„Śmieci do odpadów, śmieci”.
– Przysłowie na temat wczesnego programowania
W ramach każdego modelu ML, każdego obliczenia korelacji i każdego opartego na danych zalecenia dotyczące zasad obejmują co najmniej jeden nieprzetworzony zbiór danych. Bez względu na to, jak piękne przekonujące lub przekonujące, że produkty końcowe błędny, źle zebrane lub niskiej jakości, prognozy, wizualizacje lub wnioski również będą niskie. jakości. Każdy, kto wizualizuje, analizuje i trenuje modele na powinny zadawać trudne pytania o źródło swoich danych.
Przyrządy do zbierania danych mogą działać nieprawidłowo lub być źle skalibrowane. Ludzie zbierający dane mogą być zmęczony, psotny, niekonsekwentny lub słabo wytrenowanych. Ludzie popełniają błędy i różne osoby mogą się ze sobą nie zgadzać nad klasyfikacją niejednoznacznych sygnałów. W rezultacie jakość i ich prawidłowość i nieprawidłowość w odzwierciedlaniu rzeczywistości. Ben Jones, autor książki Unikanie danych Pitfalls. różnica między rzeczywistością danych a rzeczywistością danych, przypominający czytelnikowi: „To nie jest przestępstwo, to zgłoszone przestępstwo. To nie jest liczba uderzeń meteora, czyli liczba zarejestrowanych uderzeń meteorów”.
Przykłady luki w rzeczywistości danych:
Jones przedstawia gwałtowne skoki pomiarów czasu w 5-minutowych przedziałach. wagi w odstępach 15 kg, nie dlatego, że takie skoki występują ale ponieważ zbieracze danych człowieka, w przeciwieństwie do instrumentów, aby zaokrąglić ich liczby do najbliższej 0 lub 51.
W 1985 roku Joe Farman, Brian Gardiner i Jonathan Shanklin pracowali dla Brytyjska agencja Antarctic Survey (BAS) wykazała, że pomiary wskazują sezonowa dziura w warstwie ozonowej na półkuli południowej. Ten zaprzeczał danym NASA, który nie zarejestrował takiej dziury. Fizyk z NASA Richard Stolarski zbadał tę sprawę i odkrył, że oprogramowanie NASA do przetwarzania danych opracowany przy założeniu, że poziom ozonu nigdy nie spadnie poniżej oraz bardzo, bardzo niskie odczyty ozonu, które zostały wykryte były automatycznie odrzucane jako bezsensowne wyniki odstające2.
Instrumenty mogą się pochwalić różnorodnością sposobów działania, czasami nawet podczas zbierania danych. Adam Ringler i in. udostępnić galerię sejsmografów odczyty wynikające z awarii urządzeń (i odpowiadających im awarii) w publikacji z 2021 r. „Why Do My Squiggles Look Funny?”3 Zadania w przykładowe odczyty nie odpowiadają rzeczywistej aktywności sejsmicznej.
Osoby, które zajmują się systemami uczącymi się, muszą wiedzieć:
- Kto zebrał dane
- Jak i kiedy zebrano dane oraz w jakich warunkach
- Czułość i stan przyrządów pomiarowych
- Jak w konkretnym przypadku mogą wyglądać awarie instrumentów i błąd człowieka kontekst
- Ludzkie tendencje do zaokrąglania liczb i udzielania pożądanych odpowiedzi
Prawie zawsze jest przynajmniej niewielka różnica między danymi a rzeczywistością, nazywanych danymi podstawowymi. Ustalenie tej różnicy jest kluczem do wyciągnięcia dobrych wniosków rozsądnych decyzji. Podejmujemy te działania:
- które problemy mogą i powinny być rozwiązywane przez systemy uczące się.
- które problemy nie są najlepiej rozwiązywane przez systemy uczące się.
- które problemy nie mają jeszcze wystarczającej ilości danych wysokiej jakości, aby systemy uczące się mogły je rozwiązać.
Zadaj sobie pytanie: co w najbardziej ścisłym i dosłownym sensie są przekazywane dane? Równie ważne jest to, czego nie są zbierane dane.
Zabrudzenia danych
Oprócz badania warunków zbierania danych zbiór danych może zawierać błędy, błędy oraz wartości null lub nieprawidłowe (np. negatywnych pomiarów stężenia). Dane udostępniane przez użytkowników mogą być szczególnie chaotyczny. Praca ze zbiorem danych o nieznanej jakości może spowodować uzyskanie nieprawidłowych wyników.
Przykłady częstych problemów:
- błędy w pisowni wartości ciągów znaków, np. miejsce, gatunek czy nazwy marek;
- Nieprawidłowe konwersje jednostek, jednostki lub typy obiektów
- Brakujące wartości
- Powtarzające się błędne klasyfikacje lub błędne etykiety
- istotne cyfry pozostałe po operacjach matematycznych, które przekraczają rzeczywista czułość instrumentu
Czyszczenie zbioru danych często wiąże się z wyborem wartości null i brakujących (niezależnie od tego, pozostawienie ich jako null, usunięcie ich lub zastąpienie zera, poprawienie pisowni na jedną wersję, naprawianie jednostek, konwersji itd. Bardziej zaawansowana jest imponowanie brakujących wartości. Opisaliśmy to w sekcjach Cechy danych w ramach szybkiego szkolenia z systemów uczących się.
Próbkowanie, stronniczość przetrwania i problem z zastępczym punktem końcowym
Statystyki pozwalają na poprawną i dokładną ekstrapolację wyników ze tylko losową próbkę na większą populację. Niesprawdzona kruchość tego założenia, wraz z niezrównoważonymi i niekompletnymi danymi wejściowymi do trenowania, doprowadziła do poważnych niepowodzeń wielu zastosowań uczenia maszynowego, w tym modeli używanych do sprawdzania i kontrolowania życiorysów. Doprowadziło to również do błędów ankiet i innych błędne wnioski dotyczące grup demograficznych. W większości kontekstów poza sztuczne dane generowane komputerowo, czysto losowe próbki drogich i trudnych do pozyskania. Różne sposoby obejścia problemu i przystępne cenowo zamiast serwerów proxy, które udostępniają różne źródła uprzedzenia.
Aby np. użyć metody próbkowania warstwowego, musisz znać wartość parametru częstość występowania każdej warstwy w większej populacji. Jeśli chcesz, częstość występowania jest nieprawidłowa, Twoje wyniki będą niedokładne. Podobnie ankiety internetowe rzadko są losową próbą populacji kraju, ale próbkę populacji z dostępem do internetu (często pochodzących z różnych krajów), który przyjmuje udział w ankiecie i chce wziąć w niej udział. Ta grupa prawdopodobnie będzie się różnić od rzeczywistej próby losowej. Pytania w tabeli to przykładowe pytania. Odpowiedzi na te pytania: a nie losową próbkę respondentów, ale próbkę opinii, których udzielają respondenci bez obaw, które mogą różnić się od ich z faktycznego wyrażania opinii.
Kliniczne badacze zdrowia publicznego napotykają podobny problem znany jako zastępstwo . Ponieważ sprawdzenie działania leku na i długość życia pacjentów, badacze używają pośredniczących biomarkerów, które uznaje się za związane z okresem życia, ale może nie być. Poziom cholesterolu jest wykorzystywany jako jego substancja w przypadku zawałów serca i zgonów spowodowanych przez problemy sercowo-naczyniowe: jeśli lek jest stosowany obniża poziom cholesterolu, a także zmniejsza ryzyko problemów kardiologicznych. Taki łańcuch korelacji może jednak nie być prawidłowy, a w przeciwnym razie kolejność przyczynowo-przyczynowy może być inny niż zakładany badacz. Zobacz Weintraub i in., "Zagrożenia związane z zastępczymi punktami końcowymi", . Równoważna sytuacja w systemach uczących się jest taka, etykiety serwera proxy.
Matematyk Abraham Wald zasłynęło z problemem z próbkowaniem danych. jako uprzedzenia przetrwania. Samoloty wojenne wracały z dziurami po pociskach w konkretnych lokalizacjach, a nie w innych. Wojsko amerykańskie chciało dodać więcej zbroi do samolotów w miejscach z największą liczbą dziur, ale grupa badawcza Wally'ego zalecamy dodanie zbroi do obszarów bez otworów na pociski. Udało im się prawidłowo wywnioskować, że próbka ich danych jest zniekształcona, ponieważ samoloty wystrzeliwały te obszary zostały tak uszkodzone, że nie byli w stanie wrócić do bazy.
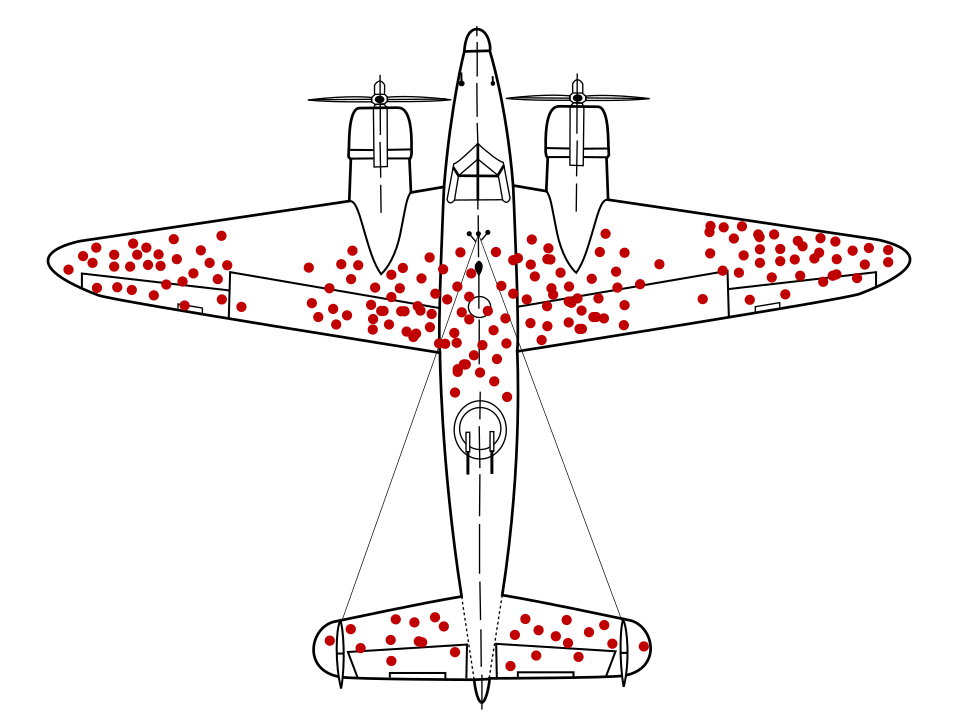
W przypadku modelu rekomendowania zbroi wytrenowano wyłącznie na podstawie diagramów powrotów samolotów wojennych, bez wglądu w uprzedzenia dotyczące przetrwania obecnej w danych, ten model zalecałby wzmocnienie obszarów z większą liczbą otworów na pociski.
Błąd doboru samodzielnego brać udział w badaniach. Więźniowie zmotywowani do rejestracji w celu zmniejszenia recydywy program może na przykład reprezentować populację mniej skłonną do podjęcia decyzji kolejnych przestępstw niż ogólna populacja więźniów. Może to zniekształcić wyniki4.
Bardziej subtelny problem z próbkowaniem dotyczy odchylenia czułości, dotyczącego plastyczności u ludzi wspomnień. W 1993 roku Edward Giovannucci zapytał o grupę wiekową kobiet, u niektórych z nich ze zdiagnozowanym rakiem, dotyczące swojej wcześniejszej diety nawyków. Te same kobiety brały udział w ankiecie na temat nawyków żywieniowych diagnozami nowotworów. Giovannucci odkryła, że kobiety bez raka podczas diagnozowania dokładnie odzwierciedlały swoją dietę, ale kobiety cierpiące na raka piersi zgłaszały spożywanie większej ilości tłuszczu niż kiedykolwiek wcześniej – nieświadomie podając możliwe (choć niedokładne) wyjaśnienie5.
Zadaj sobie pytanie:
- Czym jest w rzeczywistości próbkowanie zbioru danych?
- Ile poziomów próbkowania jest dostępnych?
- Jakie uprzedzenia mogą wystąpić na poszczególnych poziomach próbkowania?
- Czy używany jest pomiar pośredniczący (biomarker, ankieta online lub punktor) dziury) pokazujące rzeczywistą korelację czy związek przyczynowo-skutkowy?
- Czego może brakować w próbie i metodzie próbkowania?
Moduł obiektywności w ramach szybkiego szkolenia dotyczącego uczenia maszynowego, w którym omawiamy sposoby oceny i łagodzenia skutków. dodatkowych źródeł tendencyjności w demograficznych zbiorach danych.
Definicje i rankingi
Określaj terminy jasno i precyzyj lub pytaj o jasne i dokładne definicje. Jest to konieczne, aby zrozumieć, jakie cechy danych uwzględniamy i co jest prognozowane lub objęte roszczeniem. Charles Wheelan z kanału Naked Statistics oferuje „zdrowie Stanów Zjednoczonych” Produkcja przemysłowa jako przykład niejednoznacznego terminu. Czy w USA produkcja „zdrowe” lub nie zależy w pełni od sposobu definiowania tego terminu. Ip Grzegorza Artykuł z marca 2011 r. w The Economist ilustruje tę niejednoznaczność. Jeśli wskaźnik „zdrowie” to „produkcja dane wyjściowe”, W 2011 r. fabryka w Stanach Zjednoczonych rozwijała się coraz lepiej. Jeśli „zdrowie” jest zdefiniowany jako „zadania przemysłowe”, ale amerykańska fabryka była bliska spadku6.
Rankingi często są związane z podobnymi problemami, np. niejasnymi lub bezsensownymi wagi przypisanej różnym elementom rankingu, niespójność, nieprawidłowe opcje. Malcolm Gladwell, pisząc w dzienniku The New Yorker, wspomina o Thomas Brennan, prezes sądu najwyższego Michigan, który kiedyś wysłał ankietę na 100 prawników prosi ich o przyznanie 10 szkoły prawniczej pod względem jakości, niektóre są znane a inne nie. Prawnicy zaliczyli szkołę prawniczą Penn State na około piątej pozycji choć w czasach ankiety w Penn State nie istniało prawo, w szkole7.Wiele znanych rankingów zawiera podobnie subiektywny na reputację. Zapytaj, które komponenty są uwzględniane w rankingu i dlaczego. składnikom przypisano określoną wagę.
Mała liczba i duże efekty
Jeśli rzucasz monetą, możesz mieć zawsze 100% głów lub resztek. dwa razy. Nie zaskakuj też, że po 4-krotnym rzucaniu monetą otrzymujesz 25% głów, to 75% daje na kolejne 4 odwroty, chociaż to pokazuje, ogromny wzrost (co można przypisać błędnie zjedzonej kanapce). między rzutami monetą ani innymi oszukańczymi czynnikami). Jednakże liczba liczby rzutów monetą rośnie, np. do 1000 lub 2000, czyli dużych odchyleń procentowych przewidywane 50% staje się mało prawdopodobne.
W badaniu często odnosi się liczba pomiarów lub uczestników eksperymentu jako N. Znacznie większe prawdopodobieństwo, że znaczne zmiany proporcjonalne, wynikające z przypadku, występują w zbiorach danych i próbkach z niską wartością N.
Podczas przeprowadzania analizy lub dokumentowania zbioru danych na karcie danych podaj N, aby inne osoby mogły wziąć pod uwagę wpływ szumu i losowości.
Jakość modelu jest zwykle skalowana na podstawie liczby przykładów, więc zbiór danych niska N skutkuje zwykle niską jakością modeli.
Regresja do średniej
Podobnie każdy pomiar, który ma pewien wpływ przypadkowy, podlega efektem o nazwie regresji do średniej. Opisuje to, jak pomiar jest po szczególnie ekstremalnym pomiarze jest średnio mniej skrajne lub bliższe średniej, ze względu na to, jak mało prawdopodobne, że wcześniej doszło do ekstremalnych pomiarów. efekt jest wyraźniejszy, jeśli dana grupa jest szczególnie wyższa lub niższa od średniej wybranych do obserwacji, czy są to najwyższe osoby w najgorszych sportowców w drużynie czy najbardziej zagrożonych udarem. dzieci z najwyższych osób są średnio niższe od najgorszej osoby radzą sobie lepiej po zły sezon, a osoby najbardziej narażone na udar mózgu wykazują mniejsze ryzyko po dowolnej interwencji lub leczeniu, nie z powodu czynników przyczynowych, ale z powodu właściwości i prawdopodobieństw losowości.
Jedno ze sposobów złagodzenia skutków regresji do średniej podczas badania interwencji lub terapii w grupie powyżej średniej lub poniżej średniej, podziel uczestników na grupę badawczą i grupę kontrolną w celu wyodrębnienia efektami przyczynowymi. W kontekście systemów uczących się to zjawisko sugeruje, że warto zapłacić więcej, model, który prognozuje wartości odstające lub odstające, takie jak:
- ekstremalne zjawiska pogodowe lub temperatury,
- w przypadku najlepszych sklepów lub sportowców
- najpopularniejsze filmy w witrynie
Jeśli ciągłe prognozy modelu dotyczące tych wyjątkowe wartości na przestrzeni czasu nie zgadzają się z rzeczywistością, np. przy przewidywaniu, że udany sklep lub film będą nadal odnosić sukcesy, jeśli w rzeczywistości nie, zapytaj:
- Czy przyczyną problemu może być regresja do wartości średniej?
- Czy cechy o największej wadze są rzeczywiście bardziej przewidywalne? niż cechy o niższej wadze?
- Czy zbieranie danych, które mają dla tych cech wartość bazową, często zero (czyli grupie kontrolnej) zmienić prognozy modelu?
Pliki referencyjne
Uff, Darrell. Jak leżeć na statystykach. Nowy Jork: Norton, 1954 r.
Jones, Ben. Unikanie błędów związanych z danymi. Hoboken, NJ: Wiley, 2020 r.
O'Connor, Cailin i James Owen Weatherall. Wiek dezinformacji. Nowe schronienie: Yale UP, 2019 r.
Ringler, Adam, David Mason, Gabi Laske i Mary Templeton. „Dlaczego moje rysy wyglądają śmiesznie? a Galerii przejętych sygnałów sejsmicznych”. Seismological Research Letters 92, nr 6 (lipiec 2021 r.). DOI: 10.1785/0220210094
Weintraub, William S., Thomas F. Lüschera i Stuarta Pococka. „Zagrożenia związane z zastępczymi punktami końcowymi”. European Heart Journal 36 nr 33 (wrzesień 2015 r.): 2212–2218. DOI: 10.1093/eurheartj/ehv164
Wheelan, Charles. Nagłe statystyki: jak wyeliminować strach z danych. Nowy Jork: W.W. Norton, 2013
Odniesienie do obrazu
„Uprzedzenia przetrwania”. Martin Grandjean, McGeddon i Cameron Moll, 2021 r. CC BY-SA 4.0 Źródło
{kind=link}
-
Jones 25–29. ↩
-
O'Connor i Weatherall 22–3 lat. ↩
-
Ringling i in. ↩
-
Wheelan 120. ↩
-
Siddhartha Mukherjee „Czy telefony komórkowe powodują raka mózgu?” w The New York Times, 13 kwietnia 2011 r. Cytowane w Wheelan 122.↩
-
Wheelan 39-40. ↩
-
Malcolm Gladwell "Porządek rzeczy", (The New Yorker) 14 lutego 2011 r. Cytowany w Wheelan 56.↩