مفید نباشد. هاف، به عنوان مثال، همبستگی بین ازدواج پذیری و تحصیلات دانشگاهی در دهه 1950 را بیان می کند. زنانی که به دانشگاه میرفتند کمتر احتمال داشت ازدواج کنند، اما میتوانست اینطور باشد که زنانی که به دانشگاه میرفتند در ابتدا تمایل کمتری به ازدواج داشتند. اگر اینطور بود، تحصیلات دانشگاهی احتمال ازدواج آنها را تغییر نداد. 9
اگر یک تحلیل همبستگی بین دو متغیر در یک مجموعه داده را تشخیص داد، بپرسید:
- چه نوع همبستگی است: علت و معلول، رابطه جعلی، ناشناخته، یا ناشی از متغیر سوم؟
- برون یابی از داده ها چقدر خطرناک است؟ هر پیشبینی مدل بر روی دادههایی که در مجموعه داده آموزشی نیستند، در واقع درونیابی یا برونیابی از دادهها است.
- آیا می توان از همبستگی برای تصمیم گیری مفید استفاده کرد؟ به عنوان مثال، خوشبینی میتواند به شدت با افزایش دستمزدها مرتبط باشد، اما تجزیه و تحلیل احساسات مجموعه بزرگی از دادههای متنی، مانند پستهای رسانههای اجتماعی توسط کاربران در یک کشور خاص، برای پیشبینی افزایش دستمزدها در آن کشور مفید نخواهد بود.
هنگام آموزش یک مدل، پزشکان ML عموماً به دنبال ویژگی هایی هستند که به شدت با برچسب مرتبط هستند. اگر رابطه بین ویژگیها و برچسب به خوبی درک نشده باشد، این میتواند منجر به مشکلاتی شود که در این بخش توضیح داده شده است، از جمله مدلهای مبتنی بر همبستگیهای جعلی و مدلهایی که فرض میکنند روندهای تاریخی در آینده ادامه خواهند داشت، در حالی که در واقع اینطور نیست.
تعصب خطی
بارت دی لانگه، استفانو پانتونی و ریچارد لاریک در «تفکر خطی در دنیای غیرخطی»، سوگیری خطی را تمایل مغز انسان به انتظار و جستجوی روابط خطی توصیف میکنند، اگرچه بسیاری از پدیدهها غیرخطی هستند. برای مثال، رابطه بین نگرش و رفتار انسان، یک منحنی محدب است و نه یک خط. در مقاله ای در سال 2007 در مجله سیاست مصرف کننده به نقل از دی لانگه و همکاران، جنی ون دورن و همکاران. رابطه بین نگرانی پاسخ دهندگان نظرسنجی در مورد محیط زیست و خرید پاسخ دهندگان از محصولات ارگانیک را مدل کرد. کسانی که شدیدترین نگرانی ها را در مورد محیط زیست داشتند، محصولات ارگانیک بیشتری خریدند، اما تفاوت بسیار کمی بین سایر پاسخ دهندگان وجود داشت.
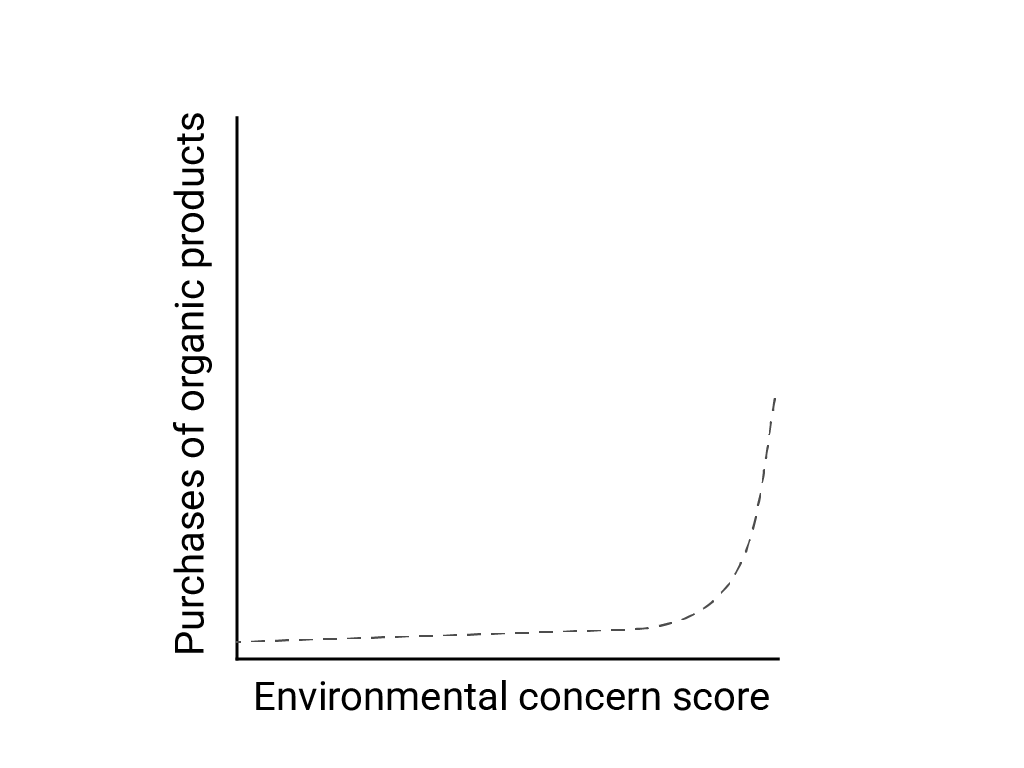
هنگام طراحی مدل ها یا مطالعات، امکان روابط غیرخطی را در نظر بگیرید. از آنجایی که آزمایش A/B ممکن است روابط غیرخطی را از دست بدهد، یک شرط سوم و میانی، C را نیز در نظر بگیرید. همچنین در نظر بگیرید که آیا رفتار اولیه که خطی به نظر می رسد خطی خواهد بود یا اینکه داده های آینده ممکن است رفتار لگاریتمی یا رفتار غیرخطی دیگری را نشان دهند.
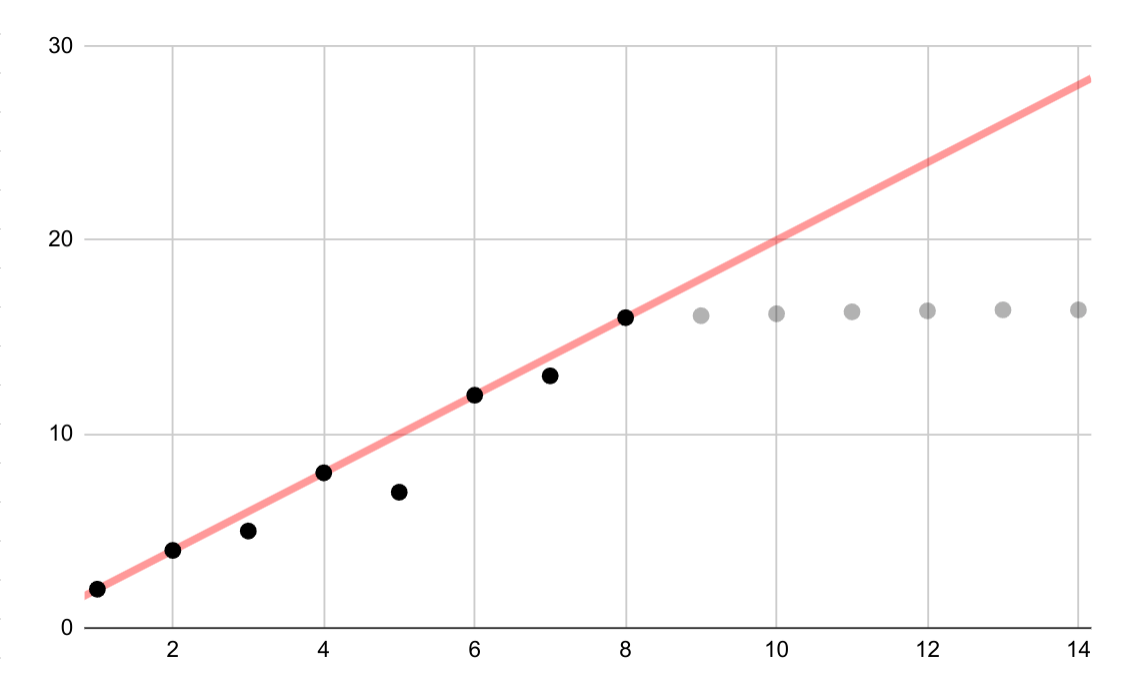
این مثال فرضی یک تناسب خطی اشتباه برای داده های لگاریتمی را نشان می دهد. اگر فقط چند نقطه داده اول در دسترس بود، فرض یک رابطه خطی مداوم بین متغیرها هم وسوسه انگیز و هم نادرست بود.
درون یابی خطی
هر گونه درونیابی بین نقاط داده را بررسی کنید، زیرا درون یابی نقاط خیالی را معرفی می کند و فواصل بین اندازه گیری های واقعی ممکن است دارای نوسانات معنی دار باشد. به عنوان مثال، تجسم زیر را از چهار نقطه داده مرتبط با درون یابی خطی در نظر بگیرید:

سپس این مثال از نوسانات بین نقاط داده را که با درون یابی خطی پاک می شوند در نظر بگیرید:
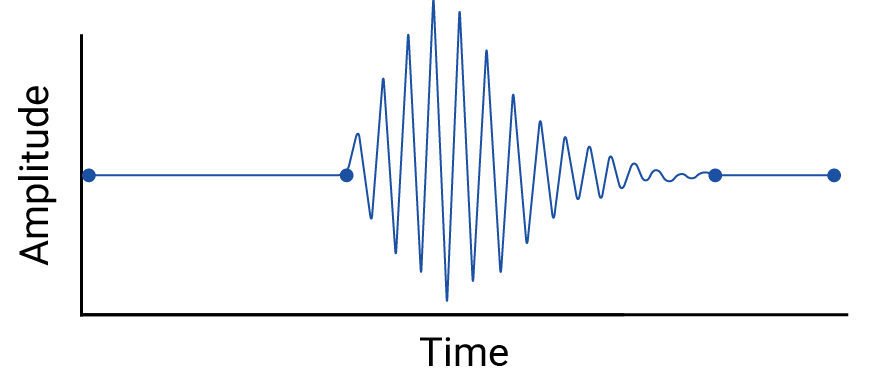
این مثال به این دلیل ساخته شده است که لرزه نگارها داده های پیوسته را جمع آوری می کنند و بنابراین این زلزله از دست نمی رود. اما برای نشان دادن مفروضات ایجاد شده توسط درون یابی ها و پدیده های واقعی که متخصصان داده ممکن است از دست بدهند مفید است.
پدیده رانگ
پدیده رانگ ، که به عنوان "تکان چند جمله ای" نیز شناخته می شود، مشکلی است که در انتهای طیف از درون یابی خطی و بایاس خطی قرار دارد. هنگامی که یک درونیابی چند جمله ای را به داده ها برازش می کنیم، می توان از یک چند جمله ای با درجه بسیار بالا (درجه یا مرتبه، که بالاترین توان در معادله چند جمله ای است) استفاده کرد. این باعث ایجاد نوسانات عجیب و غریب در لبه ها می شود. به عنوان مثال، اعمال درون یابی چند جمله ای درجه 11، به این معنی که عبارت با بالاترین مرتبه در معادله چند جمله ای دارای \(x^{11}\)، به داده های تقریباً خطی، منجر به پیش بینی های بسیار بدی در ابتدا و انتهای دامنه داده ها می شود:
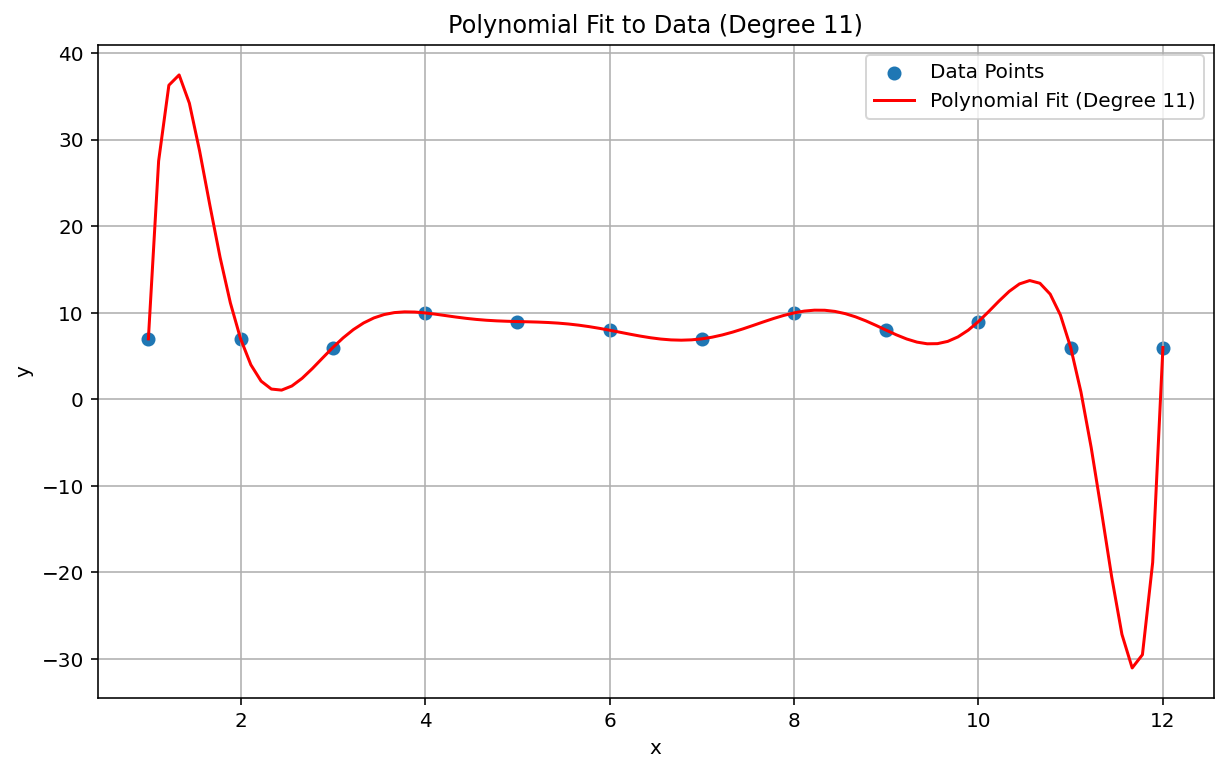
در زمینه ML، یک پدیده مشابه بیش از حد مناسب است.
شکست های آماری برای شناسایی
گاهی اوقات ممکن است یک آزمون آماری برای تشخیص یک اثر کوچک بسیار ضعیف باشد. قدرت پایین در تجزیه و تحلیل آماری به معنای شانس کم برای شناسایی صحیح رویدادهای واقعی و در نتیجه احتمال بالای منفی کاذب است. کاترین باتن و همکاران در Nature نوشت: "وقتی مطالعات در یک زمینه معین با توان 20٪ طراحی می شود، به این معنی است که اگر 100 اثر غیر پوچ واقعی در آن زمینه کشف شود، انتظار می رود این مطالعات تنها 20 مورد از آنها را کشف کنند." افزایش حجم نمونه گاهی اوقات می تواند کمک کند، همانطور که طراحی دقیق مطالعه می تواند کمک کننده باشد.
یک وضعیت مشابه در ML مشکل طبقه بندی و انتخاب آستانه طبقه بندی است. انتخاب آستانه بالاتر منجر به مثبت کاذب کمتر و منفی کاذب بیشتر می شود، در حالی که آستانه پایین تر منجر به مثبت کاذب بیشتر و منفی کاذب کمتر می شود.
علاوه بر مسائل مربوط به قدرت آماری، از آنجایی که همبستگی برای تشخیص روابط خطی طراحی شده است، می توان همبستگی غیرخطی بین متغیرها را از دست داد. به طور مشابه، متغیرها می توانند با یکدیگر مرتبط باشند اما از نظر آماری همبستگی ندارند. متغیرها همچنین میتوانند همبستگی منفی داشته باشند اما کاملاً نامرتبط باشند، در آنچه به عنوان پارادوکس برکسون یا مغالطه برکسون شناخته میشود. مثال کلاسیک مغالطه برکسون، همبستگی منفی کاذب بین هر عامل خطر و بیماری شدید هنگام نگاه کردن به جمعیت بستری در بیمارستان (در مقایسه با جمعیت عمومی) است که از فرآیند انتخاب ناشی میشود (شرایطی به اندازهای شدید که نیاز به بستری شدن در بیمارستان دارد).
در نظر بگیرید که آیا هر یک از این شرایط اعمال می شود یا خیر.
مدل های قدیمی و فرضیات نامعتبر
حتی مدلهای خوب نیز میتوانند در طول زمان تنزل پیدا کنند، زیرا ممکن است رفتار (و جهان، در این مورد) تغییر کند. مدلهای پیشبینی اولیه نتفلیکس باید بازنشسته میشد، زیرا پایگاه مشتریان آنها از کاربران جوان و آگاه به فناوری به جمعیت عمومی تغییر میکرد. 10
مدلها همچنین میتوانند حاوی مفروضات بیصدا و نادرستی باشند که ممکن است تا شکست فاجعهبار مدل، مانند سقوط بازار در سال 2008، پنهان بماند. مدلهای ارزش در معرض ریسک (VaR) صنعت مالی ادعا میکنند که حداکثر زیان در سبد هر معاملهگری را دقیقاً تخمین میزنند، میگویند حداکثر ضرر ۱۰۰۰۰۰ دلاری در ۹۹ درصد مواقع انتظار میرود. اما در شرایط غیرعادی سقوط، یک سبد با حداکثر زیان مورد انتظار 100،000 دلار ، گاهی اوقات 1،000،000 دلار یا بیشتر از دست داده است.
مدلهای VaR مبتنی بر مفروضات معیوب هستند، از جمله موارد زیر:
- تغییرات بازار گذشته پیش بینی کننده تغییرات بازار آینده است.
- توزیع نرمال (دم نازک و در نتیجه قابل پیش بینی) زیربنای بازده های پیش بینی شده بود.
در واقع، توزیع زیربنایی دم چربی، "وحشی" یا فراکتال بود، به این معنی که خطر بسیار بالاتری از رویدادهای دم بلند، شدید و ظاهراً نادر نسبت به پیش بینی توزیع عادی وجود داشت. ماهیت دم چربی توزیع واقعی به خوبی شناخته شده بود، اما به آن عمل نشد. چیزی که کمتر شناخته شده بود این بود که پدیده های مختلف تا چه حد پیچیده و محکم هستند، از جمله تجارت مبتنی بر کامپیوتر با فروش خودکار. 11
مسائل تجمیع
داده هایی که تجمیع می شوند، که شامل بیشتر داده های جمعیت شناختی و اپیدمیولوژیک می شود، در معرض مجموعه خاصی از تله ها قرار می گیرند. پارادوکس سیمپسون ، یا پارادوکس ادغام ، در دادههای انباشته رخ میدهد که در آن روندهای ظاهری ناپدید میشوند یا زمانی که دادهها در سطح متفاوتی تجمیع میشوند، به دلیل عوامل مخدوشکننده و روابط علّی نادرست درک شدهاند.
مغالطه زیستمحیطی شامل برونیابی اشتباه اطلاعات مربوط به جمعیت در یک سطح تجمع به سطح تجمعی دیگر است، جایی که ادعا ممکن است معتبر نباشد. بیماری که 40 درصد از کارگران کشاورزی را در یک استان مبتلا می کند ممکن است با شیوع یکسان در جمعیت بیشتر وجود نداشته باشد. همچنین بسیار محتمل است که مزارع یا شهرک های کشاورزی منزوی در آن استان وجود داشته باشند که شیوع مشابهی از آن بیماری را تجربه نکنند . فرض شیوع 40 درصدی در آن مکانهای کمتر آسیبدیده نیز اشتباه است.
مسئله واحد منطقه ای قابل اصلاح (MAUP) یک مشکل شناخته شده در داده های مکانی است که توسط Stan Openshaw در سال 1984 در CATMOG 38 توضیح داده شده است. بسته به شکل و اندازه نواحی مورد استفاده برای تجمیع دادهها، متخصص دادههای مکانی میتواند تقریباً هر ارتباطی را بین متغیرهای داده برقرار کند. ترسیم مناطق رایدهی که به نفع یک حزب یا دیگری هستند، نمونهای از MAUP است.
همه این موقعیت ها شامل برون یابی نامناسب از یک سطح تجمعی به سطح دیگر است. سطوح مختلف تجزیه و تحلیل ممکن است به تجمیعهای مختلف یا حتی مجموعه دادههای کاملاً متفاوت نیاز داشته باشند. 12
توجه داشته باشید که دادههای سرشماری، جمعیتشناختی و اپیدمیولوژیک معمولاً به دلایل حفظ حریم خصوصی بر اساس مناطق جمعآوری میشوند و این مناطق اغلب دلخواه هستند، یعنی بر اساس مرزهای معنیدار دنیای واقعی نیستند. هنگام کار با این نوع دادهها، پزشکان ML باید بررسی کنند که آیا عملکرد و پیشبینیهای مدل بسته به اندازه و شکل مناطق انتخابشده یا سطح تجمع تغییر میکند یا خیر، و اگر چنین است، آیا پیشبینیهای مدل تحتتاثیر یکی از این مسائل تجمیع قرار میگیرد یا خیر.
مراجع
باتن، کاترین و همکاران. "شکست نیرو: چرا حجم نمونه کوچک قابلیت اطمینان علوم اعصاب را تضعیف می کند." Nature Reviews Neuroscience جلد 14 (2013)، 365-376. DOI: https://doi.org/10.1038/nrn3475
قاهره، آلبرتو نمودارها چگونه دروغ می گویند: هوشمندتر شدن در مورد اطلاعات بصری. نیویورک: WW نورتون، 2019.
Davenport, Thomas H. "A Predictive Analytics Primer." در راهنمای HBR برای مبانی تجزیه و تحلیل داده ها برای مدیران (بوستون: HBR Press، 2018) 81-86.
دی لانگه، بارت، استفانو پانتونی و ریچارد لاریک. "تفکر خطی در دنیای غیرخطی." در راهنمای HBR برای مبانی تجزیه و تحلیل داده ها برای مدیران (بوستون: HBR Press، 2018) 131-154.
النبرگ، اردن چگونه اشتباه نکنیم: قدرت تفکر ریاضی نیویورک: پنگوئن، 2014.
هاف، دارل. چگونه با آمار دروغ بگوییم نیویورک: WW نورتون، 1954.
جونز، بن. اجتناب از دام داده ها هوبوکن، نیوجرسی: وایلی، 2020.
اپن شاو، استن. «مسئله واحد مساحتی قابل تغییر»، CATMOG 38 (نرویچ، انگلستان: کتابهای جغرافیایی 1984) 37.
خطرات مدل سازی مالی: VaR و بحران اقتصادی ، کنگره 111 (2009) (شهادت های نسیم ن. طالب و ریچارد بوکستابر).
ریتر، دیوید. "چه زمانی باید بر اساس یک همبستگی عمل کرد و چه زمانی نباید". در راهنمای HBR برای مبانی تجزیه و تحلیل داده ها برای مدیران (بوستون: HBR Press، 2018) 103-109.
تولچینسکی، تئودور اچ و النا آ. واراویکووا. "فصل 3: اندازه گیری، نظارت و ارزیابی سلامت یک جمعیت" در بهداشت عمومی جدید ، ویرایش 3. San Diego: Academic Press, 2014, pp 91-147. DOI: https://doi.org/10.1016/B978-0-12-415766-8.00003-3.
ون دورن، جنی، پیتر سی. ورهوف، و تامو ها بیجمولت. "اهمیت روابط غیر خطی بین نگرش و رفتار در تحقیقات سیاست". مجله سیاست مصرف کننده 30 (2007) 75-90. DOI: https://doi.org/10.1007/s10603-007-9028-3
مرجع تصویر
بر اساس «توزیع فون میزس». Rainald62, 2018. منبع
{kind=link}
النبرگ 125. ↩
هاف 77-79. هاف از دفتر تحقیقات افکار عمومی پرینستون استناد می کند، اما او ممکن است به گزارش آوریل 1944 مرکز ملی تحقیقات افکار عمومی در دانشگاه دنور فکر کرده باشد. ↩
تولچینسکی و واراویکووا. ↩
گری تابز، آیا واقعاً می دانیم چه چیزی ما را سالم می کند؟» در مجله نیویورک تایمز، 16 سپتامبر 2007. ↩
النبرگ 78. ↩
هاف 91-92. ↩
هاف 93. ↩
جونز 157-167. ↩
هاف 95. ↩
داونپورت 84. ↩
به شهادت نسیم ن. طالب و ریچارد بوکستبر در کنگره در مخاطرات مدلسازی مالی: VaR و بحران اقتصادی ، کنگره 111 (2009) 11-67 مراجعه کنید. ↩
قاهره 155، 162. ↩