«Все модели неверны, но некоторые полезны». — Джордж Бокс, 1978 г.
Хотя статистические методы и мощные, они имеют свои ограничения. Понимание этих ограничений может помочь исследователю избежать оплошностей и неточных заявлений, таких как утверждение Б. Ф. Скиннера о том, что Шекспир не использовал аллитерацию чаще, чем можно было бы предсказать с помощью случайности. (Исследование Скиннера было недостаточно мощным . 1 )
Неопределенность и планки погрешностей
Важно указать неопределенность в вашем анализе. Не менее важно количественно оценить неопределенность в анализах других людей. Точки данных, которые, как кажется, отображают тенденцию на графике, но имеют перекрывающиеся полосы погрешности, могут вообще не указывать на какую-либо закономерность. Неопределенность также может быть слишком высокой, чтобы сделать полезные выводы из конкретного исследования или статистического теста. Если для исследования требуется точность на уровне лота, геопространственный набор данных с неопределенностью +/- 500 м имеет слишком большую неопределенность, чтобы быть пригодным для использования.
В качестве альтернативы уровни неопределенности могут быть полезны в процессе принятия решений. Данные, подтверждающие определенную обработку воды с 20% неопределенностью в результатах, могут привести к рекомендации по внедрению этой обработки воды с постоянным мониторингом программы для устранения этой неопределенности.
Байесовские нейронные сети могут количественно оценивать неопределенность, прогнозируя распределения значений вместо отдельных значений.
Нерелевантность
Как обсуждалось во введении, всегда есть хотя бы небольшой разрыв между данными и реальностью. Проницательный практик МО должен установить, соответствует ли набор данных заданному вопросу.
Хафф описывает раннее исследование общественного мнения, которое показало, что ответы белых американцев на вопрос о том, насколько легко чернокожим американцам зарабатывать на жизнь, были прямо и обратно связаны с уровнем их симпатии к чернокожим американцам. По мере того, как росла расовая враждебность, ответы об ожидаемых экономических возможностях становились все более и более оптимистичными. Это можно было бы неправильно понять как признак прогресса. Однако исследование не могло показать ничего о реальных экономических возможностях, доступных чернокожим американцам в то время, и не подходило для выводов о реальности рынка труда — только мнения респондентов опроса. Собранные данные фактически не имели отношения к состоянию рынка труда. 2
Вы можете обучить модель на данных опроса, подобных описанным выше, где выходные данные фактически измеряют оптимизм , а не возможности . Но поскольку прогнозируемые возможности не имеют отношения к фактическим возможностям, если вы утверждаете, что модель прогнозирует фактические возможности, вы искажаете то, что предсказывает модель.
Смущает
Вмешивающаяся переменная , вмешивающийся фактор или кофактор — это переменная, которая не изучается, но влияет на изучаемые переменные и может искажать результаты. Например, рассмотрим модель МО, которая прогнозирует показатели смертности для страны с исходными данными на основе особенностей политики общественного здравоохранения. Предположим, что медианный возраст не является особенностью. Далее предположим, что в некоторых странах население старше, чем в других. Игнорируя вмешивающуюся переменную медианного возраста, эта модель может прогнозировать ошибочные показатели смертности.
В Соединенных Штатах раса часто тесно связана с социально-экономическим классом, хотя только раса, а не класс, регистрируется в данных о смертности. Связанные с классом факторы, такие как доступ к здравоохранению, питанию, опасной работе и безопасному жилью, могут оказывать более сильное влияние на уровень смертности, чем раса, но ими следует пренебречь, поскольку они не включены в наборы данных. 3 Выявление и контроль этих факторов имеет решающее значение для построения полезных моделей и получения значимых и точных выводов.
Если модель обучена на существующих данных о смертности, которые включают расу, но не класс, она может предсказывать смертность на основе расы, даже если класс является более сильным предиктором смертности. Это может привести к неточным предположениям о причинно-следственной связи и неточным прогнозам о смертности пациентов. Практикующие специалисты по МО должны спросить, есть ли в их данных помехи, а также какие значимые переменные могут отсутствовать в их наборе данных.
В 1985 году исследование Nurses' Health Study, наблюдательное когортное исследование Гарвардской медицинской школы и Гарвардской школы общественного здравоохранения, показало, что у членов когорты, принимавших заместительную терапию эстрогенами, наблюдался более низкий уровень сердечных приступов по сравнению с членами когорты, которые никогда не принимали эстроген. В результате врачи десятилетиями прописывали эстроген своим пациенткам в менопаузе и постменопаузе, пока клиническое исследование в 2002 году не выявило риски для здоровья, создаваемые долгосрочной терапией эстрогенами. Практика прописывания эстрогена женщинам в постменопаузе прекратилась, но не раньше, чем это привело к, по оценкам, десяткам тысяч преждевременных смертей.
Множество факторов могли вызвать эту связь. Эпидемиологи обнаружили, что женщины, принимающие заместительную гормональную терапию, по сравнению с женщинами, которые ее не принимают, как правило, худее, более образованы, богаче, более осведомлены о своем здоровье и более склонны заниматься спортом. В различных исследованиях было обнаружено, что образование и благосостояние снижают риск сердечных заболеваний. Эти эффекты могли бы исказить очевидную корреляцию между эстрогеновой терапией и сердечными приступами. 4
Проценты с отрицательными числами
Избегайте использования процентов, когда присутствуют отрицательные числа, 5, поскольку все виды значимых прибылей и убытков могут быть скрыты. Предположим, ради простой математики, что в ресторанной индустрии 2 миллиона рабочих мест. Если отрасль потеряет 1 миллион из этих рабочих мест в конце марта 2020 года, не испытает чистых изменений в течение десяти месяцев и вернет 900 000 рабочих мест в начале февраля 2021 года, сравнение по сравнению с прошлым годом в начале марта 2021 года покажет только 5% потери рабочих мест в ресторанах. Если не предположить никаких других изменений, сравнение по сравнению с прошлым годом в конце апреля 2021 года покажет 90% увеличение рабочих мест в ресторанах, что является совершенно иной картиной реальности.
Предпочитайте реальные числа, нормализованные соответствующим образом. Подробнее см. в разделе Работа с числовыми данными .
Ошибки постфактум и бесполезные корреляции
Ошибочное предположение постфактум заключается в предположении, что поскольку за событием А последовало событие В, событие А вызвало событие В. Проще говоря, это предположение о причинно-следственной связи там, где ее нет. Еще проще: корреляции не доказывают причинно-следственную связь.
Помимо четкой причинно-следственной связи, корреляции могут также возникать из-за:
- Чистая случайность (см. книгу Тайлера Вигена «Ложные корреляции» для иллюстраций, включая сильную корреляцию между уровнем разводов в штате Мэн и потреблением маргарина).
- Реальная связь между двумя переменными, хотя остается неясным, какая переменная является причинной, а какая — затронутой.
- Третья, отдельная причина, которая влияет на обе переменные, хотя коррелированные переменные не связаны друг с другом. Глобальная инфляция, например, может поднять цены как на яхты, так и на сельдерей. 6
Также рискованно экстраполировать корреляцию за пределы существующих данных. Хафф указывает, что некоторый дождь улучшит урожай, но слишком много дождя повредит ему; связь между дождем и результатами урожая нелинейна. 7 (См. следующие два раздела для получения дополнительной информации о нелинейных связях.) Джонс отмечает, что мир полон непредсказуемых событий, таких как война и голод, которые подвергают будущие прогнозы временных рядов данных огромной неопределенности. 8
Более того, даже подлинная корреляция, основанная на причине и следствии, может не помочь в принятии решений. Хафф приводит в качестве примера корреляцию между брачностью и образованием в колледже в 1950-х годах. Женщины, которые учились в колледже, реже выходили замуж, но могло быть так, что женщины, которые учились в колледже, изначально были менее склонны выходить замуж. Если бы это было так, то образование в колледже не изменило бы их вероятность выйти замуж. 9
Если анализ обнаруживает корреляцию между двумя переменными в наборе данных, задайте вопрос:
- Какой это тип корреляции: причинно-следственная, ложная, неизвестная связь или вызванная третьей переменной?
- Насколько рискованна экстраполяция данных? Каждое прогнозирование модели на данных, не входящих в обучающий набор данных, по сути является интерполяцией или экстраполяцией данных.
- Можно ли использовать корреляцию для принятия полезных решений? Например, оптимизм может быть тесно связан с ростом заработной платы, но анализ настроений некоторых больших массивов текстовых данных, таких как сообщения в социальных сетях пользователей в определенной стране, не будет полезен для прогнозирования роста заработной платы в этой стране.
При обучении модели специалисты по МО обычно ищут признаки, которые сильно коррелируют с меткой. Если связь между признаками и меткой не очень хорошо понята, это может привести к проблемам, описанным в этом разделе, включая модели, основанные на ложных корреляциях, и модели, которые предполагают, что исторические тенденции сохранятся в будущем, хотя на самом деле это не так.
Линейное смещение
В «Линейном мышлении в нелинейном мире» Барт де Ланге, Стефано Пунтони и Ричард Ларрик описывают линейное смещение как тенденцию человеческого мозга ожидать и искать линейные связи, хотя многие явления нелинейны. Например, связь между человеческими установками и поведением представляет собой выпуклую кривую, а не линию. В статье журнала Journal of Consumer Policy за 2007 год, на которую ссылаются де Ланге и др., Дженни ван Дорн и др. смоделировали связь между обеспокоенностью респондентов по поводу окружающей среды и покупкой ими органических продуктов. Те, кто испытывал наибольшую обеспокоенность по поводу окружающей среды, покупали больше органических продуктов, но между всеми остальными респондентами было очень мало различий.
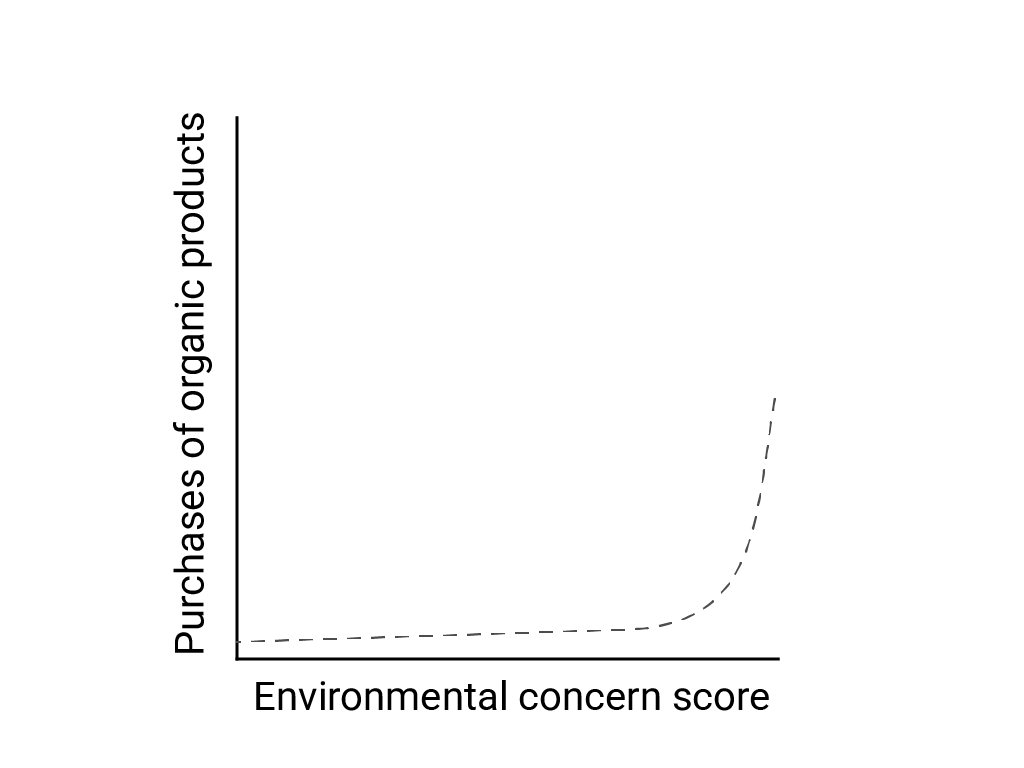
При проектировании моделей или исследований учитывайте возможность нелинейных связей. Поскольку A/B-тестирование может пропустить нелинейные связи, рассмотрите также возможность тестирования третьего, промежуточного условия C. Также рассмотрите, будет ли первоначальное поведение, которое кажется линейным, продолжать линейным, или будущие данные могут показать более логарифмическое или другое нелинейное поведение.
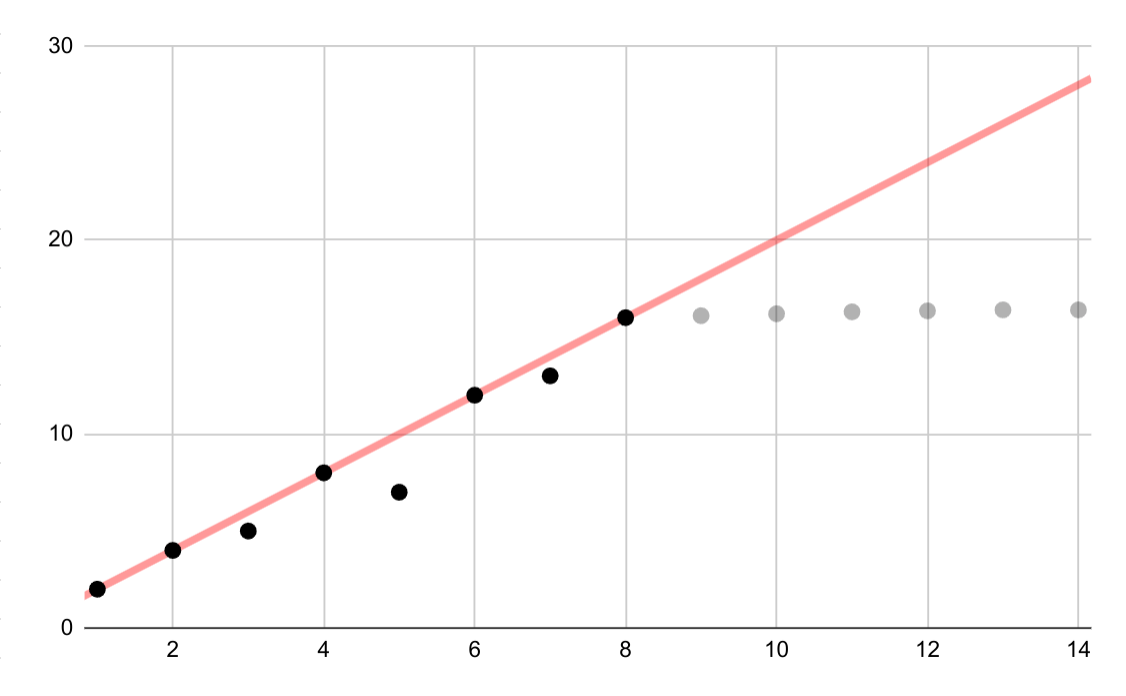
Этот гипотетический пример показывает ошибочную линейную подгонку для логарифмических данных. Если бы были доступны только первые несколько точек данных, было бы заманчиво и неверно предполагать продолжающуюся линейную связь между переменными.
Линейная интерполяция
Проверьте любую интерполяцию между точками данных, поскольку интерполяция вводит фиктивные точки, а интервалы между реальными измерениями могут содержать значимые колебания. В качестве примера рассмотрим следующую визуализацию четырех точек данных, связанных с линейными интерполяциями:

Затем рассмотрим этот пример колебаний между точками данных, которые стираются линейной интерполяцией:
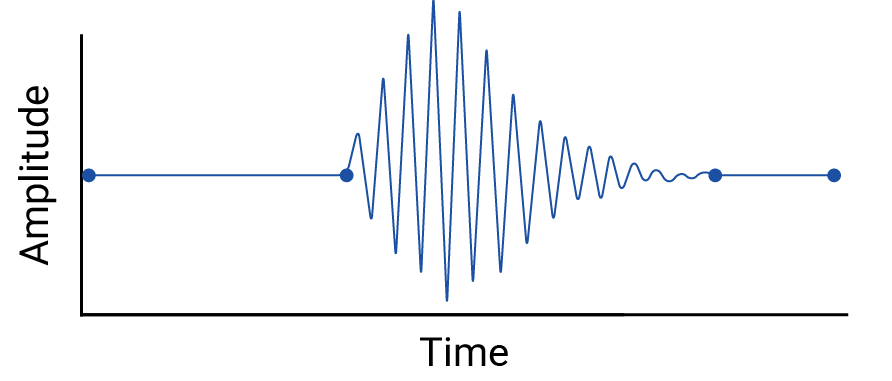
Пример надуман, потому что сейсмографы собирают непрерывные данные, и поэтому это землетрясение не будет пропущено. Но он полезен для иллюстрации предположений, сделанных интерполяциями, и реальных явлений, которые специалисты по данным могут пропустить.
феномен Рунге
Феномен Рунге , также известный как «полиномиальное колебание», является проблемой на противоположном конце спектра от линейной интерполяции и линейного смещения. При подгонке полиномиальной интерполяции к данным можно использовать полином со слишком высокой степенью (степень или порядок, являющийся наивысшим показателем в полиномиальном уравнении). Это приводит к странным колебаниям на краях. Например, применение полиномиальной интерполяции степени 11 означает, что член наивысшего порядка в полиномиальном уравнении имеет \(x^{11}\), к приблизительно линейным данным, приводит к чрезвычайно плохим прогнозам в начале и конце диапазона данных:
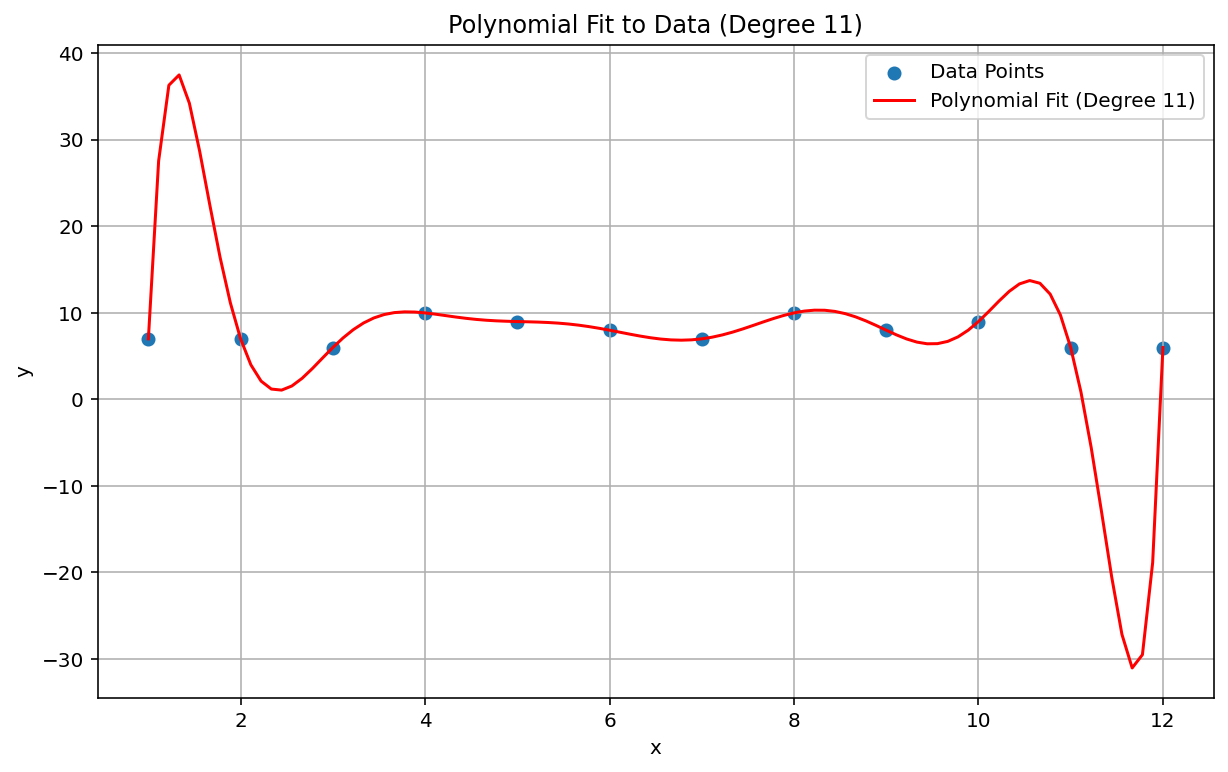
В контексте машинного обучения аналогичным явлением является переобучение .
Статистические ошибки обнаружения
Иногда статистический тест может быть слишком слабым для обнаружения небольшого эффекта. Низкая мощность в статистическом анализе означает низкую вероятность правильной идентификации истинных событий и, следовательно, высокую вероятность ложноотрицательных результатов. Кэтрин Баттон и др. написали в Nature : «Когда исследования в определенной области разрабатываются с мощностью 20%, это означает, что если в этой области необходимо обнаружить 100 подлинных ненулевых эффектов, ожидается, что эти исследования обнаружат только 20 из них». Иногда может помочь увеличение размера выборки, а также тщательный дизайн исследования.
Аналогичная ситуация в МО — проблема классификации и выбора порога классификации. Выбор более высокого порога приводит к меньшему количеству ложноположительных и большему количеству ложноотрицательных результатов, тогда как более низкий порог приводит к большему количеству ложноположительных и меньшему количеству ложноотрицательных результатов.
Помимо проблем со статистической мощностью, поскольку корреляция предназначена для обнаружения линейных связей, нелинейные корреляции между переменными могут быть упущены. Аналогично, переменные могут быть связаны друг с другом, но не статистически коррелированы. Переменные также могут быть отрицательно коррелированы, но совершенно не связаны, в том, что известно как парадокс Берксона или ошибка Берксона . Классическим примером ошибки Берксона является ложная отрицательная корреляция между любым фактором риска и тяжелым заболеванием при рассмотрении стационарного населения больницы (по сравнению с общей популяцией), которая возникает в процессе отбора (состояние, достаточно тяжелое, чтобы потребовать госпитализации).
Подумайте, применима ли какая-либо из этих ситуаций.
Устаревшие модели и неверные предположения
Даже хорошие модели могут со временем деградировать, поскольку поведение (и мир, если на то пошло) может измениться. Ранние прогностические модели Netflix пришлось списать, поскольку их клиентская база изменилась с молодых, технически подкованных пользователей на население в целом. 10
Модели также могут содержать молчаливые и неточные предположения, которые могут оставаться скрытыми до катастрофического провала модели, как в случае с крахом рынка 2008 года. Модели Value at Risk (VaR) финансовой индустрии претендовали на точную оценку максимального убытка по портфелю любого трейдера, скажем, максимальный убыток в размере 100 000 долларов ожидался в 99% случаев. Но в ненормальных условиях краха портфель с ожидаемым максимальным убытком в размере 100 000 долларов иногда терял 1 000 000 долларов или больше.
Модели VaR были основаны на ошибочных предположениях, включая следующие:
- Прошлые изменения рынка позволяют прогнозировать будущие изменения рынка.
- В основе прогнозируемой доходности лежало нормальное (тонкохвостое и, следовательно, предсказуемое) распределение.
Фактически, базовое распределение было с толстым хвостом, «диким» или фрактальным, что означает, что риск длиннохвостых, экстремальных и предположительно редких событий был намного выше, чем предсказывало бы нормальное распределение. Характер реального распределения с толстым хвостом был хорошо известен, но не применялся. Менее известно, насколько сложными и тесно связанными были различные явления, включая компьютерную торговлю с автоматизированными распродажами. 11
Проблемы агрегации
Данные, которые агрегируются, что включает в себя большинство демографических и эпидемиологических данных, подвержены определенному набору ловушек. Парадокс Симпсона , или парадокс объединения , возникает в агрегированных данных, где очевидные тенденции исчезают или меняются на противоположные, когда данные агрегируются на другом уровне из-за смешивающих факторов и неправильно понятых причинно-следственных связей.
Экологическое заблуждение заключается в ошибочной экстраполяции информации о популяции на одном уровне агрегации на другой уровень агрегации, где утверждение может быть недействительным. Болезнь, поражающая 40% сельскохозяйственных рабочих в одной провинции, может не присутствовать с той же распространенностью в большей популяции. Также весьма вероятно, что в этой провинции будут изолированные фермы или сельскохозяйственные города, которые не испытывают столь же высокой распространенности этой болезни. Предполагать распространенность в 40% в этих менее пораженных местах также было бы ошибочным.
Проблема изменяемой площади (MAUP) — известная проблема в геопространственных данных, описанная Стэном Опеншоу в 1984 году в CATMOG 38. В зависимости от форм и размеров областей, используемых для агрегирования данных, специалист по геопространственным данным может установить практически любую корреляцию между переменными в данных. Рисование избирательных округов, которые благоприятствуют той или иной партии, является примером MAUP.
Все эти ситуации включают ненадлежащую экстраполяцию с одного уровня агрегации на другой. Различные уровни анализа могут потребовать различных агрегаций или даже совершенно различных наборов данных. 12
Обратите внимание, что данные переписи, демографические и эпидемиологические данные обычно агрегируются по зонам из соображений конфиденциальности, и что эти зоны часто являются произвольными, то есть не основанными на значимых границах реального мира. При работе с этими типами данных специалисты по МО должны проверять, изменяются ли производительность и прогнозы модели в зависимости от размера и формы выбранных зон или уровня агрегации, и если да, то влияют ли на прогнозы модели одна из этих проблем агрегации.
Ссылки
Баттон, Кэтрин и др. «Отказ питания: почему малый размер выборки подрывает надежность нейронауки». Nature Reviews Neuroscience т. 14 (2013), 365–376. DOI: https://doi.org/10.1038/nrn3475
Каиро, Альберто. Как лгут диаграммы: Становимся умнее в отношении визуальной информации. Нью-Йорк: WW Norton, 2019.
Дэвенпорт, Томас Х. «Учебник по предиктивной аналитике». В руководстве HBR по основам аналитики данных для менеджеров (Бостон: HBR Press, 2018) 81-86.
Де Ланге, Барт, Стефано Пунтони и Ричард Ларрик. «Линейное мышление в нелинейном мире». В руководстве HBR по основам аналитики данных для менеджеров (Бостон: HBR Press, 2018) 131-154.
Элленберг, Джордан. Как не ошибаться: сила математического мышления. Нью-Йорк: Penguin, 2014.
Хафф, Даррелл. Как лгать с помощью статистики. Нью-Йорк: WW Norton, 1954.
Джонс, Бен. Как избежать ловушек в данных. Хобокен, Нью-Джерси: Wiley, 2020.
Опеншоу, Стэн. «Проблема изменяемой площади», CATMOG 38 (Норвич, Англия: Geo Books 1984) 37.
Риски финансового моделирования: VaR и экономический кризис , 111-й Конгресс (2009) (свидетельства Нассима Н. Талеба и Ричарда Букстабера).
Риттер, Дэвид. «Когда следует действовать на основе корреляции, а когда нет». В руководстве HBR по основам аналитики данных для менеджеров (Бостон: HBR Press, 2018) 103-109.
Тульчинский, Теодор Х. и Елена А. Варавикова. «Глава 3: Измерение, мониторинг и оценка здоровья населения» в The New Public Health , 3-е изд. Сан-Диего: Academic Press, 2014, стр. 91-147. DOI: https://doi.org/10.1016/B978-0-12-415766-8.00003-3.
Ван Дорн, Дженни, Питер К. Верхоф и Таммо Х. А. Беймолт. «Важность нелинейных отношений между отношением и поведением в исследовании политики». Журнал потребительской политики 30 (2007) 75–90. DOI: https://doi.org/10.1007/s10603-007-9028-3
Ссылка на изображение
На основе «Распределения фон Мизеса». Rainald62, 2018. Источник
{kind=link}
Элленберг 125. ↩
Хафф 77-79. Хафф ссылается на Управление по исследованию общественного мнения Принстона, но, возможно, он имел в виду отчет Национального центра исследования общественного мнения при Денверском университете за апрель 1944 года . ↩
Тульчинский и Варавикова. ↩
Гэри Таубс, «Действительно ли мы знаем, что делает нас здоровыми?» в журнале The New York Times Magazine, 16 сентября 2007 г. ↩
Элленберг 78. ↩
Хафф 91-92. ↩
Хафф 93. ↩
Джонс 157-167. ↩
Хафф 95. ↩
Дэвенпорт 84. ↩
См. показания Нассима Н. Талеба и Ричарда Букстейбера в Конгрессе в работе «Риски финансового моделирования: VaR и экономический кризис» , 111-й Конгресс (2009) 11-67. ↩
Каир 155, 162. ↩