„Garbage In, Garbage Out.“
— Sprichwort aus der frühen Programmierzeit
Unter jedem ML-Modell, jeder Korrelation und jedem datenbasierten Richtlinienempfehlung besteht aus einem oder mehreren Rohdatensätzen. Ganz gleich, wie schön oder die Endprodukte überzeugend oder überzeugend sind, wenn die zugrunde liegenden Daten fehlerhaft, schlecht erfasst oder von geringer Qualität ist, Vorhersage, Visualisierung oder Schlussfolgerung sind ebenfalls gering. die Qualität zu verbessern. Alle, die Modelle auf der Grundlage von Datasets sollten harte Fragen zur Quelle ihrer Daten stellen.
Geräte zur Datenerfassung können Fehlfunktionen aufweisen oder falsch kalibriert sein. Menschen, die Daten erheben, können müde, schelmisch, inkonsistent oder schlecht geschult sein. Menschen machen Fehler und verschiedene Personen können sich auch vernünftigerweise über die Klassifizierung mehrdeutiger Signale streiten. Folglich sind die Qualität und kann die Gültigkeit von Daten leiden und die Daten entsprechen möglicherweise nicht der Realität. Ben Jones, Autor von Avoiding Data pitfalls (Datenfallen vermeiden), nennt dies die Lücke zwischen Daten und Realität und erinnert den Leser daran: „Es geht nicht um Kriminalität, sondern um gemeldete Kriminalität. Es ist nicht die die Anzahl der aufgezeichneten Meteoritenschläge.
Beispiele für Data-Reality-Lücke:
Jones zeichnet Spitzen bei Zeitmessungen in 5-Minuten-Intervallen auf und Gewichtsmessungen in Intervallen von 2,3 kg durchführen, nicht, weil solche Spitzen in der Daten sammeln, aber da menschliche Datensammler im Gegensatz zu Instrumenten die Tendenz , um ihre Zahlen auf die nächsten 0 oder 5 zu runden.1
1985 stellten Joe Farman, Brian Gardiner und Jonathan Shanklin, die für die British Antarctic Survey (BAS) arbeiteten, fest, dass ihre Messungen ein saisonales Loch in der Ozonschicht über der Südhemisphäre zeigten. Das widersprach den NASA-Daten, in denen kein solches Loch verzeichnet war. NASA-Physiker Richard Stolarski untersuchte und fand, dass die Datenverarbeitungssoftware der NASA wurde angenommen, dass die Ozonwerte nie unter einen bestimmten Wert bestimmte Menge und die sehr, sehr niedrigen Ozonwerte, die erkannt wurden, wurden automatisch als unsinnige Ausreißer verworfen.2
Instrumente erleben eine Vielzahl von Fehlermodi, manchmal, Daten sammeln. Adam Ringler et al. stellen in ihrem Artikel „Why Do My Squiggles Look Funny?“ (Warum sehen meine Zickzacklinien komisch aus?) aus dem Jahr 2021 eine Galerie von Seismographenmesswerten bereit, die auf Instrumentenfehler (und die entsprechenden Fehler) zurückzuführen sind.3 Die Aktivität in den Beispielmesswerten entspricht nicht der tatsächlichen seismischen Aktivität.
Für ML-Anwender ist es wichtig, Folgendes zu verstehen:
- Wer hat die Daten erhoben?
- Wie und wann die Daten erhoben wurden und unter welchen Bedingungen
- Empfindlichkeit und Zustand der Messgeräte
- Wie sich Geräteausfälle und menschliche Fehler in einem bestimmten Kontext darstellen können
- Menschliche Tendenzen, Zahlen zu runden und gewünschte Antworten zu liefern
Fast immer gibt es mindestens einen kleinen Unterschied zwischen Daten und der Realität, auch als Grundwahrheit bezeichnet. Diesen Unterschied zu berücksichtigen, ist der Schlüssel zu guten Schlussfolgerungen und fundierte Entscheidungen treffen. Dazu gehören folgende Entscheidungen:
- welche Probleme mit ML gelöst werden können und sollten.
- welche Probleme sich mit ML nicht am besten lösen lassen.
- für welche Probleme noch nicht ausreichend hochwertige Daten vorliegen.
Fragen Sie: Was wird im strengsten und wörtlichsten Sinne durch die Daten vermittelt? Was nicht vermitteln die Daten dabei?
Fehler in den Daten
Neben den Bedingungen der Datenerhebung kann der Datensatz selbst Fehler, Null- oder ungültige Werte enthalten (z. B. negative Konzentrationsmessungen). Crowdsourcing-Daten können besonders chaotisch sind. Die Arbeit mit einem Datensatz unbekannter Qualität kann zu ungenauen Ergebnissen führen.
Häufige Probleme:
- Falsch geschriebene Zeichenfolgenwerte wie Orte, Arten oder Markennamen
- Falsche Umrechnungsfaktoren, Einheiten oder Objekttypen
- Fehlende Werte
- Regelmäßige falsche Klassifizierungen oder falsche Labels
- Nach mathematischen Vorgängen verbleibende signifikante Ziffern, die die tatsächliche Empfindlichkeit eines Instruments überschreiten
Die Bereinigung eines Datensatzes umfasst häufig Entscheidungen zu Null- und fehlenden Werten (ob sie als Nullwerte beibehalten, gelöscht oder durch Nullen ersetzt werden sollen), die Korrektur von Rechtschreibfehlern zu einer einzigen Version, die Korrektur von Einheiten und Umwandlungen usw. Ein fortschrittlicherer Methode besteht darin, fehlende Werte einzuschreiben. Dies wird in Dateneigenschaften im Crashkurs „Machine Learning“.
Stichprobenerhebung, Überlebendenverzerrung und das Problem des Surrogatendpunkts
Die Statistik ermöglicht die gültige und genaue Fortschreibung der Ergebnisse eines einer reinen Zufallsstichprobe an die größere Population. Die unerprobte Brüchigkeit dieser Annahme sowie unausgewogene und unvollständige Trainingsinputs haben zu medienwirksamen Fehlschlägen vieler ML-Anwendungen geführt, einschließlich Modellen, die für die Überprüfung und Prüfung von Lebensläufen verwendet werden. Es hat auch zu Polling-Fehlern und anderen falsche Schlussfolgerungen über demografische Gruppen. In den meisten Kontexten außerhalb KI-generierte Daten, reine Zufallsstichproben. teuer und zu schwer zu beschaffen. Stattdessen werden verschiedene Umgehungslösungen und kostengünstige Proxys verwendet, die verschiedene Quellen von Voreingenommenheit einführen.
Wenn Sie die Methode der Schichtung verwenden möchten, müssen Sie beispielsweise die Prävalenz jedes Schichtungsmerkmals in der größeren Population kennen. Wenn Sie eine Prävalenz annehmen, die tatsächlich falsch ist, sind Ihre Ergebnisse ungenau. Ebenso sind Onlineumfragen selten eine Zufallsstichprobe einer nationalen Bevölkerung, nur eine Stichprobe der Internetnutzer (oft aus mehreren Ländern), die die Umfrage sehen und bereit sind, an der Umfrage teilzunehmen. Diese Gruppe unterscheidet sich wahrscheinlich von einer echten Zufallsstichprobe. Die Fragen in der Umfrage sind nur ein Beispiel für mögliche Fragen. Die Antworten auf diese Fragen lauten: keine Zufallsstichprobe der Befragten tatsächliche Meinungen, sondern nur Meinungen, die die Befragten wohlhaben und die von ihren Meinungen zu erhalten.
Forscher im klinischen Gesundheitswesen stoßen auf ein ähnliches Problem, das sogenannte Surrogat Endpunktproblem. Da es viel zu lange dauert, die Wirkung eines Arzneimittels auf die Lebensdauer von Patienten zu prüfen, verwenden Forscher Proxy-Biomarker, die mit der Lebensdauer in Verbindung gebracht werden, dies aber möglicherweise nicht sind. Der Cholesterinspiegel wird als Ersatzwert verwendet Endpunkt für Herzinfarkte und durch Herz-Kreislauf-Erkrankungen verursachte Todesfälle, wenn ein Medikament senkt den Cholesterinspiegel und verringert vermutlich auch das Risiko von Herzproblemen. Diese Korrelationskette ist jedoch möglicherweise nicht gültig oder die Kausalreihenfolge ist anders als angenommen. Siehe Weintraub et al.: „Die Gefahren von Ersatzendpunkten“, finden Sie weitere Beispiele und Details. Das Gleiche bei ML ist die Proxylabels
Der Mathematiker Abraham Wald hat ein bekanntes Problem bei der Stichprobenerhebung identifiziert. Überlebensverzerrung. Kriegsflugzeuge kehrten mit Einschusslöchern zurück an bestimmten Standorten und nicht an anderen. Das US-Militär wollte die Flugzeuge in den Bereichen mit den meisten Einschusslöchern stärker gepanzern. Die Forschungsgruppe von Wald empfahl jedoch stattdessen, die Panzerung an den Stellen anzubringen, an denen keine Einschusslöcher waren. Es schlussfolgerte, dass seine Datenstichprobe verzerrt war, weil Flugzeuge in Diese Bereiche waren so stark beschädigt, dass sie nicht mehr in die Basis zurückkehren konnten.
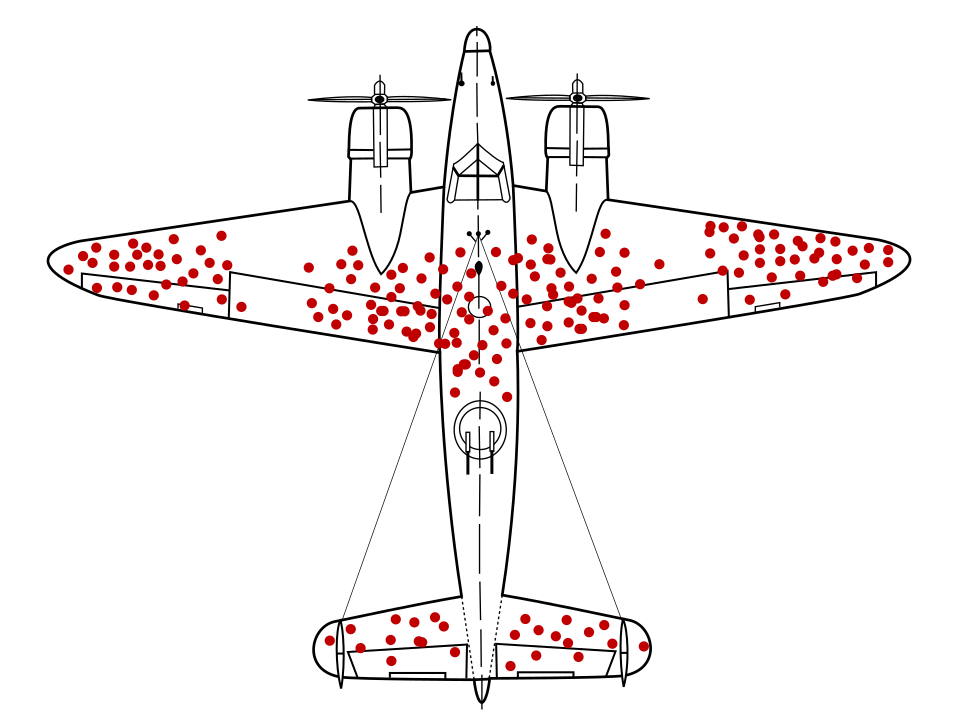
Hatte ein Panzer-Empfehlungsmodell nur mit Diagrammen der Rückkehr Kriegsflugzeuge, ohne Einblick in die Verzerrung der Überlebenden in den Daten, dieses Modell empfohlen hätte, die Bereiche mit mehr Einschusslöchern zu verstärken.
Selbstausleseeffekte können auftreten, wenn sich Testpersonen freiwillig an einer Studie beteiligen. Häftlinge, die sich für ein Programm zur Rückfallprävention anmelden, könnten beispielsweise eine Gruppe darstellen, die weniger wahrscheinlich zukünftige Straftaten begeht als die allgemeine Häftlingspopulation. Das würde die Ergebnisse verfälschen.4
Ein subtileres Stichprobenproblem ist der Erinnerungsfehler, der sich auf die Veränderbarkeit der Erinnerungen von Testpersonen bezieht. 1993 fragte Edward Giovannucci eine Altersgruppe der Frauen, von denen einige an Krebs diagnostiziert wurden, berichten von ihrer bisherigen Ernährung Gewohnheiten. Dieselben Frauen hatten vor ihrer Veröffentlichung an einer Umfrage zu Essgewohnheiten Krebsdiagnosen. Giovannucci stellte fest, dass Frauen ohne Krebsdiagnose ihre Ernährung genau in Erinnerung hatten, Frauen mit Brustkrebs jedoch angaben, mehr Fett zu sich zu nehmen, als sie zuvor angegeben hatten – und so unbewusst eine mögliche (wenn auch falsche) Erklärung für ihre Krebserkrankung lieferten.5
Frag Folgendes:
- Wobei handelt es sich bei einem Dataset eigentlich um eine Stichprobenerhebung?
- Wie viele Ebenen der Stichprobenerhebung gibt es?
- Welche Verzerrung kann auf jeder Ebene der Stichprobenerhebung entstehen?
- Wird die Proxy-Messung verwendet (ob Biomarker, Onlineumfrage oder Aufzählungspunkt) Loch)), die eine tatsächliche Korrelation oder Kausalität zeigt?
- Was könnte bei der Stichprobe und Stichprobenmethode fehlen?
Im Modul „Fairness“ des Intensivkurses zum maschinellen Lernen erfahren Sie, wie Sie zusätzliche Verzerrungsquellen in demografischen Datasets bewerten und beheben können.
Definitionen und Rankings
Definieren Sie Begriffe klar und präzise oder fragen Sie nach klaren und präzisen Definitionen. Dies ist erforderlich, um zu verstehen, welche Datenfunktionen in Betracht gezogen werden und was genau vorhergesagt oder beansprucht wird. Charles Wheelan zeigt in Naked Statistics „the health of US Fertigung“ als Beispiel für einen mehrdeutigen Begriff. Ob die US-amerikanische Fertigung "gesund" hängt ganz davon ab, wie der Begriff definiert ist. Greg IPS Artikel vom März 2011 in The Economist verdeutlicht diese Ambiguität. Wenn der Messwert für „Gesundheit“ ist „Fertigung Ausgabe“ 2011 wurde die Fertigungsindustrie in den USA zunehmend gesunder. Wenn der Messwert „Gesundheit“ als „Beschäftigung in der Fertigung“ definiert ist, war die US-Fertigung jedoch rückläufig.6
Rankings leiden oft unter ähnlichen Problemen, darunter unklare oder unsinnig hohe Gewichtungen verschiedener Komponenten des Rankings, Inkonsistenz der Bewerter und ungültige Optionen. Malcolm Gladwell erwähnt in The New Yorker den Obersten Richter des Michigan Supreme Court, Thomas Brennan, der einmal eine Umfrage an hundert Anwälte schickte und sie bat, zehn juristische Fakultäten nach Qualität zu bewerten, einige davon bekannt, andere nicht. Diese Anwälte setzten die juristische Fakultät der Penn State auf Platz 5, obwohl es zu diesem Zeitpunkt an der Penn State keine juristische Fakultät gab.7 Viele bekannte Rankings enthalten eine ähnlich subjektive Reputationskomponente. Fragen Sie, welche Komponenten in ein Ranking einfließen und warum diese Komponenten eine spezielle Gewichtung zugewiesen.
Kleine Zahlen, große Auswirkungen
Wenn du eine Münze wirfst, ist es nicht überraschend, dass du 100% Kopf oder 100% Zahl bekommst, wenn du eine Münze wirfst zweimal. Es ist auch nicht überraschend, wenn Sie nach dem viermaligen Werfen einer Münze 25 % und dann bei den nächsten vier Würfen 75 % Kopf erhalten. Das ist zwar ein scheinbar enormer Anstieg, der aber fälschlicherweise auf ein Sandwich zurückzuführen sein könnte, das Sie zwischen den Würfen gegessen haben, oder auf einen anderen irrelevanten Faktor. Wenn die Anzahl der Münzwürfe jedoch auf beispielsweise 1.000 oder 2.000 ansteigt, werden große prozentuale Abweichungen von den erwarteten 50 % immer unwahrscheinlicher.
Die Anzahl der Messungen oder Testpersonen in einem Test wird oft als N bezeichnet. Bei großen proportionalen Änderungen ist die Wahrscheinlichkeit, treten in Datasets und Stichproben mit einem niedrigen N auf.
Geben Sie bei einer Analyse oder bei der Dokumentation eines Datensatzes in einer Datenkarte N an, damit andere Personen den Einfluss von Rauschen und Zufälligkeiten berücksichtigen können.
Da die Modellqualität tendenziell mit der Anzahl von Beispielen skaliert, ist ein Dataset mit Ein niedriges N führt tendenziell zu Modellen von geringer Qualität.
Regression auf den Mittelwert
Ebenso unterliegt jede Messung, die zu einem gewissen Grad vom Zufall beeinflusst wird, einem Effekt, der als Regression zum Mittelwert bezeichnet wird. Dies beschreibt, wie die Messung nach einer besonders extremen Messung durchschnittlich weniger extrem oder näher am Mittelwert ist, aufgrund der es unwahrscheinlich ist, dass die extremen Messungen überhaupt stattgefunden haben. Die Der Effekt ist deutlicher, wenn eine besonders über- oder unterdurchschnittliche Gruppe ob diese Gruppe die größten Personen in einem Bevölkerung, die schlechtesten Athleten im Team oder diejenigen mit dem höchsten Schlaganfallrisiko. Die Kinder der größten Menschen sind im Durchschnitt wahrscheinlich kleiner als ihre Eltern, die schlechtesten Athleten erzielen nach einer außergewöhnlich schlechten Saison wahrscheinlich bessere Leistungen und Personen mit dem höchsten Risiko für einen Schlaganfall haben nach jeder Intervention oder Behandlung wahrscheinlich ein reduziertes Risiko, nicht aufgrund von kausalen Faktoren, sondern aufgrund der Eigenschaften und Wahrscheinlichkeiten von Zufälligkeiten.
Eine Möglichkeit, die Auswirkungen der Regression zur Mitte zu verringern, wenn Sie Interventionen oder Behandlungen für eine Gruppe mit überdurchschnittlichen oder unterdurchschnittlichen Werten untersuchen, besteht darin, die Testpersonen in eine Testgruppe und eine Kontrollgruppe zu unterteilen, um kausale Effekte zu isolieren. Im Kontext von ML sollten Sie bei diesem Phänomen besonders auf Modelle achten, die Anomalien oder Ausreißer vorhersagen, z. B.:
- extreme Wetter- oder Temperaturen
- die besten Geschäfte oder Sportler
- die beliebtesten Videos auf einer Website
Wenn die laufenden Vorhersagen eines Modells außergewöhnliche Werte im Laufe der Zeit nicht mit der Realität übereinstimmen, wie etwa die Vorhersage, erfolgreiche Shops oder Videos bleiben auch weiterhin erfolgreich, wenn sie nicht, fragen Sie:
- Könnte die Regression zum Mittelwert das Problem sein?
- Sind die Merkmale mit den höchsten Gewichtungen tatsächlich aussagekräftiger als Merkmale mit niedrigeren Gewichtungen?
- Ist das Erheben von Daten mit dem Grundwert für diese Funktionen, oft null (also eine Kontrollgruppe) die Vorhersagen des Modells ändern?
Verweise
Huff, Darrell. So lügen Sie mit Statistiken. NY: W.W. Norton, 1954.
Jones, Ben. Datenfallen vermeiden. Hoboken, NJ: Wiley, 2020
O'Connor, Cailin und James Owen Weatherall. Das Zeitalter der Fehlinformationen New Haven: Yale UP, 2019.
Ringler, Adam, David Mason, Gabi Laske und Mary Templeton. „Warum sehen meine Striche komisch aus? A Gallery of Compromised Seismic Signals.“ Seismological Research Letters 92 Nr. 6 (Juli 2021): DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Lüscher und Stuart Pocock. „Die Gefahren von Proxy-Endpunkten“ European Heart Journal, Band 36, Nr. 33 (September 2015), S. 2212–2218. DOI: 10.1093/eurheartj/ehv164
Wheelan, Charles. Naked Statistics: Die Daten des Schreckens entfesseln New York: W.W. Norton, 2013
Bildreferenz
„Überlebensverzerrung“. Martin Grandjean, McGeddon und Cameron Moll 2021. CC BY-SA 4.0. Quelle
{kind=link}
-
Jones, 25–29 Jahre ↩
-
O'Connor und Weatherall 22-3. ↩
-
Ringling et al. ↩
-
Wheelan 120 ↩
-
Siddhartha Mukherjee, „Verursachen Smartphones Gehirnkrebs?“ in der New York Times am 13. April 2011. Zitiert in Wheelan 122. ↩
-
Wheelan 39–40. ↩
-
Malcolm Gladwell, „The Order of Things“, in The New Yorker, 14. Februar 2011. Zitiert in Wheelan 56. ↩