"Garbage in, garbage out"
– פתאום בתכנות מוקדם
מתחת לכל מודל למידת מכונה, כל חישוב של מתאם וכל מודל מבוסס נתונים המלצה זו מתייחסת למערך נתונים גולמי אחד או יותר. לא משנה כמה המוצרים הסופיים יפים, מרשימים או משכנעים, אם הנתונים הבסיסיים היו שגויים, נאספו בצורה לא טובה או באיכות נמוכה, גם המודל, התחזית, התצוגה החזותית או המסקנה שייווצרו יהיו באיכות נמוכה. כל מי שממחיש באופן חזותי, מנתח וממן מודלים מערכי נתונים צריכים לשאול שאלות קשות על מקור הנתונים שלהם.
מכשירים לאיסוף נתונים עלולים לשבש או לכייל אותם בצורה לא טובה. בני אדם שאוספים נתונים יכולים להיות עייפים, זדוניים, לא עקביים או באיכות נמוכה לאחר האימון. אנשים עושים טעויות, ואנשים שונים יכולים גם לא להסכים באופן סביר על הסיווג של אותות לא ברורים. כתוצאה מכך, האיכות תוקף הנתונים עלול להיפגע, וייתכן שהנתונים לא ישקפו את המציאות. בן ג'ונס, המחבר של הימנעות מנתונים מלכודות data-reality פער, ומזכירות לקורא: "זה לא פשע, זה פשע מדווח. זו לא הסיבה מספר הפסילות של מטאורים, הוא מספר הפסילות המתעדות של מטאורים."
דוגמאות לפער במציאות הנתונים:
ג'ונס תרשימים עליות חדות במדידות זמן במרווחי זמן של 5 דקות, וגם למדידה של משקל במרווחים של 5 ק"ג, לא בגלל קפיצות כאלה אבל בגלל שאוספים של נתונים אנושיים, בניגוד לכלי נגינה, יש נטייה כדי לעגל את המספרים ל-0 או ל-5 הקרובים ביותר.1
ב-1985, ג'ו פרמן, בריאן גרדינר וג'ונתן שנקלין הסקר האנטארקטי הבריטי (BAS), גילה שהמדידות שלהם הראו חור עונתי בשכבת האוזון מעל חצי הכדור הדרומי. הזה שסותרות את הנתונים של נאס"א, שלא תועדו חור כזה. ריצ'רד, הפיזיקאי של נאס"א סטולרסקי חקר ומצא שתוכנת עיבוד הנתונים של נאס"א מתוך ההנחה שרמות האוזון אף פעם לא יכולות לרדת מתחת כמות מסוימת, והערכים הנמוכים מאוד של האוזון שזוהו הופצו באופן אוטומטי חריגות חסרות היגיון.2
למכשירים יש מגוון רחב של מצבי כשל, לפעמים בזמן שהם עדיין אוספים נתונים. אדם רינגלר ואחרים לספק גלריה של סייזמוגרף קריאות שנגרמות מכשלים בכלים (והכשלים התואמים) במאמר "למה השרבוטים שלי נראים מצחיקים?" בשנת 20213 הפעילות קריאות לדוגמה לא תואמות לפעילות סייסמית בפועל.
אנשי מקצוע שעוסקים בלמידת מכונה צריכים להבין:
- מי אסף את הנתונים
- איך ומתי הנתונים נאספו ובאילו תנאים
- הרגישות והמצב של מכשירי המדידה
- האופן שבו כשלים במכשירים ושגיאות אנוש עשויים להיראות באופן ספציפי הקשר
- נטיות אנושיות לבחירת מספרים עגולים ולמתן תשובות רצויות
כמעט תמיד יש לפחות הבדל קטן בין הנתונים למציאות, נקראת גם ground truth. ההתחשבות בהבדלים האלה היא המפתח להסקת מסקנות טובות לקבל החלטות מושכלות. כולל ההחלטה:
- אילו בעיות אפשר לפתור באמצעות למידת מכונה.
- אילו בעיות לא ניתן לפתור בצורה הטובה ביותר באמצעות למידת מכונה.
- אם אין עדיין מספיק נתונים באיכות גבוהה שאפשר לפתור באמצעות למידת מכונה.
שאלו: מה, במשמעות המחמירה והמילולית ביותר, מועברת באמצעות הנתונים? באותה מידה, מה לא מועבר באמצעות הנתונים?
לכלוך בנתונים
בנוסף לחקירת התנאים של איסוף הנתונים, מערך הנתונים עצמו עשוי להכיל blunders, שגיאות, ו-null או ערכי null (כמו מדידות שליליות של הריכוז). נתונים המבוססים על קהלים יכולים להיות מבולגן. עבודה עם מערך נתונים באיכות לא ידועה עלולה להוביל לתוצאות לא מדויקות.
בעיות נפוצות:
- שגיאות איות של ערכי מחרוזות, כמו שם של מקום, שם מין או שמות מותגים
- שגיאה בנתוני ההמרות של יחידות, יחידות או סוגי אובייקטים
- חסרים ערכים
- סיווגים שגויים או תוויות שגויות באופן עקבי
- ספרות משמעותיות שנותרו מפעולות מתמטיות שחורגות מ- הרגישות האמיתית של כלי נגינה
פעולת הניקוי של מערך נתונים כוללת לרוב בחירות לגבי ערכים חסרים וערכים null (אם לשמור אותם כ-null, להסיר אותם או להחליף אותם ב-0), תיקון שגיאות איות לגרסה אחת, תיקון יחידות והמרות וכו'. גרסה מתקדמת יותר היא לשייך ערכים חסרים, כפי שמתואר מאפייני הנתונים בקורס מקוצר על למידת מכונה.
דגימה, הטיית הישרדות ובעיה של נקודת קצה (endpoint)
הנתונים הסטטיסטיים מאפשרים לבצע הערכות תקפות ומדויקות של תוצאות מדגם אקראי לחלוטין לאוכלוסייה הגדולה יותר. את השריטות שלא נבדקת ההנחה הזאת, יחד עם קלט לא מאוזן ולא שלם, הובילה לכשלים משמעותיים של אפליקציות רבות של למידת מכונה, כולל מודלים שמשמשים להמשיך בבדיקות ובשוטרים. היא גם גרמה לכשל בסקרים מסקנות שגויות לגבי קבוצות דמוגרפיות. ברוב ההקשרים מחוץ ל- נתונים ממוחשבים מלאכותיים, דגימות אקראיות לחלוטין יקר וקשה להשיג אותו. פתרונות שונים במחירים נוחים ועושים שימוש בשרתי proxy, כדי להציג מקורות שונים הטיה.
כדי להשתמש בשיטת הדגימה לפי שכבות, לדוגמה, אתם צריכים לדעת את השכיחות של כל שכבה שנדגמה באוכלוסייה הרחבה יותר. אם נניח שכיחות שגויה, התוצאות לא יהיו מדויקות. בדומה לכך, קלפיות אונליין הן מדגם אקראי של אוכלוסייה לאומית. אלא מדגם של האוכלוסייה שמחוברת לאינטרנט (בדרך כלל ממספר מדינות) שרואה את הסקר ומוכן להשתתף בו. הקבוצה הזו ככל הנראה שונה ממדגם אקראי אמיתי. השאלות הם מדגם של שאלות אפשריות. התשובות לשאלות בסקר האלה הן: שוב, לא מדגם אקראי של משיבים של דעות אמיתיות, אבל דעות שהמשיבים מרגישים בנוח לספק, ושעשויות להיות שונות של הדעות בפועל.
חוקרים קליניים בתחום הבריאות נתקלים בבעיה דומה שנקראת המחלה הסוכנת בעיה בנקודת קצה (endpoint). כי לוקח יותר מדי זמן לבדוק את ההשפעה של תרופה על על תוחלת החיים של המטופלים, חוקרים משתמשים בסמנים ביולוגיים שנועדו לשמש קשור לתוחלת החיים אבל לא בהכרח. רמות כולסטרול משמשות כסורוגיט נקודת קצה (endpoint) של התקפי לב ומקרי מוות שנגרמו עקב בעיות לב, אם ניתנה לכך תרופה שמפחיתה את רמות הכולסטרול, ומניעים שהוא גם מפחית את הסיכון לבעיות לב. עם זאת, ייתכן ששרשרת המתאם לא חוקית, או שהסדר של הסיבה לכך עשויה להיות שונה ממה שהחוקרים מניחים. ראו Weintraub et al., "הסיכונים של נקודות קצה חלופיות", , אפשר לראות דוגמאות ופרטים נוספים. המצב המקביל בלמידת מכונה הוא תוויות לשרת proxy.
המתמטיקאי אברהם ולד (Abraham Wald) זיהה באופן מפורסם בעיה שידועה בדגימת נתונים כמו הטיית הישרדות. מטוסי קרב חזרו עם חורי קליעים במיקומים מסוימים ולא במיקומים אחרים. הצבא בארה"ב רצה להוסיף עוד שריון למטוסים באזורים שיש בהם הכי הרבה חורי קליעים, אבל קבוצת המחקר של אפי במקום זאת, מומלץ להוסיף את השריון לאזורים ללא חורי תבליטים. הם הסיקו בצדק שדגמת הנתונים שלהם הייתה מעוותת מפני שמטוסים נורו האזורים האלה נפגעו באופן כה חמור עד שלא יכלו לחזור לבסיס.
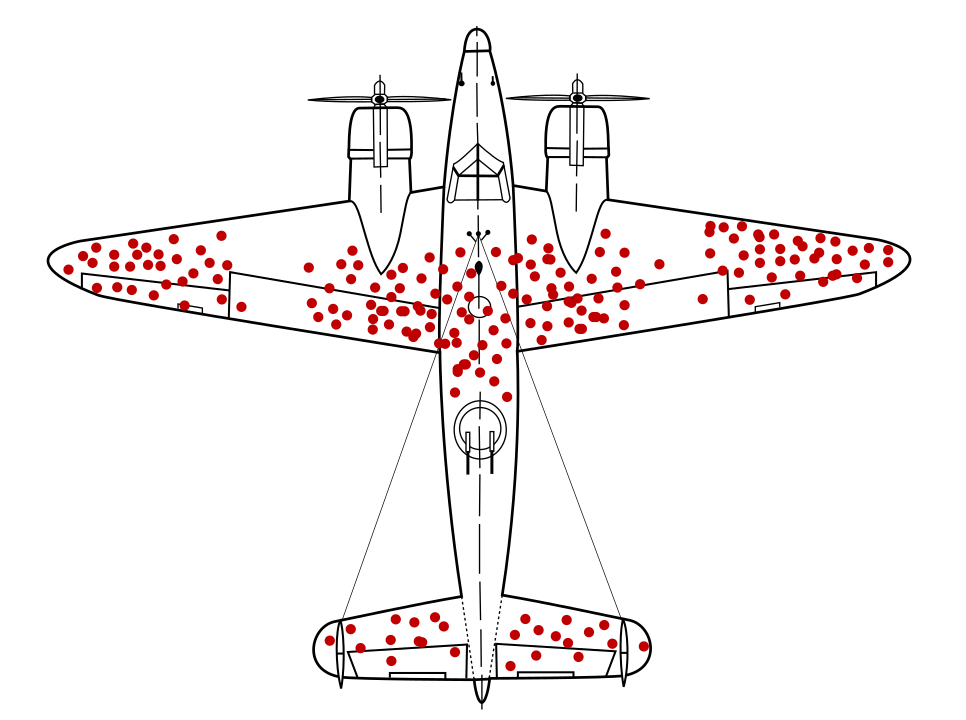
אם מודל להמלצה על שריון היה מתאמן רק על תרשימים של מטוסי קרב שחוזרים, בלי תובנה לגבי הטיה של ניצולים בנתונים, המודל היה ממליץ לחזק את האזורים עם יותר חורי כדור.
דעה קדומה בבחירה עצמית יכולה לנבוע מבודקים אנושיים שמתנדבים להשתתף במחקר. אסירים הציגו מוטיבציה להירשם לתוכנית צמצום רצדיביזם של התוכנית, לדוגמה, יכולה לייצג אוכלוסייה שפחות סביר פשעים עתידיים מאשר אוכלוסיית האצורים הכללית. זה יגרום להטות את התוצאות.4
בעיית דגימה עדינה יותר היא הטיית ריקול, שכוללת את יכולת הקלות של נבדקים זיכרונות. בשנת 1993, אדוארד ג'ובנוצ'י (Edward Giovannucci) שאל קבוצה של נשים באותו גיל, חלקן אובחנו כחולות בסרטן, על הרגלי התזונה הקודמים שלהן. אותן נשים השתתפו בסקר על הרגלי תזונה לפני לאבחן סרטן. ג'יובנוצ'י גילתה שנשים ללא סרטן אבחוןי התזונה שלהם שחזרו במדויק את התזונה שלהם, אבל נשים עם סרטן השד דיווחו צריכת יותר שומנים מכפי שדיווחו בעבר - באופן לא מודע מתן הסבר אפשרי (אם כי לא מדויק) לגבי הסרטן.5
שאל:
- מהי דגימת מערך נתונים בפועל?
- כמה רמות דגימה קיימות?
- איזו הטיה עשויה לחול בכל רמת דגימה?
- האם נעשה שימוש במדידה של שרת proxy (סמן ביולוגי, סקר או תבליט באינטרנט? חור) שמציג מתאם או סיבתיות ממשיים?
- מה עשוי להיות חסר בדגימה ובשיטת הדגימה?
מודול יושרה בקורס קריסה של למידת מכונה שעוסקים בדרכים חדשות להעריך ולצמצם את הסיכון מקורות נוספים להטיות במערכי נתונים דמוגרפיים.
הגדרות ודירוגים
צריך להגדיר מונחים באופן ברור ומדויק, או לשאול על הגדרות ברורות ומדויקות. צריך לעשות את זה כדי להבין אילו תכונות נתונים נמצאות בבדיקה ומה בדיוק החיזוי או הטענה. צ'רלס ווילן, במאמר נתונים סטטיסטיים עירומים, מציע "את בריאות ארה"ב ייצור" כדוגמה למונח שאינו חד משמעי. האם הייצור בארה"ב הוא "בריאה" או לא תלויים לגמרי באופן הגדרת המונח. הסרטונים של גרג איפס מאמר ממרץ 2011 ב-The Ecosumst ממחיש את אי-הבהירות הזאת. אם המדד 'בריאות' הוא "ייצור output, " אז ב-2011, הייצור בארה"ב היה בריא יותר ויותר. אם "בריאות" מוגדר כ"עבודות ייצור", עם זאת, הייצור בארה"ב היה בדחייה.6
לעיתים קרובות הדירוגים סובלים מבעיות דומות, כולל בעיות נסתרות או חסרות היגיון את המשקולות האפשריות למרכיבים שונים של הדירוג, חוסר עקביות, אפשרויות לא חוקיות. מלקולם גולדוול, שכותב ב-The New Yorker, מציין שופט בית המשפט העליון במישיגן, תומס ברנן, ששלח פעם סקר מאה עורכי דין שמבקשים מהם לדרג עשרה בתי ספר למשפטים לפי איכות, חלקם מפורסמים וחלק לא. עורכי הדין האלה דירגו את בית הספר למשפטים בפנסילבניה במקום חמישי למרות שבזמן הסקר, למדינת פן לא היה חוק בית ספר.7 דירוגים ידועים רבים כוללים מודל סובייקטיבי דומה רכיב של מוניטין. תשאלו אילו רכיבים נכללים בדירוג, ולמה שהוקצו להם המשקולות הספציפיים.
מספרים קטנים ואפקטים גדולים
לא מפתיע לקבל 100% ראשים או 100% זנבות כשמטילים מטבע פעמיים. גם לא מפתיע לקבל 25% ראשים אחרי הטלת מטבע ארבע פעמים, ו-75% יותר פניות בארבע ההפלפות הבאות, למרות שזה מראה עלייה עצומה (שייתכן שאפשר לייחס בטעות לכריך שנאכל? בין סט של מטילים של מטבעות, או כל גורם מלאכותי אחר). אבל ככל שהמספר של עלייה של 1,000 או 2,000 מטבעות, למשל 50% מהציפיות האלה הופכים לבלתי סבירים.
לעיתים קרובות מתייחסים למספר המדידות או הנבדקים במחקר ל-N. שינויים פרופורציונליים גדולים עקב אקראיים צפויים בהרבה מופיעים במערכי נתונים ובדגימות עם ערך N נמוך.
כשמבצעים ניתוח או תיעוד של מערך נתונים בכרטיס נתונים, N, כדי שאנשים אחרים יוכלו לקחת בחשבון את ההשפעה של הרעש והרנדומיזציה.
מכיוון שאיכות המודל נוטה להתאים לעומס בעזרת מספר דוגמאות, מערך נתונים עם N נמוך בדרך כלל מוביל ליצירת מודלים באיכות נמוכה.
רגרסיה לממוצע
באופן דומה, כל מדידה שיש לה השפעה מקרית כפופה אפקט שנקרא רגרסיה לממוצע. כאן מתואר איך המדידה אחרי מדידה קיצונית במיוחד בממוצע, עשויה להיות פחות קיצונית או קרובה יותר לממוצע, בשל לא סביר שהמדידה הקיצונית תתבצע מלכתחילה. השפעה משמעותית יותר בקרב קבוצות מעל הממוצע או מתחת לממוצע נבחר לתצפית, האם הקבוצה היא האנשים הגבוהים ביותר האוכלוסייה הזו, הספורטאים הכי גרועים בקבוצה מסוימת או כאלה שנמצאים בסיכון גבוה ביותר לשבץ. לרוב, הילדים של האנשים הגבוהים ביותר הם נמוכים ההורים, סביר להניח שהספורטאים הגרועים ביותר ישיגו ביצועים טובים יותר לאחר העונה הגרועה ביותר, והאנשים שנמצאים בסיכון גבוה לשבץ צפויים להיות בעלי סיכון נמוך יותר אחרי כל התערבות או טיפול כל, לא בגלל גורמים סיבתיים, בגלל התכונות והסתברויות של הרנדומיזציה.
צמצום אחד בהשפעות של רגרסיה לממוצע, כשבוחנים להתערבויות או טיפולים עבור קבוצה מעל הממוצע או מתחת לממוצע, מחלקים את הנבדקים לקבוצת מחקר ולקבוצת בקרה כדי לבודד השפעות סיבתיות. בהקשר של למידת מכונה, התופעה הזו מציעה לשלם סכום נוסף את תשומת הלב של כל מודל שחוזה ערכים יוצאי דופן או חריגים, למשל:
- מזג אוויר קיצוני או טמפרטורות קיצוניות
- החנויות או הספורטאים עם הביצועים הטובים ביותר
- הסרטונים הפופולריים ביותר באתר
אם החיזויים הקבועים של המודל ערכים יוצאי דופן לאורך זמן אינם תואמים למציאות, לדוגמה, חיזוי חנות או סרטון מוצלחים מאוד ימשיכו להצליח כשלמעשה הם היא לא, צריך לשאול:
- האם רגרסיה לממוצע יכול להיות הבעיה?
- האם הישויות עם המשקולות הגבוהות ביותר הן למעשה חזויות יותר מאשר פיצ'רים עם משקל נמוך יותר?
- האם איסוף נתונים שיש להם ערך בסיס עבור התכונות האלה, לעיתים קרובות אפס (למעשה קבוצת בקרה) משנה את החיזויים של המודל?
קובצי עזר
האף, דארל. איך להסתמך על נתונים סטטיסטיים. ניו יורק: W.W. נורטון, 1954.
ג'ונס, בן. הימנעות ממלכודות נתונים. הובוקן, ניו ג'רזי: Wiley, 2020.
או'קונור, קיילין וג'יימס אוון מזג האוויר. עידן המידע המוטעה. הייבן חדש: Yale UP, 2019.
רינגלר, אדם, דייוויד מייסון, גבי לאסקה ומרי טמפלטון. "למה השרבוטים שלי נראים מצחיקים? גלריה של אותות סייסמיים שנחשפו." מכתבי מחקר סיסמולוגי 92 מס'. 6 (יולי 2021). דוח DOI: 10.1785/0220210094
וויינטראוב, וויליאם ס., תומס פ. לושר וסטוארט פוקוק. "הסיכונים של נקודות קצה חלופיות (surrogate endpoints)" European Heart Journal 36 no. 33 (ספטמבר 2015): 2212–2218. DOI: 10.1093/eurheartj/ehv164
ווילן, צ'ארלס. נתונים סטטיסטיים עירומים: להסיר את הדאגה מהנתונים. ניו יורק: W.W. נורטון, 2013
הפניה לתמונה
'הטיות הישרדות'. מרטין גרנדז'אן, מקגדון וקמרון מול 2021. CC BY-SA 4.0. מקור
{kind=link}
-
ג'ונס 25-29.↩
-
או'קונור ומזג האוויר 22-3. ↩
-
Ringling et al. ↩
-
גלגלון 120.↩
-
סידהארטה מוחרג'י, "האם טלפונים סלולריים גורמים לסרטן המוח?" ב-The New York Times, 13 באפריל 2011. מצוטט בווילן 122. ↩
-
גלגלון 39-40.↩
-
מלקולם גולדוול, "The Order of Things", ב-The New Yorker 14 בפברואר 2011. מצוטט ב-Wilan 56.↩