"زباله داخل، زباله بیرون."
- ضرب المثل برنامه نویسی اولیه
در زیر هر مدل ML، هر محاسبه همبستگی، و هر توصیه خط مشی مبتنی بر داده، یک یا چند مجموعه داده خام نهفته است. مهم نیست که محصولات نهایی چقدر زیبا یا قابل توجه یا متقاعد کننده باشند، اگر داده های زیربنایی اشتباه، بد جمع آوری شده یا با کیفیت پایین باشد، مدل، پیش بینی، تجسم یا نتیجه گیری حاصل نیز کیفیت پایینی خواهد داشت. هرکسی که مدل ها را بر روی مجموعه داده ها تجسم، تجزیه و تحلیل و آموزش می دهد، باید سوالات سختی در مورد منبع داده های خود بپرسد.
ابزارهای جمعآوری دادهها میتوانند عملکرد نادرست داشته باشند یا بد کالیبره شوند. انسانهای جمعآوری اطلاعات میتوانند خسته، بداخلاق، ناسازگار یا آموزشدیده باشند. مردم اشتباه می کنند و افراد مختلف نیز می توانند به طور منطقی در مورد طبقه بندی سیگنال های مبهم اختلاف نظر داشته باشند. در نتیجه، کیفیت و اعتبار دادهها ممکن است آسیب ببیند و دادهها نتوانند واقعیت را منعکس کنند. بن جونز، نویسنده کتاب اجتناب از دام داده ها ، این شکاف داده-واقعیت را می نامد و به خواننده یادآوری می کند: "این جرم نیست، جرم گزارش شده است. این تعداد برخورد شهاب سنگ نیست، تعداد برخوردهای شهاب سنگ ثبت شده است."
نمونه هایی از شکاف داده-واقعیت:
جونز اندازه گیری های زمانی را در فواصل 5 دقیقه ای و اندازه گیری وزن را در فواصل 5 پوندی نمودار می کند، نه به این دلیل که چنین سنبله هایی در داده ها وجود دارد، بلکه به این دلیل که گردآورندگان داده های انسانی، بر خلاف ابزار، تمایل دارند اعداد خود را به نزدیکترین 0 گرد کنند. یا 5. 1
در سال 1985، جو فارمن، برایان گاردینر و جاناتان شنکلین، که برای بررسی قطب جنوب بریتانیا (BAS) کار میکردند، دریافتند که اندازهگیریهای آنها حاکی از وجود حفره فصلی در لایه اوزون بر روی نیمکره جنوبی است. این با داده های ناسا که چنین حفره ای را ثبت نکرده بود، در تضاد بود. ریچارد استولارسکی، فیزیکدان ناسا، تحقیق کرد و دریافت که نرم افزار پردازش داده ناسا با این فرض طراحی شده است که سطح ازن هرگز نمی تواند از مقدار معینی پایین بیاید، و خوانش های بسیار بسیار پایین ازن که شناسایی شده بود، به طور خودکار به عنوان موارد پرت بی معنی به بیرون پرتاب می شدند. 2
ابزارها انواع مختلفی از حالت های خرابی را تجربه می کنند، گاهی اوقات در حالی که هنوز داده ها را جمع آوری می کنند. آدام رینگلر و همکاران یک گالری از خوانش های لرزه نگار ناشی از خرابی ابزار (و خرابی های مربوطه) را در مقاله 2021 ارائه کنید "چرا Squiggles من خنده دار به نظر می رسند؟" 3 فعالیت در بازخوانی های مثال با فعالیت لرزه ای واقعی مطابقت ندارد.
برای پزشکان ML، مهم است که بدانند:
- چه کسی داده ها را جمع آوری کرد
- چگونه و چه زمانی داده ها و تحت چه شرایطی جمع آوری شده است
- حساسیت و وضعیت ابزارهای اندازه گیری
- خرابی ابزار و خطای انسانی ممکن است در یک زمینه خاص چگونه باشد
- گرایش انسان به گرد کردن اعداد و ارائه پاسخ های مطلوب
تقریباً همیشه، حداقل تفاوت کوچکی بین داده ها و واقعیت وجود دارد که به عنوان حقیقت زمینی نیز شناخته می شود. محاسبه این تفاوت کلید نتیجه گیری خوب و تصمیم گیری صحیح است. این شامل تصمیم گیری است:
- کدام مشکلات را می توان و باید توسط ML حل کرد.
- کدام مسائل با ML به بهترین شکل حل نمی شوند.
- مشکلاتی که هنوز داده های باکیفیت کافی برای حل شدن توسط ML ندارند.
بپرسید: در دقیق ترین و تحت اللفظی ترین معنای، داده ها چه چیزی را منتقل می کنند؟ به همان اندازه مهم، چه چیزی توسط داده ها مخابره نمی شود ؟
کثیفی در داده ها
علاوه بر بررسی شرایط جمع آوری داده ها، خود مجموعه داده می تواند حاوی اشتباهات، خطاها و مقادیر صفر یا نامعتبر باشد (مانند اندازه گیری منفی غلظت). دادههای جمعآوریشده میتوانند بهخصوص کثیف باشند. کار با مجموعه داده با کیفیت ناشناخته می تواند منجر به نتایج نادرست شود.
مسائل رایج عبارتند از:
- املای اشتباه مقادیر رشته، مانند مکان، گونه یا نام تجاری
- تبدیل واحدها، واحدها یا انواع شیء نادرست
- مقادیر از دست رفته
- طبقه بندی نادرست یا برچسب گذاری اشتباه مداوم
- ارقام قابل توجه به جا مانده از عملیات ریاضی که بیش از حساسیت واقعی یک ابزار است
تمیز کردن یک مجموعه داده اغلب شامل انتخاب هایی در مورد مقادیر تهی و از دست رفته (اعم از خالی نگه داشتن آنها، حذف آنها یا جایگزینی 0ها)، تصحیح املا در یک نسخه واحد، اصلاح واحدها و تبدیل ها و غیره است. یک تکنیک پیشرفته تر، نسبت دادن مقادیر از دست رفته است، که در ویژگی های داده در دوره تصادف یادگیری ماشین توضیح داده شده است.
نمونه گیری، سوگیری بقا، و مشکل نقطه پایانی جانشین
آمار به برون یابی معتبر و دقیق نتایج از یک نمونه کاملا تصادفی به جمعیت بزرگتر اجازه می دهد. شکنندگی بررسی نشده این فرض، همراه با ورودیهای آموزشی نامتعادل و ناقص، منجر به خرابیهای مهم بسیاری از برنامههای ML، از جمله مدلهای مورد استفاده برای بررسی رزومهها و پلیس شده است. همچنین منجر به شکست در نظرسنجی ها و سایر نتیجه گیری های اشتباه در مورد گروه های جمعیتی شده است. در بیشتر زمینههای خارج از دادههای مصنوعی تولید شده توسط رایانه، نمونههای تصادفی صرفاً بسیار گران هستند و به دست آوردن آنها بسیار دشوار است. به جای آن از راهحلهای مختلف و پراکسیهای مقرونبهصرفه استفاده میشود که منابع مختلف سوگیری را معرفی میکنند.
به عنوان مثال، برای استفاده از روش نمونه گیری طبقه ای، باید میزان شیوع هر قشر نمونه گیری در جمعیت بزرگتر را بدانید. اگر شیوعی را در واقع نادرست فرض کنید، نتایج شما نادرست خواهد بود. به همین ترتیب، نظرسنجی آنلاین به ندرت نمونه ای تصادفی از یک جمعیت ملی است، اما نمونه ای از جمعیت متصل به اینترنت (اغلب از چندین کشور) است که می بیند و مایل به شرکت در نظرسنجی است. این گروه احتمالاً با یک نمونه تصادفی واقعی متفاوت است. سوالات در نظرسنجی نمونه سوالات احتمالی است. پاسخ به آن سوالات نظرسنجی، مجدداً، یک نمونه تصادفی از نظرات واقعی پاسخ دهندگان نیست، بلکه نمونه ای از نظراتی است که پاسخ دهندگان به راحتی ارائه می دهند، که ممکن است با نظرات واقعی آنها متفاوت باشد.
محققان سلامت بالینی با مسئله مشابهی به نام مشکل نقطه پایانی جایگزین مواجه می شوند. از آنجایی که بررسی اثر دارو بر طول عمر بیمار بسیار طولانی است، محققان از بیومارکرهای پروکسی استفاده می کنند که فرض می شود با طول عمر مرتبط هستند اما ممکن است اینطور نباشند. سطح کلسترول به عنوان یک نقطه پایانی جایگزین برای حملات قلبی و مرگ و میر ناشی از مشکلات قلبی عروقی استفاده می شود: اگر یک دارو سطح کلسترول را کاهش دهد، فرض می شود که خطر ابتلا به مشکلات قلبی را نیز کاهش می دهد. با این حال، آن زنجیره همبستگی ممکن است معتبر نباشد، یا اینکه ترتیب علیت ممکن است غیر از آنچه محقق فرض میکند باشد. برای مثالها و جزئیات بیشتر به Weintraub و همکاران، "خطرات نقاط پایانی جایگزین" مراجعه کنید. وضعیت معادل در ML وضعیت برچسب های پروکسی است.
آبراهام والد، ریاضیدان، مسئله نمونهگیری دادهای را که امروزه به عنوان سوگیری بقا شناخته میشود، شناسایی کرد. هواپیماهای جنگی با سوراخهای گلوله در مکانهای خاص و نه در مکانهای دیگر بازمیگشتند. ارتش ایالات متحده می خواست زره بیشتری به هواپیماها در مناطقی که دارای بیشترین سوراخ گلوله هستند اضافه کند، اما گروه تحقیقاتی والد به جای آن توصیه کرد که زره به مناطق بدون گلوله اضافه شود. آنها به درستی استنباط کردند که نمونه دادههایشان کج شده است، زیرا هواپیماهای شلیک شده در آن مناطق بهقدری آسیب دیدهاند که قادر به بازگشت به پایگاه نیستند.
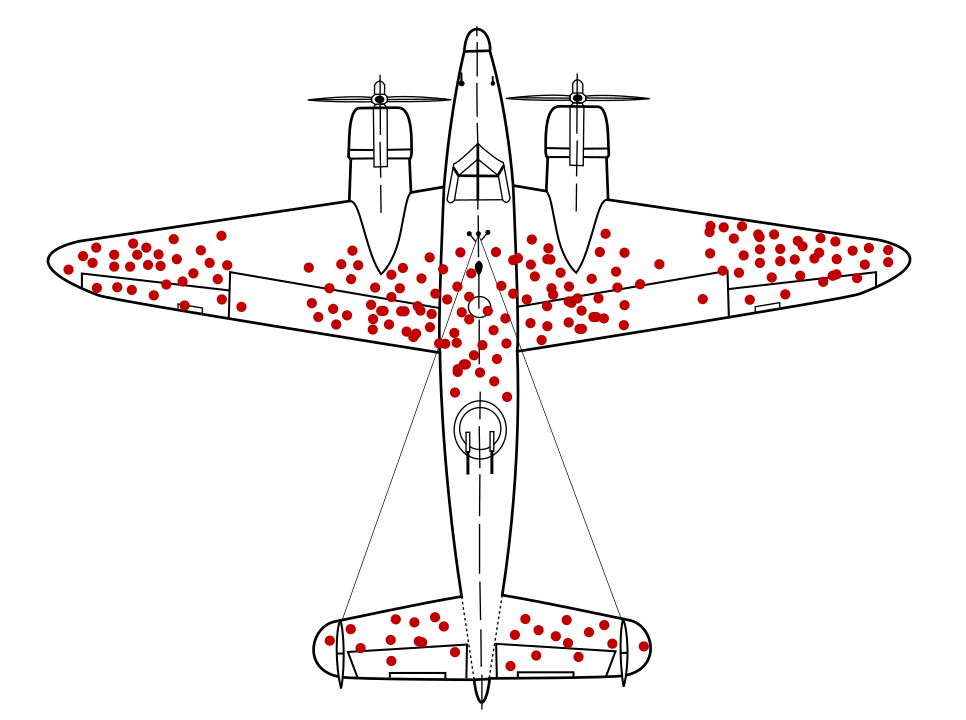
اگر یک مدل توصیهکننده زرهی صرفاً بر روی نمودارهای هواپیماهای جنگی در حال بازگشت آموزش داده میشد، بدون اینکه بینشی در مورد سوگیری بقای موجود در دادهها وجود داشته باشد، آن مدل تقویت مناطق با سوراخهای گلوله بیشتری را توصیه میکرد.
سوگیری انتخاب خود می تواند از داوطلبان داوطلب شرکت در یک مطالعه ناشی شود. برای مثال، زندانیانی که انگیزه ثبت نام در برنامه کاهش تکرار جرم را دارند، می توانند جمعیتی را نشان دهند که احتمال ارتکاب جرایم در آینده کمتر از جمعیت عمومی زندانیان است. این نتایج را منحرف می کند. 4
یک مشکل نمونه برداری ظریف تر، سوگیری یادآوری است که شامل شکل پذیری خاطرات سوژه های انسانی است. در سال 1993، ادوارد جیووانوچی از یک گروه هم سن و سال از زنان که برخی از آنها به سرطان مبتلا شده بودند، درباره عادات غذایی گذشته خود پرسید. همان زنان قبل از تشخیص سرطان، در مورد عادات غذایی خود نظرسنجی انجام داده بودند. چیزی که جیووانوچی کشف کرد این بود که زنان بدون تشخیص سرطان رژیم غذایی خود را به طور دقیق به یاد می آورند، اما زنان مبتلا به سرطان سینه گزارش دادند که چربی بیشتری از آنچه قبلاً گزارش کرده بودند مصرف می کردند - ناخودآگاه توضیحی ممکن (هر چند نادرست) برای سرطان خود ارائه کردند. 5
بپرسید:
- در واقع نمونهگیری مجموعه داده چیست؟
- چند سطح نمونه گیری وجود دارد؟
- چه سوگیری ممکن است در هر سطح از نمونه گیری معرفی شود؟
- آیا اندازه گیری پراکسی استفاده شده (اعم از نشانگر زیستی یا نظرسنجی آنلاین یا سوراخ گلوله) همبستگی یا علیت واقعی را نشان می دهد؟
- چه چیزی ممکن است از نمونه و روش نمونه برداری کم باشد؟
ماژول انصاف در دوره آموزشی تصادفی یادگیری ماشین روشهایی را برای ارزیابی و کاهش منابع اضافی سوگیری در مجموعه دادههای جمعیتی پوشش میدهد.
تعاریف و رتبه بندی
اصطلاحات را به طور واضح و دقیق تعریف کنید یا در مورد تعاریف واضح و دقیق بپرسید. این برای درک اینکه چه ویژگی های داده ای در حال بررسی هستند و دقیقاً چه چیزی پیش بینی یا ادعا می شود ضروری است. چارلز ویلان، در آمار برهنه ، "سلامت تولید ایالات متحده" را به عنوان مثالی از یک اصطلاح مبهم ارائه می دهد. اینکه آیا تولید ایالات متحده "سالم" است یا نه، کاملاً به نحوه تعریف این اصطلاح بستگی دارد. مقاله مارس 2011 گرگ آیپ در اکونومیست این ابهام را نشان می دهد. اگر معیار "سلامت" "بازده تولیدی" باشد، در سال 2011، تولید ایالات متحده به طور فزاینده ای سالم بود. اگر معیار «سلامت» به عنوان «شغل تولیدی» تعریف شود، تولید ایالات متحده در حال کاهش بود. 6
رتبهبندیها اغلب از مسائل مشابهی رنج میبرند، از جمله وزنهای مبهم یا بیمعنی دادهشده به اجزای مختلف رتبهبندی، ناهماهنگی رتبهبندیها و گزینههای نامعتبر. مالکوم گلدول، که در نیویورکر می نویسد، از یک قاضی دادگاه عالی میشیگان، توماس برنان نام می برد که یک بار نظرسنجی را برای صد وکیل فرستاد و از آنها خواست که ده دانشکده حقوق را از نظر کیفیت رتبه بندی کنند، برخی معروف و برخی نه. آن وکلا دانشکده حقوق ایالت پن را تقریباً در جایگاه پنجم قرار دادند، اگرچه در زمان نظرسنجی، ایالت پن دانشکده حقوق نداشت. 7 بسیاری از رتبه بندی های شناخته شده شامل یک مؤلفه شهرت ذهنی مشابه هستند. بپرسید چه مؤلفههایی در رتبهبندی قرار میگیرند، و چرا به آن مؤلفهها وزن خاص خود اختصاص داده شده است.
اعداد کوچک و جلوه های بزرگ
اگر یک سکه را دو بار ورق بزنید، تعجب آور نیست که 100% سر یا 100% دم داشته باشید. همچنین تعجب آور نیست که پس از چهار بار ورق زدن یک سکه، 25 درصد سر به دست آوریم، سپس برای چهار ورق بعدی، 75 درصد سر به دست آوریم، اگرچه این افزایش ظاهراً بسیار زیاد را نشان می دهد (که به اشتباه می تواند به یک ساندویچ خورده شده بین مجموعه سکه ها نسبت داده شود. یا هر عامل جعلی دیگر). اما با افزایش تعداد ورقهای سکه، مثلاً به 1000 یا 2000، درصد زیادی انحراف از 50 درصد مورد انتظار بهطور محتمل ناپدید میشود.
تعداد اندازه گیری ها یا افراد آزمایشی در یک مطالعه اغلب به عنوان N نامیده می شود. تغییرات نسبی بزرگ به دلیل شانس بسیار بیشتر در مجموعه داده ها و نمونه هایی با N کم رخ می دهد.
هنگام انجام یک تجزیه و تحلیل یا مستندسازی یک مجموعه داده در کارت داده، N را مشخص کنید تا افراد دیگر بتوانند تأثیر نویز و تصادفی بودن را در نظر بگیرند.
از آنجایی که کیفیت مدل با تعداد مثال ها مقیاس می شود، مجموعه داده با N پایین تمایل به مدل های با کیفیت پایین دارد.
رگرسیون به میانگین
به طور مشابه، هر اندازهگیری که تأثیری از شانس داشته باشد، تحت تأثیری قرار میگیرد که به عنوان رگرسیون به میانگین شناخته میشود. این توضیح میدهد که چگونه اندازهگیری پس از یک اندازهگیری شدید، به طور متوسط، به احتمال زیاد کمتر افراطی یا نزدیکتر به میانگین است، زیرا در وهله اول چقدر بعید بود که اندازهگیری شدید اتفاق بیفتد. اگر یک گروه مخصوصاً بالاتر از متوسط یا کمتر از میانگین برای مشاهده انتخاب شده باشد، چه آن گروه بلند قدترین افراد در یک جمعیت، بدترین ورزشکاران یک تیم یا آنهایی که بیشتر در معرض خطر سکته مغزی هستند، تأثیر بیشتر می شود. فرزندان قدبلندترین افراد به طور متوسط احتمالاً کوتاهتر از والدین خود هستند، بدترین ورزشکاران احتمالاً پس از یک فصل فوقالعاده بد عملکرد بهتری خواهند داشت و آنهایی که بیشتر در معرض خطر سکته مغزی هستند احتمالاً پس از هر مداخله یا درمانی خطر کمتری را نشان میدهند. نه به دلیل عوامل ایجاد کننده بلکه به دلیل ویژگی ها و احتمالات تصادفی.
یکی از روشهای کاهش اثرات رگرسیون به میانگین، هنگام بررسی مداخلات یا درمانها برای یک گروه بالاتر از متوسط یا کمتر از میانگین، تقسیم افراد به یک گروه مطالعه و یک گروه کنترل به منظور جداسازی اثرات مسبب است. در زمینه ML، این پدیده نشان می دهد که توجه بیشتری به هر مدلی که مقادیر استثنایی یا پرت را پیش بینی می کند، مانند:
- آب و هوا یا درجه حرارت شدید
- فروشگاه ها یا ورزشکاران با بهترین عملکرد
- محبوب ترین ویدیوها در یک وب سایت
اگر پیشبینیهای مداوم یک مدل از این مقادیر استثنایی در طول زمان با واقعیت مطابقت ندارد، برای مثال پیشبینی اینکه یک فروشگاه یا ویدیوی بسیار موفق همچنان موفق خواهد بود در حالی که در واقع اینطور نیست، بپرسید:
- آیا بازگشت به میانگین می تواند مسئله باشد؟
- آیا ویژگی هایی که بیشترین وزن را دارند در واقع بیشتر از ویژگی هایی با وزن کمتر پیش بینی می کنند؟
- آیا جمعآوری دادههایی که ارزش پایه برای آن ویژگیها، اغلب صفر (عملاً یک گروه کنترل) دارند، پیشبینیهای مدل را تغییر میدهد؟
مراجع
هاف، دارل. چگونه با آمار دروغ بگوییم نیویورک: WW نورتون، 1954.
جونز، بن. اجتناب از دام داده ها هوبوکن، نیوجرسی: وایلی، 2020.
اوکانر، کیلین و جیمز اوون وترال. عصر اطلاعات غلط New Haven: Yale UP، 2019.
رینگلر، آدام، دیوید میسون، گابی لاسکه و مری تمپلتون. "چرا Squiggles من خنده دار به نظر می رسند؟ گالری از سیگنال های لرزه ای در معرض خطر." نامه تحقیقات زلزله شناسی 92 شماره. 6 (ژوئیه 2021). DOI: 10.1785/0220210094
واینتراب، ویلیام اس، توماس اف. لوشر، و استوارت پوکاک. "خطرات نقاط پایانی جایگزین." مجله قلب اروپا 36 شماره. 33 (سپتامبر 2015): 2212-2218. DOI: 10.1093/eurheartj/ehv164
ویلن، چارلز. آمار برهنه: حذف ترس از داده ها. نیویورک: WW نورتون، 2013
مرجع تصویر
"سوگیری بقا." Martin Grandjean، McGeddon، and Cameron Moll 2021. CC BY-SA 4.0. منبع
{kind=link}
جونز 25-29. ↩
O'Connor و Weatherall 22-3. ↩
رینگلینگ و همکاران ↩
Wheelan 120. ↩
سیذارتا موکرجی، "آیا تلفن های همراه باعث سرطان مغز می شوند؟" در نیویورک تایمز، 13 آوریل 2011. نقل شده در Wheelan 122. ↩
ویلان 39-40. ↩
مالکوم گلدول، "نظم اشیا" ، در نیویورکر 14 فوریه 2011. نقل شده در Wheelan 56. ↩
"زباله داخل، زباله بیرون."
- ضرب المثل برنامه نویسی اولیه
در زیر هر مدل ML، هر محاسبه همبستگی، و هر توصیه خط مشی مبتنی بر داده، یک یا چند مجموعه داده خام نهفته است. مهم نیست که محصولات نهایی چقدر زیبا یا قابل توجه یا متقاعد کننده باشند، اگر داده های زیربنایی اشتباه، بد جمع آوری شده یا با کیفیت پایین باشد، مدل، پیش بینی، تجسم یا نتیجه گیری حاصل نیز کیفیت پایینی خواهد داشت. هرکسی که مدل ها را بر روی مجموعه داده ها تجسم، تجزیه و تحلیل و آموزش می دهد، باید سوالات سختی در مورد منبع داده های خود بپرسد.
ابزارهای جمعآوری دادهها میتوانند عملکرد نادرست داشته باشند یا بد کالیبره شوند. انسانهای جمعآوری اطلاعات میتوانند خسته، بداخلاق، ناسازگار یا آموزشدیده باشند. مردم اشتباه می کنند و افراد مختلف نیز می توانند به طور منطقی در مورد طبقه بندی سیگنال های مبهم اختلاف نظر داشته باشند. در نتیجه، کیفیت و اعتبار دادهها ممکن است آسیب ببیند و دادهها نتوانند واقعیت را منعکس کنند. بن جونز، نویسنده کتاب اجتناب از دام داده ها ، این شکاف داده-واقعیت را می نامد و به خواننده یادآوری می کند: "این جرم نیست، جرم گزارش شده است. این تعداد برخورد شهاب سنگ نیست، تعداد برخوردهای شهاب سنگ ثبت شده است."
نمونه هایی از شکاف داده-واقعیت:
جونز اندازه گیری های زمانی را در فواصل 5 دقیقه ای و اندازه گیری وزن را در فواصل 5 پوندی نمودار می کند، نه به این دلیل که چنین سنبله هایی در داده ها وجود دارد، بلکه به این دلیل که گردآورندگان داده های انسانی، بر خلاف ابزار، تمایل دارند اعداد خود را به نزدیکترین 0 گرد کنند. یا 5. 1
در سال 1985، جو فارمن، برایان گاردینر و جاناتان شنکلین، که برای بررسی قطب جنوب بریتانیا (BAS) کار میکردند، دریافتند که اندازهگیریهای آنها حاکی از وجود حفره فصلی در لایه اوزون بر روی نیمکره جنوبی است. این با داده های ناسا که چنین حفره ای را ثبت نکرده بود، در تضاد بود. ریچارد استولارسکی، فیزیکدان ناسا، تحقیق کرد و دریافت که نرم افزار پردازش داده ناسا با این فرض طراحی شده است که سطح ازن هرگز نمی تواند از مقدار معینی پایین بیاید، و خوانش های بسیار بسیار پایین ازن که شناسایی شده بود، به طور خودکار به عنوان موارد پرت بی معنی به بیرون پرتاب می شدند. 2
ابزارها انواع مختلفی از حالت های خرابی را تجربه می کنند، گاهی اوقات در حالی که هنوز داده ها را جمع آوری می کنند. آدام رینگلر و همکاران یک گالری از خوانش های لرزه نگار ناشی از خرابی ابزار (و خرابی های مربوطه) را در مقاله 2021 ارائه کنید "چرا Squiggles من خنده دار به نظر می رسند؟" 3 فعالیت در بازخوانی های مثال با فعالیت لرزه ای واقعی مطابقت ندارد.
برای پزشکان ML، مهم است که بدانند:
- چه کسی داده ها را جمع آوری کرد
- چگونه و چه زمانی داده ها و تحت چه شرایطی جمع آوری شده است
- حساسیت و وضعیت ابزارهای اندازه گیری
- خرابی ابزار و خطای انسانی ممکن است در یک زمینه خاص چگونه باشد
- گرایش انسان به گرد کردن اعداد و ارائه پاسخ های مطلوب
تقریباً همیشه، حداقل تفاوت کوچکی بین داده ها و واقعیت وجود دارد که به عنوان حقیقت زمینی نیز شناخته می شود. محاسبه این تفاوت کلید نتیجه گیری خوب و تصمیم گیری صحیح است. این شامل تصمیم گیری است:
- کدام مشکلات را می توان و باید توسط ML حل کرد.
- کدام مسائل با ML به بهترین شکل حل نمی شوند.
- مشکلاتی که هنوز داده های باکیفیت کافی برای حل شدن توسط ML ندارند.
بپرسید: در دقیق ترین و تحت اللفظی ترین معنای، داده ها چه چیزی را منتقل می کنند؟ به همان اندازه مهم، چه چیزی توسط داده ها مخابره نمی شود ؟
کثیفی در داده ها
علاوه بر بررسی شرایط جمع آوری داده ها، خود مجموعه داده می تواند حاوی اشتباهات، خطاها و مقادیر صفر یا نامعتبر باشد (مانند اندازه گیری منفی غلظت). دادههای جمعآوریشده میتوانند بهخصوص کثیف باشند. کار با مجموعه داده با کیفیت ناشناخته می تواند منجر به نتایج نادرست شود.
مسائل رایج عبارتند از:
- املای اشتباه مقادیر رشته، مانند مکان، گونه یا نام تجاری
- تبدیل واحدها، واحدها یا انواع شیء نادرست
- مقادیر از دست رفته
- طبقه بندی نادرست یا برچسب گذاری اشتباه مداوم
- ارقام قابل توجه به جا مانده از عملیات ریاضی که بیش از حساسیت واقعی یک ابزار است
تمیز کردن یک مجموعه داده اغلب شامل انتخاب هایی در مورد مقادیر تهی و از دست رفته (اعم از خالی نگه داشتن آنها، حذف آنها یا جایگزینی 0ها)، تصحیح املا در یک نسخه واحد، اصلاح واحدها و تبدیل ها و غیره است. یک تکنیک پیشرفته تر، نسبت دادن مقادیر از دست رفته است، که در ویژگی های داده در دوره تصادف یادگیری ماشین توضیح داده شده است.
نمونه گیری، سوگیری بقا، و مشکل نقطه پایانی جانشین
آمار به برون یابی معتبر و دقیق نتایج از یک نمونه کاملا تصادفی به جمعیت بزرگتر اجازه می دهد. شکنندگی بررسی نشده این فرض، همراه با ورودیهای آموزشی نامتعادل و ناقص، منجر به خرابیهای مهم بسیاری از برنامههای ML، از جمله مدلهای مورد استفاده برای بررسی رزومهها و پلیس شده است. همچنین منجر به شکست در نظرسنجی ها و سایر نتیجه گیری های اشتباه در مورد گروه های جمعیتی شده است. در بیشتر زمینههای خارج از دادههای مصنوعی تولید شده توسط رایانه، نمونههای تصادفی صرفاً بسیار گران هستند و بدست آوردن آنها بسیار دشوار است. به جای آن از راهحلهای مختلف و پراکسیهای مقرونبهصرفه استفاده میشود که منابع مختلف سوگیری را معرفی میکنند.
به عنوان مثال، برای استفاده از روش نمونه گیری طبقه ای، باید میزان شیوع هر قشر نمونه گیری در جمعیت بزرگتر را بدانید. اگر شیوعی را در واقع نادرست فرض کنید، نتایج شما نادرست خواهد بود. به همین ترتیب، نظرسنجی آنلاین به ندرت نمونه ای تصادفی از یک جمعیت ملی است، اما نمونه ای از جمعیت متصل به اینترنت (اغلب از چندین کشور) است که می بیند و مایل به شرکت در نظرسنجی است. این گروه احتمالاً با یک نمونه تصادفی واقعی متفاوت است. سوالات در نظرسنجی نمونه سوالات احتمالی است. پاسخ به آن سوالات نظرسنجی، مجدداً، یک نمونه تصادفی از نظرات واقعی پاسخ دهندگان نیست، بلکه نمونه ای از نظراتی است که پاسخ دهندگان به راحتی ارائه می دهند، که ممکن است با نظرات واقعی آنها متفاوت باشد.
محققان سلامت بالینی با مسئله مشابهی به نام مشکل نقطه پایانی جایگزین مواجه می شوند. از آنجایی که بررسی اثر دارو بر طول عمر بیمار بسیار طولانی است، محققان از بیومارکرهای پروکسی استفاده می کنند که فرض می شود با طول عمر مرتبط هستند اما ممکن است اینطور نباشند. سطح کلسترول به عنوان یک نقطه پایانی جایگزین برای حملات قلبی و مرگ و میر ناشی از مشکلات قلبی عروقی استفاده می شود: اگر یک دارو سطح کلسترول را کاهش دهد، فرض می شود که خطر ابتلا به مشکلات قلبی را نیز کاهش می دهد. با این حال، آن زنجیره همبستگی ممکن است معتبر نباشد، یا اینکه ترتیب علیت ممکن است غیر از آنچه محقق فرض میکند باشد. برای مثالها و جزئیات بیشتر به Weintraub و همکاران، "خطرات نقاط پایانی جایگزین" مراجعه کنید. وضعیت معادل در ML وضعیت برچسب های پروکسی است.
آبراهام والد، ریاضیدان، مسئله نمونهگیری دادهای را که امروزه به عنوان سوگیری بقا شناخته میشود، شناسایی کرد. هواپیماهای جنگی با سوراخهای گلوله در مکانهای خاص و نه در مکانهای دیگر بازمیگشتند. ارتش ایالات متحده می خواست زره بیشتری به هواپیماها در مناطقی که دارای بیشترین سوراخ گلوله هستند اضافه کند، اما گروه تحقیقاتی والد به جای آن توصیه کرد که زره به مناطق بدون گلوله اضافه شود. آنها به درستی استنباط کردند که نمونه دادههایشان کج شده است، زیرا هواپیماهای شلیک شده در آن مناطق بهقدری آسیب دیدهاند که قادر به بازگشت به پایگاه نیستند.
اگر یک مدل توصیهکننده زرهی صرفاً بر روی نمودارهای هواپیماهای جنگی در حال بازگشت آموزش داده میشد، بدون اینکه بینشی در مورد سوگیری بقای موجود در دادهها وجود داشته باشد، آن مدل تقویت مناطق با سوراخهای گلوله بیشتری را توصیه میکرد.
سوگیری انتخاب خود می تواند از داوطلبان داوطلب شرکت در یک مطالعه ناشی شود. برای مثال، زندانیانی که انگیزه ثبت نام در برنامه کاهش تکرار جرم را دارند، می توانند جمعیتی را نشان دهند که احتمال ارتکاب جرایم در آینده کمتر از جمعیت عمومی زندانیان است. این نتایج را منحرف می کند. 4
یک مشکل نمونه برداری ظریف تر، سوگیری یادآوری است که شامل شکل پذیری خاطرات سوژه های انسانی است. در سال 1993، ادوارد جیووانوچی از یک گروه هم سن و سال از زنان که برخی از آنها به سرطان مبتلا شده بودند، درباره عادات غذایی گذشته خود پرسید. همان زنان قبل از تشخیص سرطان، در مورد عادات غذایی خود نظرسنجی انجام داده بودند. چیزی که جیووانوچی کشف کرد این بود که زنان بدون تشخیص سرطان رژیم غذایی خود را به طور دقیق به یاد می آورند، اما زنان مبتلا به سرطان سینه گزارش دادند که چربی بیشتری از آنچه قبلاً گزارش کرده بودند مصرف می کردند - ناخودآگاه توضیحی ممکن (هر چند نادرست) برای سرطان خود ارائه کردند. 5
بپرسید:
- در واقع نمونهگیری مجموعه داده چیست؟
- چند سطح نمونه گیری وجود دارد؟
- چه سوگیری ممکن است در هر سطح از نمونه گیری معرفی شود؟
- آیا اندازه گیری پراکسی استفاده شده (اعم از نشانگر زیستی یا نظرسنجی آنلاین یا سوراخ گلوله) همبستگی یا علیت واقعی را نشان می دهد؟
- چه چیزی ممکن است از نمونه و روش نمونه برداری کم باشد؟
ماژول انصاف در دوره آموزشی تصادفی یادگیری ماشین روشهایی را برای ارزیابی و کاهش منابع اضافی سوگیری در مجموعه دادههای جمعیتی پوشش میدهد.
تعاریف و رتبه بندی
اصطلاحات را به طور واضح و دقیق تعریف کنید یا در مورد تعاریف واضح و دقیق بپرسید. این برای درک اینکه چه ویژگی های داده ای در حال بررسی هستند و دقیقاً چه چیزی پیش بینی یا ادعا می شود ضروری است. چارلز ویلان، در آمار برهنه ، "سلامت تولید ایالات متحده" را به عنوان مثالی از یک اصطلاح مبهم ارائه می دهد. اینکه آیا تولید ایالات متحده "سالم" است یا نه، کاملاً به نحوه تعریف این اصطلاح بستگی دارد. مقاله مارس 2011 گرگ آیپ در اکونومیست این ابهام را نشان می دهد. اگر معیار "سلامت" "بازده تولیدی" باشد، در سال 2011، تولید ایالات متحده به طور فزاینده ای سالم بود. اگر معیار «سلامت» به عنوان «شغل تولیدی» تعریف شود، تولید ایالات متحده در حال کاهش بود. 6
رتبهبندیها اغلب از مسائل مشابهی رنج میبرند، از جمله وزنهای مبهم یا بیمعنی دادهشده به اجزای مختلف رتبهبندی، ناهماهنگی رتبهبندیها و گزینههای نامعتبر. مالکوم گلدول، که در نیویورکر می نویسد، از یک قاضی دادگاه عالی میشیگان، توماس برنان نام می برد که یک بار نظرسنجی را برای صد وکیل فرستاد و از آنها خواست که ده دانشکده حقوق را از نظر کیفیت رتبه بندی کنند، برخی معروف و برخی نه. آن وکلا دانشکده حقوق ایالت پن را تقریباً در جایگاه پنجم قرار دادند، اگرچه در زمان نظرسنجی، ایالت پن دانشکده حقوق نداشت. 7 بسیاری از رتبه بندی های شناخته شده شامل یک مؤلفه شهرت ذهنی مشابه هستند. بپرسید چه مؤلفههایی در رتبهبندی قرار میگیرند، و چرا به آن مؤلفهها وزن خاص خود اختصاص داده شده است.
اعداد کوچک و جلوه های بزرگ
اگر یک سکه را دو بار ورق بزنید، تعجب آور نیست که 100% سر یا 100% دم داشته باشید. همچنین تعجب آور نیست که پس از چهار بار ورق زدن یک سکه، 25 درصد سر به دست آوریم، سپس برای چهار ورق بعدی، 75 درصد سر به دست آوریم، اگرچه این افزایش ظاهراً بسیار زیاد را نشان می دهد (که به اشتباه می تواند به یک ساندویچ خورده شده بین مجموعه سکه ها نسبت داده شود. یا هر عامل جعلی دیگر). اما با افزایش تعداد ورقهای سکه، مثلاً به 1000 یا 2000، درصد زیادی انحراف از 50 درصد مورد انتظار بهطور محتمل ناپدید میشود.
تعداد اندازه گیری ها یا افراد آزمایشی در یک مطالعه اغلب به عنوان N نامیده می شود. تغییرات نسبی بزرگ به دلیل شانس بسیار بیشتر در مجموعه داده ها و نمونه هایی با N کم رخ می دهد.
هنگام انجام یک تجزیه و تحلیل یا مستندسازی یک مجموعه داده در کارت داده، N را مشخص کنید تا افراد دیگر بتوانند تأثیر نویز و تصادفی بودن را در نظر بگیرند.
از آنجایی که کیفیت مدل با تعداد مثال ها مقیاس می شود، مجموعه داده با N پایین تمایل به مدل های با کیفیت پایین دارد.
رگرسیون به میانگین
به طور مشابه، هر اندازهگیری که تأثیری از شانس داشته باشد، تحت تأثیری قرار میگیرد که به عنوان رگرسیون به میانگین شناخته میشود. این توضیح میدهد که چگونه اندازهگیری پس از یک اندازهگیری شدید، به طور متوسط، به احتمال زیاد کمتر افراطی یا نزدیکتر به میانگین است، زیرا در وهله اول چقدر بعید بود که اندازهگیری شدید اتفاق بیفتد. اگر یک گروه مخصوصاً بالاتر از متوسط یا کمتر از میانگین برای مشاهده انتخاب شده باشد، چه آن گروه بلند قدترین افراد در یک جمعیت، بدترین ورزشکاران یک تیم یا آنهایی که بیشتر در معرض خطر سکته مغزی هستند، تأثیر بیشتر می شود. فرزندان قدبلندترین افراد به طور متوسط احتمالاً کوتاهتر از والدین خود هستند، بدترین ورزشکاران احتمالاً پس از یک فصل فوقالعاده بد عملکرد بهتری خواهند داشت و آنهایی که بیشتر در معرض خطر سکته مغزی هستند احتمالاً پس از هر مداخله یا درمانی خطر کمتری را نشان میدهند. نه به دلیل عوامل ایجاد کننده بلکه به دلیل ویژگی ها و احتمالات تصادفی.
یکی از روشهای کاهش اثرات رگرسیون به میانگین، هنگام بررسی مداخلات یا درمانها برای یک گروه بالاتر از متوسط یا کمتر از میانگین، تقسیم افراد به یک گروه مطالعه و یک گروه کنترل به منظور جداسازی اثرات مسبب است. در زمینه ML، این پدیده نشان می دهد که توجه بیشتری به هر مدلی که مقادیر استثنایی یا پرت را پیش بینی می کند، مانند:
- آب و هوا یا درجه حرارت شدید
- فروشگاه ها یا ورزشکاران با بهترین عملکرد
- محبوب ترین ویدیوها در یک وب سایت
اگر پیشبینیهای مداوم یک مدل از این مقادیر استثنایی در طول زمان با واقعیت مطابقت ندارد، برای مثال پیشبینی اینکه یک فروشگاه یا ویدیوی بسیار موفق همچنان موفق خواهد بود در حالی که در واقع اینطور نیست، بپرسید:
- آیا بازگشت به میانگین می تواند مسئله باشد؟
- آیا ویژگی هایی که بیشترین وزن را دارند در واقع بیشتر از ویژگی هایی با وزن کمتر پیش بینی می کنند؟
- آیا جمعآوری دادههایی که ارزش پایه برای آن ویژگیها، اغلب صفر (عملاً یک گروه کنترل) دارند، پیشبینیهای مدل را تغییر میدهد؟
مراجع
هاف، دارل. چگونه با آمار دروغ بگوییم نیویورک: WW نورتون، 1954.
جونز، بن. اجتناب از دام داده ها هوبوکن، نیوجرسی: وایلی، 2020.
اوکانر، کیلین و جیمز اوون وترال. عصر اطلاعات غلط New Haven: Yale UP، 2019.
رینگلر، آدام، دیوید میسون، گابی لاسکه و مری تمپلتون. "چرا Squiggles من خنده دار به نظر می رسند؟ گالری از سیگنال های لرزه ای در معرض خطر." نامه تحقیقات زلزله شناسی 92 شماره. 6 (ژوئیه 2021). DOI: 10.1785/0220210094
واینتراب، ویلیام اس، توماس اف. لوشر، و استوارت پوکاک. "خطرات نقاط پایانی جایگزین." مجله قلب اروپا 36 شماره. 33 (سپتامبر 2015): 2212-2218. DOI: 10.1093/eurheartj/ehv164
ویلن، چارلز. آمار برهنه: حذف ترس از داده ها. نیویورک: WW نورتون، 2013
مرجع تصویر
"سوگیری بقا." Martin Grandjean، McGeddon، and Cameron Moll 2021. CC BY-SA 4.0. منبع
جونز 25-29. ↩
O'Connor و Weatherall 22-3. ↩
رینگلینگ و همکاران ↩
Wheelan 120. ↩
سیذارتا موکرجی، "آیا تلفن های همراه باعث سرطان مغز می شوند؟" در نیویورک تایمز، 13 آوریل 2011. نقل شده در Wheelan 122. ↩
ویلان 39-40. ↩
مالکوم گلدول، "نظم اشیا" ، در نیویورکر 14 فوریه 2011. نقل شده در Wheelan 56. ↩
"زباله داخل، زباله بیرون."
- ضرب المثل برنامه نویسی اولیه
در زیر هر مدل ML، هر محاسبه همبستگی، و هر توصیه خط مشی مبتنی بر داده، یک یا چند مجموعه داده خام نهفته است. مهم نیست که محصولات نهایی چقدر زیبا یا قابل توجه یا متقاعد کننده باشند، اگر داده های زیربنایی اشتباه، بد جمع آوری شده یا با کیفیت پایین باشد، مدل، پیش بینی، تجسم یا نتیجه گیری حاصل نیز کیفیت پایینی خواهد داشت. هرکسی که مدل ها را بر روی مجموعه داده ها تجسم، تجزیه و تحلیل و آموزش می دهد، باید سوالات سختی در مورد منبع داده های خود بپرسد.
ابزارهای جمعآوری دادهها میتوانند عملکرد نادرست داشته باشند یا بد کالیبره شوند. انسانهای جمعآوری اطلاعات میتوانند خسته، بداخلاق، ناسازگار یا آموزشدیده باشند. مردم اشتباه می کنند و افراد مختلف نیز می توانند به طور منطقی در مورد طبقه بندی سیگنال های مبهم اختلاف نظر داشته باشند. در نتیجه، کیفیت و اعتبار دادهها ممکن است آسیب ببیند و دادهها نتوانند واقعیت را منعکس کنند. بن جونز، نویسنده کتاب اجتناب از دام داده ها ، این شکاف داده-واقعیت را می نامد و به خواننده یادآوری می کند: "این جرم نیست، جرم گزارش شده است. این تعداد برخورد شهاب سنگ نیست، تعداد برخوردهای شهاب سنگ ثبت شده است."
نمونه هایی از شکاف داده-واقعیت:
جونز اندازه گیری های زمانی را در فواصل 5 دقیقه ای و اندازه گیری وزن را در فواصل 5 پوندی نمودار می کند، نه به این دلیل که چنین سنبله هایی در داده ها وجود دارد، بلکه به این دلیل که گردآورندگان داده های انسانی، بر خلاف ابزار، تمایل دارند اعداد خود را به نزدیکترین 0 گرد کنند. یا 5. 1
در سال 1985 ، جو فررمان ، برایان گاردینر و جاناتان شانکلین ، که برای بررسی قطب جنوب انگلیس (BAS) کار می کردند ، دریافتند که اندازه گیری آنها نشانگر سوراخ فصلی در لایه ازن بر روی نیمکره جنوبی است. این با داده های ناسا متناقض بود ، که چنین سوراخی را ثبت نکرد. فیزیکدان ناسا ، ریچارد استولرسکی ، تحقیق کرد و دریافت که نرم افزار پردازش داده ناسا با این فرض طراحی شده است که سطح ازن هرگز نمی تواند زیر یک مقدار مشخص قرار بگیرد ، و خوانش های بسیار کم ازن که به طور خودکار به عنوان خارج از کشور غیرقانونی ریخته می شوند. 2
ابزارها تنوع حالت های شکست را تجربه می کنند ، گاهی اوقات در حالی که هنوز هم داده ها را جمع می کنند. آدام رینگلر و همکاران. گالری از خوانش های لرزه نگاری ناشی از خرابی سازها (و خرابی های مربوطه) در مقاله 2021 "چرا Squiggles من خنده دار به نظر می رسد؟" 3 فعالیت در خواندن مثال با فعالیت لرزه ای واقعی مطابقت ندارد.
برای پزشکان ML ، درک بسیار مهم است:
- که داده ها را جمع آوری کرده است
- چگونه و چه زمانی داده ها جمع آوری شده و تحت چه شرایطی
- حساسیت و وضعیت ابزارهای اندازه گیری
- چه ناکامی های ساز و خطای انسانی ممکن است در یک زمینه خاص به نظر برسد
- گرایش های انسانی به تعداد دور و ارائه پاسخ های مطلوب
تقریباً همیشه ، حداقل تفاوت کمی بین داده ها و واقعیت وجود دارد ، که به عنوان حقیقت زمین نیز شناخته می شود. حسابداری برای این تفاوت برای گرفتن نتیجه گیری خوب و تصمیم گیری های صوتی مهم است. این شامل تصمیم گیری است:
- کدام مشکلات می تواند و باید توسط ML حل شود.
- کدام مشکلات توسط ML به بهترین وجه حل نمی شوند.
- کدام مشکلات هنوز داده های با کیفیت بالا را برای حل ML ندارند.
بپرسید: به نظر سخت ترین و تحت اللفظی ترین ، داده ها چه چیزی توسط داده ها ابلاغ می شود؟ به همان اندازه مهم ، چه چیزی توسط داده ها ابلاغ نمی شود؟
خاک در داده ها
علاوه بر بررسی شرایط جمع آوری داده ها ، خود مجموعه داده می تواند حاوی اشتباهات ، خطاها و مقادیر تهی یا نامعتبر باشد (مانند اندازه گیری های منفی غلظت). داده های منبع جمعیت می توانند به خصوص کثیف باشند. کار با مجموعه داده با کیفیت ناشناخته می تواند منجر به نتایج نادرست شود.
مسائل رایج عبارتند از:
- غلط های مقادیر رشته ، مانند مکان ، گونه ها یا نام های تجاری
- تبدیل نادرست واحد ، واحدها یا انواع شیء
- مقادیر گمشده
- طبقه بندی نادرست یا گمراه کننده
- ارقام قابل توجهی از عملیات ریاضی که از حساسیت واقعی یک ساز فراتر می رود
تمیز کردن یک مجموعه داده اغلب شامل انتخاب هایی در مورد مقادیر تهی و گمشده (خواه آنها را به عنوان تهی نگه دارید ، آنها را رها کنید ، یا 0 را جایگزین کنید) ، تصحیح هجی ها به یک نسخه واحد ، رفع واحدها و تبدیل ها و غیره. یک تکنیک پیشرفته تر برای تحمیل مقادیر گمشده است که در ویژگی های داده در دوره Crash Learning Machine شرح داده شده است.
نمونه گیری ، تعصب بقا و مشکل نقطه پایانی جانشین
آمار امکان برون یابی معتبر و دقیق نتایج حاصل از یک نمونه کاملاً تصادفی به جمعیت بزرگتر را فراهم می کند. شکنندگی ناشناخته از این فرض ، همراه با ورودی های آموزش نامتوازن و ناقص ، منجر به خرابی های مشخص در بسیاری از برنامه های ML ، از جمله مدل های مورد استفاده برای بررسی های رزومه و پلیس شده است. همچنین منجر به خرابی رای گیری و سایر نتیجه گیری های نادرست در مورد گروه های جمعیتی شده است. در بیشتر زمینه های خارج از داده های تولید شده توسط رایانه مصنوعی ، نمونه های کاملاً تصادفی بسیار گران قیمت و دستیابی به آن بسیار دشوار هستند. در عوض از راه حل های مختلف و پروکسی های مقرون به صرفه استفاده می شود که منابع مختلف تعصب را معرفی می کند.
به عنوان مثال ، برای استفاده از روش نمونه گیری طبقه بندی شده ، باید شیوع هر قشر نمونه برداری را در جمعیت بزرگتر بدانید. اگر شیوع خود را در واقع نادرست فرض کنید ، نتایج شما نادرست خواهد بود. به همین ترتیب ، نظرسنجی آنلاین به ندرت نمونه تصادفی از یک جمعیت ملی است ، اما نمونه ای از جمعیت متصل به اینترنت (اغلب از چندین کشور) که می بیند و مایل به انجام نظرسنجی است. این گروه احتمالاً با یک نمونه تصادفی واقعی متفاوت است. سؤالات موجود در نظرسنجی نمونه ای از سؤالات ممکن است. پاسخ به این سؤالات نظرسنجی ، باز هم نمونه تصادفی از نظرات واقعی پاسخ دهندگان نیست ، بلکه نمونه ای از نظرات است که پاسخ دهندگان راحت ارائه می دهند ، که ممکن است با نظرات واقعی آنها متفاوت باشد.
محققان بهداشت بالینی با مسئله مشابهی که به عنوان مشکل نقطه پایانی جانشین شناخته می شود ، روبرو می شوند. از آنجا که بررسی تأثیر دارو در طول عمر بیمار خیلی طولانی طول می کشد ، محققان از نشانگرهای زیستی پروکسی استفاده می کنند که فرض می شود مربوط به طول عمر است اما ممکن است نباشد. از سطح کلسترول به عنوان یک نقطه پایانی جانشین برای حملات قلبی و مرگ و میر ناشی از مشکلات قلبی عروقی استفاده می شود: اگر یک دارو سطح کلسترول را کاهش دهد ، فرض بر این است که خطر ابتلا به مشکلات قلبی نیز کمتر است. با این حال ، این زنجیره همبستگی ممکن است معتبر نباشد ، وگرنه ترتیب علیت ممکن است غیر از آنچه محقق فرض می کند باشد. برای مثال ها و جزئیات بیشتر ، به Weintraub و همکاران ، "خطرات نقاط پایانی جانشین" مراجعه کنید. وضعیت معادل ML از برچسب های پروکسی است.
ریاضیدان آبراهام والد مشهور مسئله نمونه برداری از داده ها را که اکنون به عنوان تعصب بازمانده شناخته می شود ، شناسایی کرد. هواپیماهای جنگی با سوراخ های گلوله در مکان های خاص و نه در دیگران باز می گشتند. ارتش آمریكا می خواست زره های بیشتری را به هواپیماها در مناطق با بیشترین سوراخ های گلوله اضافه كند ، اما گروه تحقیقاتی والد به جای آن توصیه كرد كه زره پوش به مناطقی بدون سوراخ گلوله اضافه شود. آنها به درستی استنباط كردند كه نمونه داده های آنها كاهش یافته است زیرا هواپیماهایی كه در آن مناطق شلیك شده اند به حدی آسیب دیده اند كه قادر به بازگشت به پایگاه نیستند.
اگر یک مدل از طریق زره پوش فقط در نمودارهای بازگشت هواپیماهای جنگ آموزش دیده باشد ، بدون بینش در مورد تعصب بقا موجود در داده ها ، این مدل توصیه می کند مناطق را با سوراخ های بیشتر گلوله تقویت کند.
تعصب خود انتخاب می تواند از افراد انسانی داوطلبانه برای شرکت در یک مطالعه بوجود آید. به عنوان مثال ، زندانیان با انگیزه برای ثبت نام در یک برنامه کاهش عود مجدد ، می توانند جمعیتی را که کمتر از جمعیت زندانی عمومی در آینده مرتکب جرایم آینده می شوند ، نشان دهند. این نتایج را کاهش می دهد. 4
یک مشکل نمونه برداری ظریف تر ، یادآوری تعصب است که شامل قابلیت انعطاف پذیری خاطرات افراد انسانی است. در سال 1993 ، ادوارد جیووانوچی از گروهی از زنان با سن ، که برخی از آنها به سرطان مبتلا شده بودند ، در مورد عادت های رژیم غذایی گذشته خود پرسید. همان خانمها قبل از تشخیص سرطان ، نظرسنجی در مورد عادات رژیم غذایی انجام داده بودند. آنچه Giovannucci کشف کرد این بود که زنان بدون تشخیص سرطان رژیم غذایی خود را به طور دقیق به یاد می آورند ، اما زنان مبتلا به سرطان پستان گزارش دادند که چربی های بیشتری نسبت به آنچه قبلاً گزارش داده بودند مصرف می کنند - ناخودآگاه توضیح ممکن (هرچند نادرست) برای سرطان خود ارائه می دهند. 5
بپرسید:
- نمونه گیری مجموعه داده در واقع چیست؟
- چند سطح نمونه گیری وجود دارد؟
- چه تعصب ممکن است در هر سطح نمونه گیری معرفی شود؟
- آیا از اندازه گیری پروکسی (اعم از نشانگر تجاری یا نظرسنجی آنلاین یا سوراخ گلوله) استفاده می شود که همبستگی یا علیت واقعی را نشان می دهد؟
- چه چیزی ممکن است از نمونه و روش نمونه برداری از بین برود؟
ماژول انصاف در دوره Crash Learning Machine روش هایی برای ارزیابی و کاهش منابع اضافی تعصب در مجموعه داده های جمعیتی را در بر می گیرد.
تعاریف و رتبه بندی
اصطلاحات را به روشنی و دقیق تعریف کنید ، یا در مورد تعاریف واضح و دقیق سؤال کنید. این امر برای درک اینکه چه ویژگی های داده مورد بررسی قرار می گیرد و دقیقاً پیش بینی یا ادعا می شود ، ضروری است. چارلز ویلن ، در آمار برهنه ، "سلامت تولید ایالات متحده" را به عنوان نمونه ای از اصطلاح مبهم ارائه می دهد. این که آیا تولید ایالات متحده "سالم" است یا خیر ، کاملاً به نحوه تعریف این اصطلاح بستگی دارد. مقاله گرگ IP در مارس 2011 در اقتصاددان این ابهام را نشان می دهد. اگر متریک "سلامتی" "تولید تولید" باشد ، در سال 2011 ، تولید ایالات متحده به طور فزاینده ای سالم بود. اگر متریک "سلامت" به عنوان "مشاغل تولیدی" تعریف شود ، با این حال ، تولید ایالات متحده در حال کاهش است. 6
رتبه بندی ها غالباً از موضوعات مشابه رنج می برند ، از جمله وزن های مبهم یا مزخرف که به مؤلفه های مختلف رتبه بندی ، ناسازگاری رتبه بندی کنندگان و گزینه های نامعتبر داده می شود. مالکوم گلادول ، با نوشتن در نیویورکر ، از یک رئیس دادگستری عالی میشیگان ، توماس برنان ، که زمانی نظرسنجی را به صد وکلا ارسال می کرد ، از آنها می خواست تا ده مدرسه حقوقی را با کیفیت ، برخی مشهور ، برخی نه. این وکلا در جایگاه پنجم دانشکده حقوق پن ایالت را در رتبه پنجم قرار دادند ، اگرچه در زمان بررسی ، پن پن ایالت دانشکده حقوق نداشت. 7 بسیاری از رتبه های مشهور شامل یک مؤلفه شهرت مشابه ذهنی است. بپرسید که چه مؤلفه هایی به یک رتبه بندی می روند و چرا به این مؤلفه ها وزن خاص خود را اختصاص داده اند.
تعداد کمی و اثرات بزرگ
اگر دو بار در حال چرخش سکه هستید ، جای گرفتن 100 ٪ سر یا 100 ٪ دم تعجب آور نیست. همچنین تعجب آور نیست که بعد از چهار بار یک سکه ، 25 ٪ سر را بدست آورید ، سپس 75 ٪ سر برای چهار تلنگر بعدی ، هرچند که این یک افزایش ظاهراً عظیم است (که می تواند به اشتباه به یک ساندویچ خورده شده بین مجموعه های تلنگر سکه نسبت داده شود. یا هر فاکتور جالب دیگری). اما با افزایش تعداد سکه ها ، به 1000 یا 2000 می گویند ، انحراف درصد زیادی از 50 ٪ مورد انتظار از بین می رود بعید به نظر می رسد.
تعداد اندازه گیری ها یا افراد آزمایشی در یک مطالعه اغلب به عنوان n گفته می شود. تغییرات متناسب بزرگ به دلیل احتمال بسیار بیشتر در مجموعه داده ها و نمونه هایی با N کم رخ می دهد.
هنگام انجام تجزیه و تحلیل یا مستند سازی مجموعه داده در کارت داده ، N را مشخص کنید ، بنابراین افراد دیگر می توانند تأثیر نویز و تصادفی را در نظر بگیرند.
از آنجا که کیفیت مدل با تعداد نمونه ها به مقیاس می پردازد ، مجموعه ای از مجموعه های کم N منجر به مدل های با کیفیت پایین می شود.
رگرسیون به میانگین
به طور مشابه ، هر اندازه گیری که از احتمال تأثیر داشته باشد ، تحت تأثیر قرار گرفتن به عنوان رگرسیون به میانگین است. این توصیف می کند که چگونه اندازه گیری پس از اندازه گیری شدید به طور متوسط ، به طور متوسط احتمالاً شدیدتر یا نزدیکتر به میانگین است ، به دلیل این که در وهله اول اندازه گیری شدید بعید است. این اثر برجسته تر است اگر یک گروه به ویژه متوسط یا بالاتر از حد متوسط برای مشاهده انتخاب شود ، خواه این گروه بلندترین افراد در یک جمعیت باشد ، بدترین ورزشکاران یک تیم یا افراد بیشترین خطر سکته مغزی. بچه های بلندتر از افراد بلندتر از والدین خود کوتاه تر هستند ، بدترین ورزشکاران احتمالاً بعد از یک فصل فوق العاده بد بهتر عمل می کنند و احتمالاً کسانی که در معرض خطر سکته مغزی هستند احتمالاً بعد از هرگونه مداخله یا درمان ، خطر کاهش یافته را نشان می دهند. نه به دلیل عوامل ایجاد کننده بلکه به دلیل خاصیت و احتمالات تصادفی.
یکی از کاهش اثرات رگرسیون به میانگین ، هنگام بررسی مداخلات یا درمان های یک گروه بالاتر یا متوسط متوسط ، تقسیم افراد به یک گروه مطالعه و یک گروه کنترل به منظور جداسازی اثرات ایجاد کننده است. در زمینه ML ، این پدیده نشان می دهد که توجه بیشتری به هر مدلی که مقادیر استثنایی یا دورتر را پیش بینی می کند ، مانند:
- هوای شدید یا درجه حرارت
- فروشگاه ها یا ورزشکاران بهترین عملکرد
- محبوب ترین فیلم ها در یک وب سایت
اگر پیش بینی های مداوم یک مدل از این مقادیر استثنایی در طول زمان با واقعیت مطابقت ندارد ، به عنوان مثال پیش بینی می کند که یک فروشگاه یا فیلم بسیار موفق همچنان موفق خواهد شد وقتی که در واقع نیست ، بپرسید:
- آیا رگرسیون به میانگین می تواند مسئله باشد؟
- آیا ویژگی هایی با بالاترین وزن در واقع پیش بینی کننده تر از ویژگی هایی با وزن های پایین تر است؟
- آیا جمع آوری داده هایی که دارای مقدار پایه برای آن ویژگی ها هستند ، اغلب صفر (در واقع یک گروه کنترل) پیش بینی های مدل را تغییر می دهد؟
مراجع
هاف ، دارل. نحوه دروغ گفتن با آمار. NY: WW Norton ، 1954.
جونز، بن. اجتناب از مشکلات داده. هابوکن ، نیویورک: ویلی ، 2020.
اوکانر ، کایلین و جیمز اوون وودال. سن اطلاعات نادرست. New Haven: Yale Up ، 2019.
رینگلر ، آدم ، دیوید میسون ، گابی لاسکه و مری تمپلتون. "چرا Squiggles من خنده دار به نظر می رسد؟ گالری سیگنال های لرزه ای به خطر افتاده." نامه های تحقیقاتی لرزه نگاری 92 شماره. 6 (ژوئیه 2021). doi: 10.1785/0220210094
Weintraub ، William S ، Thomas F. Lüscher و Stuart Pocock. "خطرات نقاط پایانی جانشین." ژورنال قلب اروپایی 36 شماره. 33 (سپتامبر 2015): 2212–2218. doi: 10.1093/ureheartj/ehv164
ویلن، چارلز. آمار برهنه: دفع ترس از داده ها. NY: WW Norton ، 2013
مرجع تصویر
"تعصب زنده ماندن." مارتین گراندژان ، مکگدون و کامرون مول 2021. CC BY-SA 4.0. منبع
جونز 25-29. ↩
O'Connor و Weatherall 22-3. ↩
رینگلینگ و همکاران. ↩
ویلن 120 .
Siddhartha Mukherjee ، "آیا تلفن های همراه باعث سرطان مغز می شوند؟" در نیویورک تایمز ، 13 آوریل 2011. به نقل از ویلیان 122 .
ویلن 39-40. ↩
مالکوم گلادول ، "ترتیب چیزها" ، در نیویورکر 14 فوریه 2011. به نقل از ویلن 56 .
"زباله در ، زباله."
- ضرب المثل برنامه نویسی اولیه
در زیر هر مدل ML ، هر محاسبه همبستگی و هر توصیه سیاست مبتنی بر داده یک یا چند مجموعه داده خام نهفته است. مهم نیست که محصولات نهایی چقدر زیبا یا قابل توجه یا متقاعد کننده باشند ، اگر داده های اساسی اشتباه ، جمع آوری شده یا با کیفیت پایین ، مدل حاصل ، پیش بینی ، تجسم یا نتیجه گیری نیز از کیفیت پایین برخوردار باشد. هرکسی که مدلها را در مجموعه داده ها تجسم ، تجزیه و تحلیل و آموزش می دهد ، باید در مورد منبع داده های خود سؤالات سختی بپرسد.
ابزارهای جمع آوری داده می توانند نقص داشته باشند یا به شدت کالیبره شوند. انسانهای جمع آوری داده ها می توانند خسته ، بدبخت ، متناقض یا آموزش دیده ضعیف باشند. مردم اشتباه می کنند و افراد مختلف نیز می توانند در مورد طبقه بندی سیگنال های مبهم مخالف باشند. در نتیجه ، کیفیت و اعتبار داده ها می تواند رنج ببرد و داده ها ممکن است در بازتاب واقعیت ناکام باشند. بن جونز ، نویسنده اجتناب از مشکلات داده ها ، این شکاف داده های واقعیت را می نامد و به خواننده یادآوری می کند: "این جرم نیست ، این جرم گزارش شده است . این تعداد حملات شهاب سنگ نیست ، این تعداد حملات شهاب سنگ ضبط شده است."
نمونه هایی از شکاف داده و واقعیت:
جونز نمودارهای سنبله را در اندازه گیری های زمانی در فواصل 5 دقیقه ای و اندازه گیری وزن در فواصل 5 پوند ، نه به این دلیل که چنین سنبله هایی در داده ها وجود دارد ، بلکه به این دلیل است که جمع آورندگان داده های انسانی ، برخلاف ابزارها ، تمایل به گردآوری شماره خود به نزدیکترین 0 دارند یا 5. 1
در سال 1985 ، جو فررمان ، برایان گاردینر و جاناتان شانکلین ، که برای بررسی قطب جنوب انگلیس (BAS) کار می کردند ، دریافتند که اندازه گیری آنها نشانگر سوراخ فصلی در لایه ازن بر روی نیمکره جنوبی است. این با داده های ناسا متناقض بود ، که چنین سوراخی را ثبت نکرد. فیزیکدان ناسا ، ریچارد استولرسکی ، تحقیق کرد و دریافت که نرم افزار پردازش داده ناسا با این فرض طراحی شده است که سطح ازن هرگز نمی تواند زیر یک مقدار مشخص قرار بگیرد ، و خوانش های بسیار کم ازن که به طور خودکار به عنوان خارج از کشور غیرقانونی ریخته می شوند. 2
ابزارها تنوع حالت های شکست را تجربه می کنند ، گاهی اوقات در حالی که هنوز هم داده ها را جمع می کنند. آدام رینگلر و همکاران. گالری از خوانش های لرزه نگاری ناشی از خرابی سازها (و خرابی های مربوطه) در مقاله 2021 "چرا Squiggles من خنده دار به نظر می رسد؟" 3 فعالیت در خواندن مثال با فعالیت لرزه ای واقعی مطابقت ندارد.
برای پزشکان ML ، درک بسیار مهم است:
- که داده ها را جمع آوری کرده است
- چگونه و چه زمانی داده ها جمع آوری شده و تحت چه شرایطی
- حساسیت و وضعیت ابزارهای اندازه گیری
- چه ناکامی های ساز و خطای انسانی ممکن است در یک زمینه خاص به نظر برسد
- گرایش های انسانی به تعداد دور و ارائه پاسخ های مطلوب
تقریباً همیشه ، حداقل تفاوت کمی بین داده ها و واقعیت وجود دارد ، که به عنوان حقیقت زمین نیز شناخته می شود. حسابداری برای این تفاوت برای گرفتن نتیجه گیری خوب و تصمیم گیری های صوتی مهم است. این شامل تصمیم گیری است:
- کدام مشکلات می تواند و باید توسط ML حل شود.
- کدام مشکلات توسط ML به بهترین وجه حل نمی شوند.
- کدام مشکلات هنوز داده های با کیفیت بالا را برای حل ML ندارند.
بپرسید: به نظر سخت ترین و تحت اللفظی ترین ، داده ها چه چیزی توسط داده ها ابلاغ می شود؟ به همان اندازه مهم ، چه چیزی توسط داده ها ابلاغ نمی شود؟
خاک در داده ها
علاوه بر بررسی شرایط جمع آوری داده ها ، خود مجموعه داده می تواند حاوی اشتباهات ، خطاها و مقادیر تهی یا نامعتبر باشد (مانند اندازه گیری های منفی غلظت). داده های منبع جمعیت می توانند به خصوص کثیف باشند. کار با مجموعه داده با کیفیت ناشناخته می تواند منجر به نتایج نادرست شود.
مسائل رایج عبارتند از:
- غلط های مقادیر رشته ، مانند مکان ، گونه ها یا نام های تجاری
- تبدیل نادرست واحد ، واحدها یا انواع شیء
- مقادیر گمشده
- طبقه بندی نادرست یا گمراه کننده
- ارقام قابل توجهی از عملیات ریاضی که از حساسیت واقعی یک ساز فراتر می رود
تمیز کردن یک مجموعه داده اغلب شامل انتخاب هایی در مورد مقادیر تهی و گمشده (خواه آنها را به عنوان تهی نگه دارید ، آنها را رها کنید ، یا 0 را جایگزین کنید) ، تصحیح هجی ها به یک نسخه واحد ، رفع واحدها و تبدیل ها و غیره. یک تکنیک پیشرفته تر برای تحمیل مقادیر گمشده است که در ویژگی های داده در دوره Crash Learning Machine شرح داده شده است.
نمونه گیری ، تعصب بقا و مشکل نقطه پایانی جانشین
آمار امکان برون یابی معتبر و دقیق نتایج حاصل از یک نمونه کاملاً تصادفی به جمعیت بزرگتر را فراهم می کند. شکنندگی ناشناخته از این فرض ، همراه با ورودی های آموزش نامتوازن و ناقص ، منجر به خرابی های مشخص در بسیاری از برنامه های ML ، از جمله مدل های مورد استفاده برای بررسی های رزومه و پلیس شده است. همچنین منجر به خرابی رای گیری و سایر نتیجه گیری های نادرست در مورد گروه های جمعیتی شده است. در بیشتر زمینه های خارج از داده های تولید شده توسط رایانه مصنوعی ، نمونه های کاملاً تصادفی بسیار گران قیمت و دستیابی به آن بسیار دشوار هستند. در عوض از راه حل های مختلف و پروکسی های مقرون به صرفه استفاده می شود که منابع مختلف تعصب را معرفی می کند.
به عنوان مثال ، برای استفاده از روش نمونه گیری طبقه بندی شده ، باید شیوع هر قشر نمونه برداری را در جمعیت بزرگتر بدانید. اگر شیوع خود را در واقع نادرست فرض کنید ، نتایج شما نادرست خواهد بود. به همین ترتیب ، نظرسنجی آنلاین به ندرت نمونه تصادفی از یک جمعیت ملی است ، اما نمونه ای از جمعیت متصل به اینترنت (اغلب از چندین کشور) که می بیند و مایل به انجام نظرسنجی است. این گروه احتمالاً با یک نمونه تصادفی واقعی متفاوت است. سؤالات موجود در نظرسنجی نمونه ای از سؤالات ممکن است. پاسخ به این سؤالات نظرسنجی ، باز هم نمونه تصادفی از نظرات واقعی پاسخ دهندگان نیست ، بلکه نمونه ای از نظرات است که پاسخ دهندگان راحت ارائه می دهند ، که ممکن است با نظرات واقعی آنها متفاوت باشد.
محققان بهداشت بالینی با مسئله مشابهی که به عنوان مشکل نقطه پایانی جانشین شناخته می شود ، روبرو می شوند. از آنجا که بررسی تأثیر دارو در طول عمر بیمار خیلی طولانی طول می کشد ، محققان از نشانگرهای زیستی پروکسی استفاده می کنند که فرض می شود مربوط به طول عمر است اما ممکن است نباشد. از سطح کلسترول به عنوان یک نقطه پایانی جانشین برای حملات قلبی و مرگ و میر ناشی از مشکلات قلبی عروقی استفاده می شود: اگر یک دارو سطح کلسترول را کاهش دهد ، فرض بر این است که خطر ابتلا به مشکلات قلبی نیز کمتر است. با این حال ، این زنجیره همبستگی ممکن است معتبر نباشد ، وگرنه ترتیب علیت ممکن است غیر از آنچه محقق فرض می کند باشد. برای مثال ها و جزئیات بیشتر ، به Weintraub و همکاران ، "خطرات نقاط پایانی جانشین" مراجعه کنید. وضعیت معادل ML از برچسب های پروکسی است.
ریاضیدان آبراهام والد مشهور مسئله نمونه برداری از داده ها را که اکنون به عنوان تعصب بازمانده شناخته می شود ، شناسایی کرد. هواپیماهای جنگی با سوراخ های گلوله در مکان های خاص و نه در دیگران باز می گشتند. ارتش آمریكا می خواست زره های بیشتری را به هواپیماها در مناطق با بیشترین سوراخ های گلوله اضافه كند ، اما گروه تحقیقاتی والد به جای آن توصیه كرد كه زره پوش به مناطقی بدون سوراخ گلوله اضافه شود. آنها به درستی استنباط كردند كه نمونه داده های آنها كاهش یافته است زیرا هواپیماهایی كه در آن مناطق شلیك شده اند به حدی آسیب دیده اند كه قادر به بازگشت به پایگاه نیستند.
اگر یک مدل از طریق زره پوش فقط در نمودارهای بازگشت هواپیماهای جنگ آموزش دیده باشد ، بدون بینش در مورد تعصب بقا موجود در داده ها ، این مدل توصیه می کند مناطق را با سوراخ های بیشتر گلوله تقویت کند.
تعصب خود انتخاب می تواند از افراد انسانی داوطلبانه برای شرکت در یک مطالعه بوجود آید. به عنوان مثال ، زندانیان با انگیزه برای ثبت نام در یک برنامه کاهش عود مجدد ، می توانند جمعیتی را که کمتر از جمعیت زندانی عمومی در آینده مرتکب جرایم آینده می شوند ، نشان دهند. این نتایج را کاهش می دهد. 4
یک مشکل نمونه برداری ظریف تر ، یادآوری تعصب است که شامل قابلیت انعطاف پذیری خاطرات افراد انسانی است. در سال 1993 ، ادوارد جیووانوچی از گروهی از زنان با سن ، که برخی از آنها به سرطان مبتلا شده بودند ، در مورد عادت های رژیم غذایی گذشته خود پرسید. همان خانمها قبل از تشخیص سرطان ، نظرسنجی در مورد عادات رژیم غذایی انجام داده بودند. آنچه Giovannucci کشف کرد این بود که زنان بدون تشخیص سرطان رژیم غذایی خود را به طور دقیق به یاد می آورند ، اما زنان مبتلا به سرطان پستان گزارش دادند که چربی های بیشتری نسبت به آنچه قبلاً گزارش داده بودند مصرف می کنند - ناخودآگاه توضیح ممکن (هرچند نادرست) برای سرطان خود ارائه می دهند. 5
بپرسید:
- نمونه گیری مجموعه داده در واقع چیست؟
- چند سطح نمونه گیری وجود دارد؟
- چه تعصب ممکن است در هر سطح نمونه گیری معرفی شود؟
- آیا از اندازه گیری پروکسی (اعم از نشانگر تجاری یا نظرسنجی آنلاین یا سوراخ گلوله) استفاده می شود که همبستگی یا علیت واقعی را نشان می دهد؟
- چه چیزی ممکن است از نمونه و روش نمونه برداری از بین برود؟
ماژول انصاف در دوره Crash Learning Machine روش هایی برای ارزیابی و کاهش منابع اضافی تعصب در مجموعه داده های جمعیتی را در بر می گیرد.
تعاریف و رتبه بندی
اصطلاحات را به روشنی و دقیق تعریف کنید ، یا در مورد تعاریف واضح و دقیق سؤال کنید. این امر برای درک اینکه چه ویژگی های داده مورد بررسی قرار می گیرد و دقیقاً پیش بینی یا ادعا می شود ، ضروری است. چارلز ویلن ، در آمار برهنه ، "سلامت تولید ایالات متحده" را به عنوان نمونه ای از اصطلاح مبهم ارائه می دهد. این که آیا تولید ایالات متحده "سالم" است یا خیر ، کاملاً به نحوه تعریف این اصطلاح بستگی دارد. مقاله گرگ IP در مارس 2011 در اقتصاددان این ابهام را نشان می دهد. اگر متریک "سلامتی" "تولید تولید" باشد ، در سال 2011 ، تولید ایالات متحده به طور فزاینده ای سالم بود. اگر متریک "سلامت" به عنوان "مشاغل تولیدی" تعریف شود ، با این حال ، تولید ایالات متحده در حال کاهش است. 6
رتبه بندی ها غالباً از موضوعات مشابه رنج می برند ، از جمله وزن های مبهم یا مزخرف که به مؤلفه های مختلف رتبه بندی ، ناسازگاری رتبه بندی کنندگان و گزینه های نامعتبر داده می شود. مالکوم گلادول ، با نوشتن در نیویورکر ، از یک رئیس دادگستری عالی میشیگان ، توماس برنان ، که زمانی نظرسنجی را به صد وکلا ارسال می کرد ، از آنها می خواست تا ده مدرسه حقوقی را با کیفیت ، برخی مشهور ، برخی نه. این وکلا در جایگاه پنجم دانشکده حقوق پن ایالت را در رتبه پنجم قرار دادند ، اگرچه در زمان بررسی ، پن پن ایالت دانشکده حقوق نداشت. 7 بسیاری از رتبه های مشهور شامل یک مؤلفه شهرت مشابه ذهنی است. بپرسید که چه مؤلفه هایی به یک رتبه بندی می روند و چرا به این مؤلفه ها وزن خاص خود را اختصاص داده اند.
تعداد کمی و اثرات بزرگ
اگر دو بار در حال چرخش سکه هستید ، جای گرفتن 100 ٪ سر یا 100 ٪ دم تعجب آور نیست. همچنین تعجب آور نیست که بعد از چهار بار یک سکه ، 25 ٪ سر را بدست آورید ، سپس 75 ٪ سر برای چهار تلنگر بعدی ، هرچند که این یک افزایش ظاهراً عظیم است (که می تواند به اشتباه به یک ساندویچ خورده شده بین مجموعه های تلنگر سکه نسبت داده شود. یا هر فاکتور جالب دیگری). اما با افزایش تعداد سکه ها ، به 1000 یا 2000 می گویند ، انحراف درصد زیادی از 50 ٪ مورد انتظار از بین می رود بعید به نظر می رسد.
تعداد اندازه گیری ها یا افراد آزمایشی در یک مطالعه اغلب به عنوان n گفته می شود. تغییرات متناسب بزرگ به دلیل احتمال بسیار بیشتر در مجموعه داده ها و نمونه هایی با N کم رخ می دهد.
هنگام انجام تجزیه و تحلیل یا مستند سازی مجموعه داده در کارت داده ، N را مشخص کنید ، بنابراین افراد دیگر می توانند تأثیر نویز و تصادفی را در نظر بگیرند.
از آنجا که کیفیت مدل با تعداد نمونه ها به مقیاس می پردازد ، مجموعه ای از مجموعه های کم N منجر به مدل های با کیفیت پایین می شود.
رگرسیون به میانگین
به طور مشابه ، هر اندازه گیری که از احتمال تأثیر داشته باشد ، تحت تأثیر قرار گرفتن به عنوان رگرسیون به میانگین است. این توصیف می کند که چگونه اندازه گیری پس از اندازه گیری شدید به طور متوسط ، به طور متوسط احتمالاً شدیدتر یا نزدیکتر به میانگین است ، به دلیل این که در وهله اول اندازه گیری شدید بعید است. این اثر برجسته تر است اگر یک گروه به ویژه متوسط یا بالاتر از حد متوسط برای مشاهده انتخاب شود ، خواه این گروه بلندترین افراد در یک جمعیت باشد ، بدترین ورزشکاران یک تیم یا افراد بیشترین خطر سکته مغزی. بچه های بلندتر از افراد بلندتر از والدین خود کوتاه تر هستند ، بدترین ورزشکاران احتمالاً بعد از یک فصل فوق العاده بد بهتر عمل می کنند و احتمالاً کسانی که در معرض خطر سکته مغزی هستند احتمالاً بعد از هرگونه مداخله یا درمان ، خطر کاهش یافته را نشان می دهند. نه به دلیل عوامل ایجاد کننده بلکه به دلیل خاصیت و احتمالات تصادفی.
یکی از کاهش اثرات رگرسیون به میانگین ، هنگام بررسی مداخلات یا درمان های یک گروه بالاتر یا متوسط متوسط ، تقسیم افراد به یک گروه مطالعه و یک گروه کنترل به منظور جداسازی اثرات ایجاد کننده است. در زمینه ML ، این پدیده نشان می دهد که توجه بیشتری به هر مدلی که مقادیر استثنایی یا دورتر را پیش بینی می کند ، مانند:
- هوای شدید یا درجه حرارت
- فروشگاه ها یا ورزشکاران بهترین عملکرد
- محبوب ترین فیلم ها در یک وب سایت
اگر پیش بینی های مداوم یک مدل از این مقادیر استثنایی در طول زمان با واقعیت مطابقت ندارد ، به عنوان مثال پیش بینی می کند که یک فروشگاه یا فیلم بسیار موفق همچنان موفق خواهد شد وقتی که در واقع نیست ، بپرسید:
- آیا رگرسیون به میانگین می تواند مسئله باشد؟
- آیا ویژگی هایی با بالاترین وزن در واقع پیش بینی کننده تر از ویژگی هایی با وزن های پایین تر است؟
- آیا جمع آوری داده هایی که دارای مقدار پایه برای آن ویژگی ها هستند ، اغلب صفر (در واقع یک گروه کنترل) پیش بینی های مدل را تغییر می دهد؟
مراجع
هاف ، دارل. نحوه دروغ گفتن با آمار. NY: WW Norton ، 1954.
جونز، بن. اجتناب از مشکلات داده. هابوکن ، نیویورک: ویلی ، 2020.
اوکانر ، کایلین و جیمز اوون وودال. سن اطلاعات نادرست. New Haven: Yale Up ، 2019.
رینگلر ، آدم ، دیوید میسون ، گابی لاسکه و مری تمپلتون. "چرا Squiggles من خنده دار به نظر می رسد؟ گالری سیگنال های لرزه ای به خطر افتاده." نامه های تحقیقاتی لرزه نگاری 92 شماره. 6 (ژوئیه 2021). doi: 10.1785/0220210094
Weintraub ، William S ، Thomas F. Lüscher و Stuart Pocock. "خطرات نقاط پایانی جانشین." ژورنال قلب اروپایی 36 شماره. 33 (سپتامبر 2015): 2212–2218. doi: 10.1093/ureheartj/ehv164
ویلن، چارلز. آمار برهنه: دفع ترس از داده ها. NY: WW Norton ، 2013
مرجع تصویر
"تعصب زنده ماندن." مارتین گراندژان ، مکگدون و کامرون مول 2021. CC BY-SA 4.0. منبع
جونز 25-29. ↩
O'Connor و Weatherall 22-3. ↩
رینگلینگ و همکاران. ↩
ویلن 120 .
Siddhartha Mukherjee ، "آیا تلفن های همراه باعث سرطان مغز می شوند؟" در نیویورک تایمز ، 13 آوریل 2011. به نقل از ویلیان 122 .
ویلن 39-40. ↩
مالکوم گلادول ، "ترتیب چیزها" ، در نیویورکر 14 فوریه 2011. به نقل از ویلن 56 .