"Tutti i modelli sono sbagliati, ma alcuni sono utili". - George Box, 1978
Sebbene siano molto efficaci, le tecniche statistiche hanno dei limiti. Comprendere questi limiti può aiutare un ricercatore a evitare gaffe e affermazioni imprecise, come l'affermazione di BF Skinner secondo cui Shakespeare non usava l'allitterazione più di quanto suggerirebbe la casualità. Lo studio di Skinner era sottodimensionato.1
Incertezza e barre di errore
È importante specificare l'incertezza nell'analisi. È altrettanto importante quantificare l'incertezza nelle analisi di altre persone. I punti dati che sembrano tracciare una tendenza su un grafico, ma hanno barre di errore sovrapposte, potrebbero non indicare alcun modello. L'incertezza può anche essere troppo elevata per trarre conclusioni utili da un determinato studio o test statistico. Se uno studio di ricerca richiede un'accuratezza a livello di lotto, un set di dati geospaziali con un'incertezza di +/- 500 m ha un'incertezza troppo elevata per essere utilizzabile.
In alternativa, i livelli di incertezza possono essere utili durante i processi di decisione. I dati a supporto di un determinato trattamento dell'acqua con un'incertezza del 20% nei risultati possono portare a un consiglio per l'implementazione di quel trattamento con il monitoraggio continuo del programma per risolvere l'incertezza.
Le reti neurali bayesiane possono quantificare l'incertezza prevedendo distribuzioni di valori anziché singoli valori.
Mancanza di pertinenza
Come discusso nell'introduzione, c'è sempre almeno un piccolo divario tra i dati e la realtà. L'esperto di ML astuto deve stabilire se il set di dati è pertinente alla domanda posta.
Huff descrive un primo studio sull'opinione pubblica che ha rilevato che le risposte degli americani bianchi alla domanda su quanto fosse facile per gli americani neri guadagnarsi da vivere erano direttamente e inversamente correlate al loro livello di simpatia nei confronti degli americani neri. Con l'aumento dell'ostilità razziale, le risposte sulle opportunità economiche previste sono diventate sempre più ottimistiche. Questo potrebbe essere stato frainteso come un segno di progresso. Tuttavia, lo studio non poteva mostrare nulla sulle opportunità economiche effettive disponibili per gli afroamericani all'epoca e non era adatto per trarre conclusioni sulla realtà del mercato del lavoro, ma solo sulle opinioni dei partecipanti al sondaggio. I dati raccolti erano infatti irrilevanti per lo stato del mercato del lavoro.2
Potresti addestrare un modello con i dati dei sondaggi come quelli descritti sopra, in cui l'output misura effettivamente l'ottimismo anziché le opportunità. Tuttavia, poiché le opportunità previste sono irrilevanti per quelle effettive, se dichiari che il modello prevede le opportunità effettive, stai rappresentando in modo ingannevole ciò che il modello prevede.
Confondimenti
Una variabile di disturbo, confondente o cofattore è una variabile non oggetto di studio che influisce sulle variabili oggetto di studio e può distorcere i risultati. Ad esempio, prendi in considerazione un modello di ML che prevede i tassi di mortalità per un paese in base alle funzionalità delle norme di salute pubblica. Supponiamo che l'età mediana non sia una caratteristica. Supponiamo inoltre che alcuni paesi abbiano una popolazione più anziana rispetto ad altri. Se ignoriamo la variabile di confusione dell'età media, questo modello potrebbe prevedere tassi di mortalità errati.
Negli Stati Uniti, la razza è spesso fortemente correlata alla classe socioeconomica, anche se solo la razza, e non la classe, viene registrata con i dati sulla mortalità. I fattori di confusione correlati alla classe, come l'accesso a cure mediche, alimentazione, lavoro pericoloso e alloggi sicuri, possono avere un'influenza maggiore sui tassi di mortalità rispetto alla razza, ma essere trascurati perché non sono inclusi nei set di dati.3 Identificare e tenere conto di questi fattori di confusione è fondamentale per creare modelli utili e trarre conclusioni significative e accurate.
Se un modello viene addestrato su dati sulla mortalità esistenti, che includono la razza, ma non la classe, potrebbe prevedere la mortalità in base alla razza, anche se la classe è un predittore più forte della mortalità. Ciò potrebbe portare a supposizioni imprecise sulla causalità e a previsioni imprecise sulla mortalità dei pazienti. Gli esperti di ML devono chiedersi se esistono fattori di confusione nei loro dati e quali variabili significative potrebbero mancare nel set di dati.
Nel 1985, lo Nurses' Health Study, uno studio prospettico di coorte della Harvard Medical School e della Harvard School of Public Health, ha rilevato che le persone che facevano parte della coorte che assumevano la terapia sostitutiva con estrogeni avevano un'incidenza inferiore di infarti rispetto alle persone che non avevano mai assunto estrogeni. Di conseguenza, i medici hanno prescritto estrogeni alle loro pazienti in menopausa e postmenopausa per decenni, finché uno studio clinico nel 2002 non ha identificato i rischi per la salute creati dalla terapia ormonale estrogenica a lungo termine. La pratica di prescrivere estrogeni alle donne in post menopausa è stata interrotta, ma non prima di causare una stima di decine di migliaia di decessi prematuri.
Più fattori di confusione potrebbero aver causato l'associazione. Gli epidemiologi hanno scoperto che le donne che assumono la terapia ormonale sostitutiva, rispetto alle donne che non la assumono, tendono ad essere più magre, più istruite, più ricche, più consapevoli della propria salute e più propense a fare attività fisica. In diversi studi, è stato dimostrato che l'istruzione e la ricchezza riducono il rischio di malattie cardiache. Questi effetti avrebbero confuso la correlazione apparente tra terapia estrogenica e infarti.4
Percentuali con numeri negativi
Evita di utilizzare le percentuali quando sono presenti numeri negativi,5 poiché tutti i tipi di utili e perdite significativi possono essere oscurati. Supponiamo, per semplicità, che il settore della ristorazione offra 2 milioni di posti di lavoro. Se il settore perde 1 milione di questi posti di lavoro alla fine di marzo 2020, non registra variazioni nette per dieci mesi e ne recupera 900.000 all'inizio di febbraio 2021, un confronto anno su anno all'inizio di marzo 2021 suggerirebbe solo una perdita del 5% dei posti di lavoro nei ristoranti. Se non si verificano altre modifiche, un confronto anno su anno a fine aprile 2021 suggerirebbe un aumento del 90% dei posti di lavoro nei ristoranti, un quadro molto diverso della realtà.
Preferisci i numeri effettivi, normalizzati in base alle esigenze. Per saperne di più, consulta Utilizzo dei dati numerici.
Fallacia post hoc e correlazioni inutili
L'errore di causazione post hoc è l'assunto che, poiché l'evento A è stato seguito dall'evento B, l'evento A ha causato l'evento B. In parole più semplici, si assume una relazione causa-effetto in cui non esiste. In termini ancora più semplici: le correlazioni non dimostrano la causalità.
Oltre a un chiaro rapporto di causa ed effetto, le correlazioni possono anche essere generate da:
- Caso puro (consulta Spurious correlations di Tyler Vigen per illustrazioni, inclusa una forte correlazione tra il tasso di divorzi nel Maine e il consumo di margarina).
- Una relazione reale tra due variabili, anche se non è chiaro quale variabile sia causale e quale sia interessata.
- Una terza causa separata che influisce su entrambe le variabili, anche se le variabili correlate non sono correlate tra loro. L'inflazione globale, ad esempio, può far aumentare i prezzi sia degli yacht sia del sedano.6
È inoltre rischioso estrapolare una correlazione oltre i dati esistenti. Huff sottolinea che una certa quantità di pioggia migliora i raccolti, ma troppa pioggia li danneggia; la relazione tra pioggia e risultati dei raccolti è non lineare.7 (Consulta le due sezioni successive per saperne di più sulle relazioni non lineari.) Jones fa notare che il mondo è pieno di eventi imprevedibili, come guerre e carestie, che sottopongono le previsioni future dei dati delle serie temporali a moltissima incertezza.8
Inoltre, anche una correlazione genuina basata su causa ed effetto potrebbe non essere utile per prendere decisioni. Huff cita, come esempio, la correlazione tra idoneità al matrimonio e istruzione universitaria negli anni '50. Le donne che andavano all'università avevano meno probabilità di sposarsi, ma potrebbe essere stato il caso che le donne che andavano all'università fossero meno propense a sposarsi fin dall'inizio. In questo caso, un'istruzione universitaria non cambiava la probabilità di contrarre matrimonio.9
Se un'analisi rileva una correlazione tra due variabili in un set di dati, chiedi:
- Di che tipo di correlazione si tratta: causa-effetto, spuria, relazione sconosciuta o causata da una terza variabile?
- Quanto è rischiosa l'estrapolazione dai dati? Ogni previsione del modello sui dati non presenti nel set di dati di addestramento è, in effetti, un'interpolazione o estrapolazione dei dati.
- La correlazione può essere utilizzata per prendere decisioni utili? Ad esempio, l'ottimismo potrebbe essere fortemente correlato all'aumento dei salari, ma l'analisi del sentiment di alcuni grandi corpora di dati di testo, come i post su social media da parte di utenti di un determinato paese, non sarebbe utile per prevedere l'aumento dei salari in quel paese.
Quando addestrano un modello, gli esperti di ML cercano in genere funzionalità fortemente correlate all'etichetta. Se la relazione tra le caratteristiche e l'etichetta non è ben compresa, questo potrebbe portare ai problemi descritti in questa sezione, inclusi i modelli basati su correlazioni spurie e i modelli che presuppongono che le tendenze storiche continueranno in futuro, quando in realtà non è così.
Il bias lineare
In "Linear Thinking in a Nonlinear World" Bart de Langhe, Stefano Puntoni e Richard Larrick descrivono il bias lineare come la tendenza del cervello umano a prevedere e cercare relazioni lineari, anche se molti fenomeni sono non lineari. La relazione tra atteggiamenti e comportamento umani, ad esempio, è una curva convessa e non una linea. In un articolo del 2007 pubblicato sul Journal of consumer policy citato da de Langhe et al., Jenny van Doorn et al. hanno modellato la relazione tra la preoccupazione dei partecipanti al sondaggio per l'ambiente e i loro acquisti di prodotti biologici. Chi ha dimostrato maggiore preoccupazione per l'ambiente ha acquistato più prodotti biologici, ma la differenza tra tutti gli altri intervistati è stata minima.
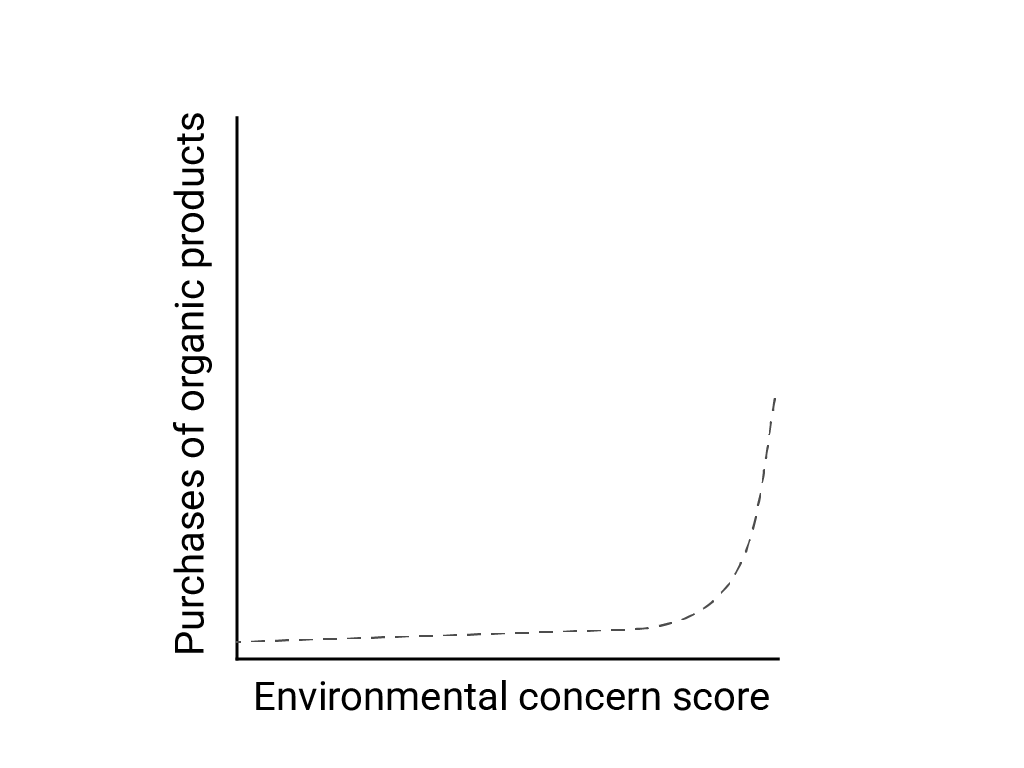
Quando progetti modelli o studi, tieni presente la possibilità di relazioni non lineari. Poiché i test A/B possono non rilevare relazioni non lineari, valuta la possibilità di testare anche una terza condizione intermedia, C. Valuta anche se il comportamento iniziale apparentemente lineare continuerà a essere lineare o se i dati futuri potrebbero mostrare un comportamento più logaritmico o non lineare.
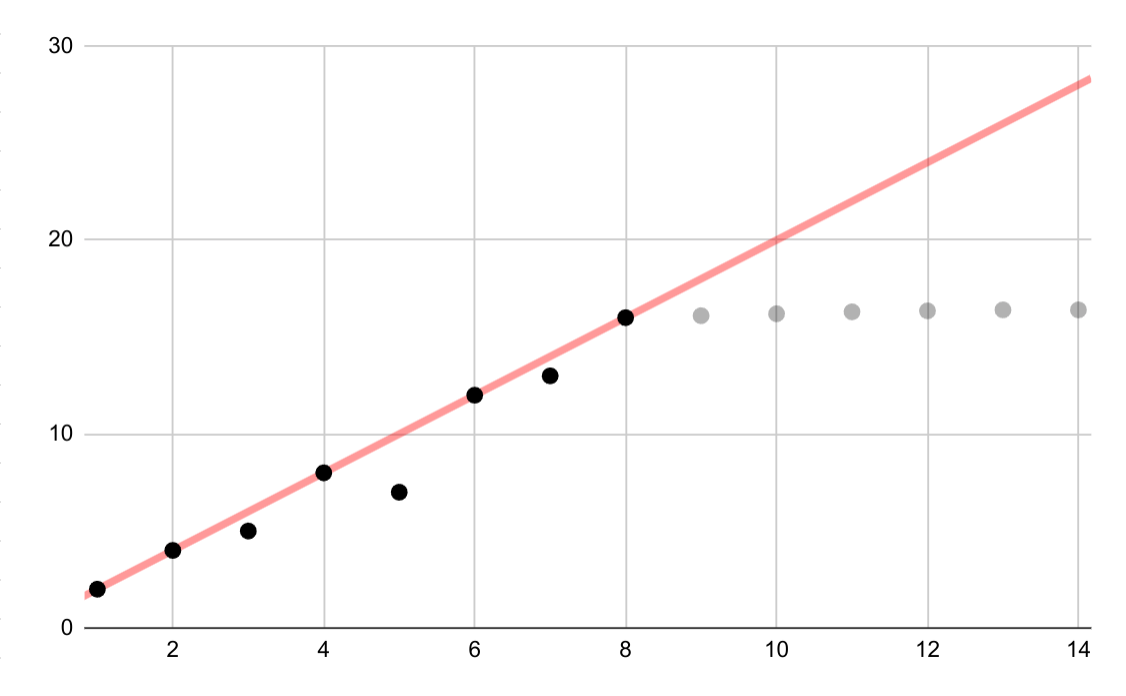
Questo esempio ipotetico mostra una stima lineare errata per i dati logaritmici. Se fossero disponibili solo i primi punti dati, sarebbe sia allettante che errato assumere una relazione lineare continua tra le variabili.
Interpolazione lineare
Esamina l'eventuale interpolazione tra i punti dati, perché l'interpolazione introduce punti fittizi e gli intervalli tra le misurazioni reali possono contenere fluttuazioni significative. Ad esempio, prendiamo in considerazione la seguente visualizzazione di quattro punti dati collegati con interpolazioni lineari:

Poi prendi in considerazione questo esempio di fluttuazioni tra punti dati che vengono eliminate da un'interpolazione lineare:
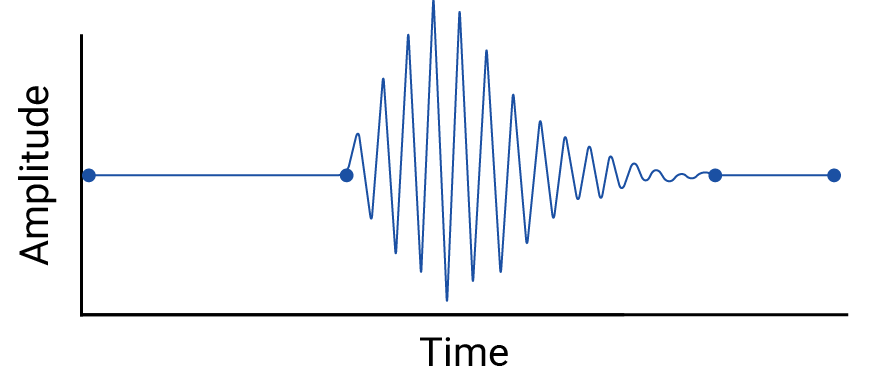
L'esempio è artificioso perché i sismografi raccolgono dati continui, quindi questo terremoto non verrebbe perso. Tuttavia, è utile per illustrare le ipotesi fatte dalle interpolazioni e i fenomeni reali che i professionisti dei dati potrebbero perdere.
Fenomeno di Runge
Il fenomeno di Runge, noto anche come "oscillazione polinomiale", è un problema all'estremo opposto dello spettro rispetto all'interpolazione lineare e all'errore sistematico lineare. Quando adatti un'interpolazione polinomiale ai dati, è possibile utilizzare un polinomio con un grado troppo elevato (il grado o l'ordine è l'esponente più alto nell'equazione polinomiale). Ciò produce strane oscillazioni ai bordi. Ad esempio, l'applicazione di un'interpolazione polinomiale di grado 11, ovvero il termine di ordine più elevato nell'equazione polinomiale ha \(x^{11}\), a dati approssimativamente lineari, genera previsioni notevolmente negative all'inizio e alla fine dell'intervallo di dati:
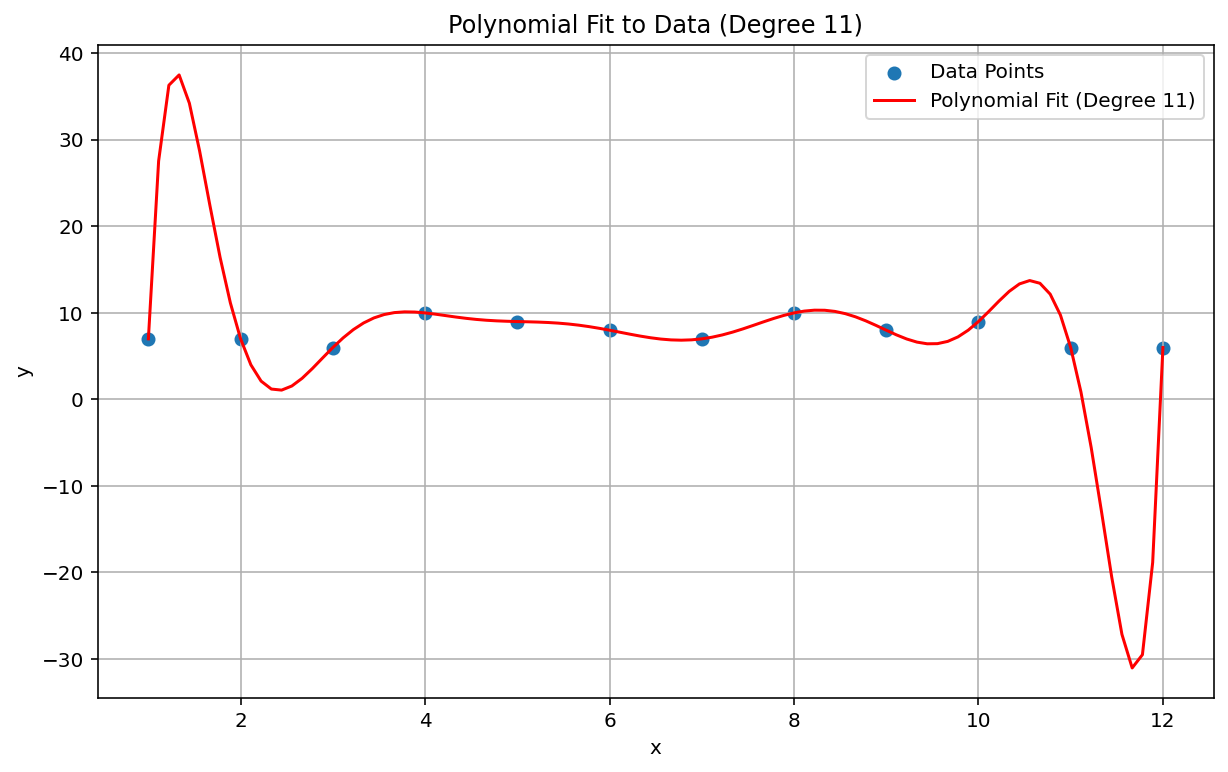
Nel contesto dell'apprendimento automatico, un fenomeno analogo è il sovrappersonalizzazione.
Mancate rilevazioni statistiche
A volte un test statistico potrebbe essere troppo debole per rilevare un effetto ridotto. Una potenza ridotta nell'analisi statistica indica una bassa probabilità di identificare correttamente gli eventi veri e, di conseguenza, un'alta probabilità di falsi negativi. Katherine Button e altri hanno scritto su Nature: "Quando gli studi in un determinato campo sono progettati con una potenza del 20%, significa che se in quel campo esistono 100 effetti non nulli genuini da scoprire, questi studi dovrebbero scoprirne solo 20". A volte può essere utile aumentare la dimensione del campione, così come un design dello studio attento.
Una situazione analoga nell'ML è il problema della classificazione e della scelta di una soglia di classificazione. Una scelta di una soglia più elevata comporta meno falsi positivi e più falsi negativi, mentre una soglia più bassa comporta più falsi positivi e meno falsi negativi.
Oltre ai problemi di potenza statistica, poiché la correlazione è progettata per rilevare relazioni lineari, le correlazioni non lineari tra le variabili possono essere perse. Analogamente, le variabili possono essere correlate tra loro, ma non essere correlate statisticamente. Le variabili possono anche essere correlata negativamente, ma completamente non correlate, in quello che è noto come paradosso di Berkson o fallacia di Berkson. L'esempio classico dell'errore di Berkson è la correlazione negativa spuria tra qualsiasi fattore di rischio e una malattia grave quando si esamina una popolazione di degenti in ospedale (rispetto alla popolazione generale), che deriva dal processo di selezione (una condizione grave sufficiente a richiedere il ricovero in ospedale).
Valuta se una di queste situazioni si applica al tuo caso.
Modelli obsoleti e ipotesi non valide
Anche i modelli buoni possono peggiorare nel tempo perché il comportamento (e il mondo, per inciso) può cambiare. I primi modelli predittivi di Netflix sono stati ritirati quando la base di clienti è passata da utenti giovani e tecnologicamente esperti alla popolazione generale.10
I modelli possono anche contenere ipotesi silenziose e imprecise che possono rimanere nascoste fino al fallimento catastrofico del modello, come nel crollo del mercato del 2008. I modelli di valore a rischio (VaR) del settore finanziario dichiaravano di stimare con precisione la perdita massima del portafoglio di qualsiasi trader, ad esempio una perdita massima di 100.000$ prevista il 99% delle volte. Tuttavia, nelle condizioni anomale del crash, un portafoglio con una perdita massima prevista di 100.000$ a volte perdeva 1.000.000$ o più.
I modelli VaR si basavano su ipotesi errate, tra cui:
- Le variazioni del mercato passate sono indicative di quelle future.
- I rendimenti previsti erano basati su una distribuzione normale (a coda sottile e quindi prevedibile).
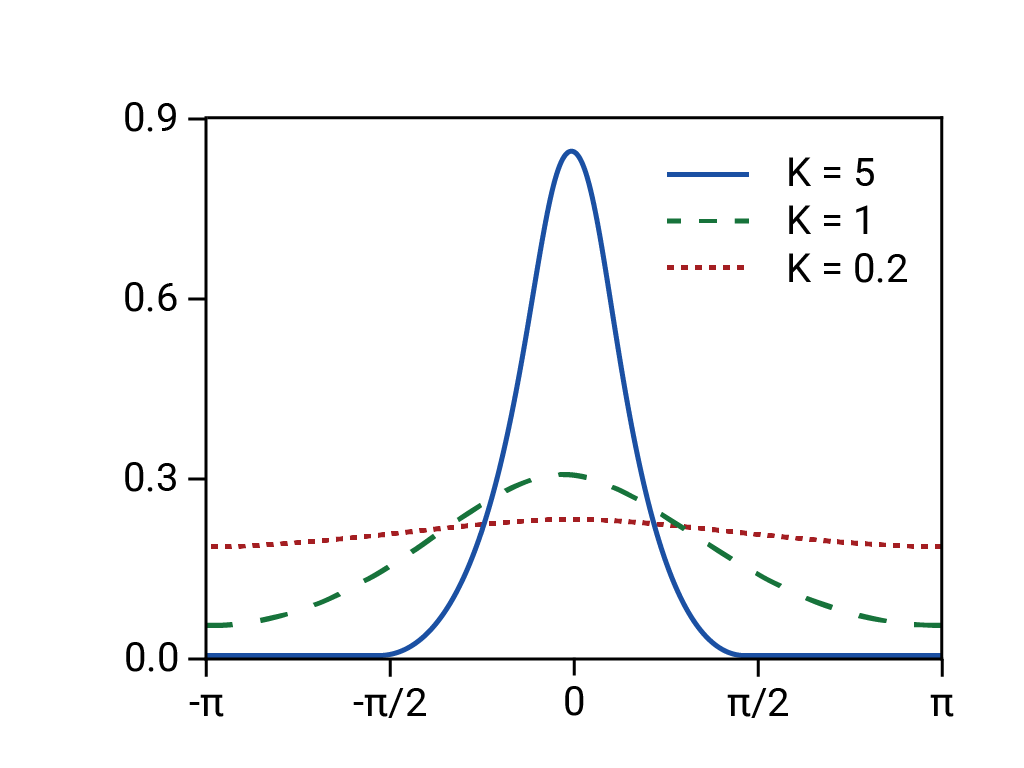
Infatti, la distribuzione sottostante era a coda pesante, "selvaggia" o frattale, il che significa che esisteva un rischio molto più elevato di eventi long-tail, estremi e apparentemente rari rispetto a quanto previsto da una distribuzione normale. La natura a coda pesante della distribuzione reale era ben nota, ma non è stato fatto nulla in merito. Ciò che era meno noto era quanto fossero complessi e strettamente correlati vari fenomeni, tra cui il trading basato su computer con svendite automatiche.11
Problemi di aggregazione
I dati aggregati, che includono la maggior parte dei dati demografici ed epidemiologici, sono soggetti a un particolare insieme di insidie. Il paradosso di Simpson, o paradosso dell'aggregazione, si verifica nei dati aggregati in cui le tendenze apparenti scompaiono o si invertono quando i dati vengono aggregati a un livello diverso, a causa di fattori di confusione e relazioni causali fraintese.
L'errore ecologico consiste nell'estrapolare erroneamente le informazioni su una popolazione a un livello di aggregazione a un altro livello di aggregazione, dove l'affermazione potrebbe non essere valida. Una malattia che colpisce il 40% dei lavoratori agricoli di una provincia potrebbe non essere presente con la stessa prevalenza nella popolazione più ampia. È inoltre molto probabile che in quella provincia esistano fattorie isolate o città agricole che non registrano una prevalenza così elevata della malattia. Sarebbe fuorviante assumere una prevalenza del 40% anche nelle località meno colpite.
Il problema delle unità areali modificabili (MAUP) è un problema ben noto nei dati geospaziali, descritto da Stan Openshaw nel 1984 in CATMOG 38. A seconda delle forme e delle dimensioni delle aree utilizzate per aggregare i dati, un professionista dei dati geospaziali può stabilire quasi qualsiasi correlazione tra le variabili nei dati. La creazione di collegi elettorali che favoriscono un partito o un altro è un esempio di MAUP.
Tutte queste situazioni comportano un'estrapolazione inappropriata da un livello di aggregazione all'altro. Livelli di analisi diversi possono richiedere aggregazioni diverse o persino set di dati completamente diversi.12
Tieni presente che i dati del censimento, demografici ed epidemiologici vengono solitamente aggregati per zone per motivi di privacy e che queste zone sono spesso arbitrarie, ovvero non si basano su confini reali significativi. Quando lavorano con questi tipi di dati, gli esperti di ML devono verificare se le prestazioni e le previsioni del modello cambiano in base alle dimensioni e alla forma delle zone selezionate o al livello di aggregazione e, in caso affermativo, se le previsioni del modello sono interessate da uno di questi problemi di aggregazione.
Riferimenti
Button, Katharine et al. "Power failure: why small sample size undermines the reliability of neuroscience." Nature Reviews Neuroscience, vol. 14 (2013), 365-376. DOI: https://doi.org/10.1038/nrn3475
Cairo, Alberto. How Charts Lie: Getting Smarter about Visual Information. New York: W.W. Norton, 2019.
Davenport, Thomas H. "A Predictive Analytics Primer". In HBR Guide to Data Analytics Basics for Managers (Boston: HBR Press, 2018) 81-86.
De Langhe, Bart, Stefano Puntoni e Richard Larrick. "Pensiero lineare in un mondo non lineare". In HBR Guide to Data Analytics Basics for Managers (Boston: HBR Press, 2018), pp. 131-154.
Ellenberg, Giordania. How Not to Be Wrong: The Power of Mathematical Thinking. New York: Penguin, 2014.
Huff, Darrell. Come mentire con le statistiche. NY: W.W. Norton, 1954.
Jones, Ben. Evitare insidie relative ai dati. Hoboken, NJ: Wiley, 2020.
Openshaw, Stan. "The Modifiable Areal Unit Problem", CATMOG 38 (Norwich, Inghilterra: Geo Books 1984) 37.
The Risks of Financial Modeling: VaR and the Economic Meltdown, 111th Congress (2009) (testimonies of Nassim N. Taleb e Richard Bookstaber).
Ritter, David. "Quando intervenire in base a una correlazione e quando no". In HBR Guide to Data Analytics Basics for Managers (Boston: HBR Press, 2018) 103-109.
Tulchinsky, Theodore H. ed Elena A. Varavikova. "Capitolo 3: Misurazione, monitoraggio e valutazione della salute di una popolazione" in The New Public Health, 3a ed. San Diego: Academic Press, 2014, pp 91-147. DOI: https://doi.org/10.1016/B978-0-12-415766-8.00003-3.
Van Doorn, Jenny, Peter C. Verhoef e Tammo H. A. Bijmolt. "L'importanza delle relazioni non lineari tra atteggiamenti e comportamenti nella ricerca sulle norme". Journal of Consumer Policy 30 (2007) 75–90. DOI: https://doi.org/10.1007/s10603-007-9028-3
Riferimento immagine
In base alla "distribuzione di von Mises". Rainald62, 2018. Origine
{kind=link}
-
Ellenberg 125. ↩
-
Huff 77-79. Huff cita l'Office of Public Opinion Research di Princeton, ma potrebbe aver fatto riferimento al report di aprile 1944 del National Opinion Research Center dell'Università di Denver. ↩
-
Tulchinsky e Varavikova. ↩
-
Gary Taubes, Do We Really Know What Makes Us Healthy?" in The New York Times Magazine, 16 settembre 2007. ↩
-
Ellenberg 78. ↩
-
Huff 91-92. ↩
-
Huff 93. ↩
-
Jones 157-167. ↩
-
Huff 95. ↩
-
Davenport 84. ↩
-
Leggi la testimonianza di Nassim N. al Congresso. Taleb e Richard Bookstaber in The Risks of Financial Modeling: VaR and the Economic Meltdown, 111th Congress (2009) 11-67. ↩
-
Cairo 155, 162. ↩