«Мусор на входе, мусор на выходе».
— Пословица раннего программирования
За каждой моделью машинного обучения, каждым расчетом корреляции и каждой рекомендацией политики на основе данных лежит один или несколько наборов необработанных данных. Независимо от того, насколько красивы, ярки или убедительны конечные продукты, если лежащие в основе данные были ошибочными, плохо собранными или низкого качества, результирующая модель, прогноз, визуализация или вывод также будут низкого качества. Любой, кто визуализирует, анализирует и обучает модели на основе наборов данных, должен задавать сложные вопросы об источнике своих данных.
Приборы для сбора данных могут работать со сбоями или быть плохо откалиброваны. Люди, собирающие данные, могут быть уставшими, вредными, непоследовательными или плохо обученными. Люди совершают ошибки, а также разные люди могут обоснованно расходиться во взглядах на классификацию неоднозначных сигналов. В результате может пострадать качество и достоверность данных, и они могут не отражать реальность. Бен Джонс, автор книги «Как избежать ловушек данных », называет это разрывом между данными и реальностью , напоминая читателю: «Это не преступление, это зарегистрированная преступность. Дело не в количестве метеоритных ударов, а в количестве зарегистрированных метеоритных ударов».
Примеры разрыва между данными и реальностью:
Джонс отображает пики измерений времени с 5-минутными интервалами и измерения веса с интервалами 5 фунтов не потому, что такие пики существуют в данных, а потому, что люди, собирающие данные, в отличие от приборов, имеют тенденцию округлять свои числа до ближайшего 0. или 5. 1
В 1985 году Джо Фарман, Брайан Гардинер и Джонатан Шанклин, работавшие в Британской антарктической службе (BAS), обнаружили, что их измерения указывают на сезонную дыру в озоновом слое над южным полушарием. Это противоречило данным НАСА, в которых такой дыры не зафиксировано. Физик НАСА Ричард Столарски исследовал и обнаружил, что программное обеспечение НАСА для обработки данных было разработано с учетом предположения, что уровни озона никогда не могут упасть ниже определенного уровня, а обнаруженные очень, очень низкие значения озона автоматически отбрасывались как бессмысленные выбросы. 2
Приборы испытывают различные режимы отказа, иногда даже во время сбора данных. Адам Ринглер и др. предоставить галерею показаний сейсмографа, возникших в результате сбоев приборов (и соответствующих сбоев) в статье 2021 года «Почему мои закорючки выглядят забавно?» 3 Активность в примерах показаний не соответствует фактической сейсмической активности.
Для специалистов по ОД важно понимать:
- Кто собирал данные
- Как и когда были собраны данные и при каких условиях
- Чувствительность и состояние средств измерений
- Как могут выглядеть отказы приборов и человеческие ошибки в конкретном контексте
- Человеческие склонности округлять числа и давать желаемые ответы
Почти всегда существует хотя бы небольшая разница между данными и реальностью, также известная как основная истина . Учет этой разницы является ключом к получению правильных выводов и принятию правильных решений. Это включает в себя решение:
- какие проблемы можно и нужно решить с помощью ML.
- какие проблемы не лучше всего решаются с помощью ML.
- какие проблемы еще не имеют достаточно качественных данных для решения с помощью ML.
Спросите: что в самом строгом и буквальном смысле передают данные? Не менее важно и то, о чем не сообщают данные?
Грязь в данных
Помимо изучения условий сбора данных, сам набор данных может содержать грубые ошибки, ошибки, а также нулевые или недопустимые значения (например, отрицательные измерения концентрации). Краудсорсинговые данные могут быть особенно запутанными. Работа с набором данных неизвестного качества может привести к неточным результатам.
Общие проблемы включают в себя:
- Ошибки в написании строковых значений, таких как место, вид или название бренда.
- Неправильные преобразования единиц измерения, единицы измерения или типы объектов.
- Отсутствующие значения
- Постоянные неправильные классификации или неправильная маркировка
- Значимые цифры, оставшиеся от математических операций, превышающие фактическую чувствительность прибора.
Очистка набора данных часто включает в себя выбор нулевых и отсутствующих значений (сохранить ли их как нулевые, удалить их или заменить нулями), исправление написания до единой версии, исправление единиц измерения и преобразований и т. д. Более продвинутый метод — вменение пропущенных значений, который описан в разделе «Характеристики данных» ускоренного курса машинного обучения.
Выборка, систематическая ошибка выживаемости и проблема суррогатной конечной точки
Статистика позволяет достоверно и точно экстраполировать результаты чисто случайной выборки на большую популяцию. Непроверенная хрупкость этого предположения, а также несбалансированные и неполные данные обучения привели к громким сбоям во многих приложениях ML, включая модели, используемые для проверки резюме и контроля. Это также привело к провалам опросов и другим ошибочным выводам о демографических группах. В большинстве случаев, за исключением искусственных компьютерных данных, чисто случайные выборки слишком дороги и их слишком трудно получить. Вместо этого используются различные обходные пути и доступные прокси, которые создают различные источники предвзятости .
Например, чтобы использовать метод стратифицированной выборки, вам необходимо знать распространенность каждой выбранной страты в более крупной популяции. Если вы предполагаете, что распространенность на самом деле неверна, ваши результаты будут неточными. Аналогичным образом, онлайн-опрос редко представляет собой случайную выборку населения страны, а представляет собой выборку подключенного к Интернету населения (часто из нескольких стран), которое видит опрос и желает принять участие в нем. Эта группа, вероятно, будет отличаться от настоящей случайной выборки. Вопросы в опросе представляют собой образец возможных вопросов. Ответы на эти вопросы опроса, опять же, представляют собой не случайную выборку реальных мнений респондентов, а выборку мнений, которые респонденты готовы высказать, и которые могут отличаться от их фактических мнений.
Клинические исследователи в области здравоохранения сталкиваются с аналогичной проблемой, известной как проблема суррогатной конечной точки . Поскольку проверка влияния препарата на продолжительность жизни пациентов занимает слишком много времени, исследователи используют прокси-биомаркеры, которые, как предполагается, связаны с продолжительностью жизни, но на самом деле это не так. Уровни холестерина используются в качестве суррогатного критерия оценки сердечных приступов и смертей, вызванных сердечно-сосудистыми заболеваниями: если лекарство снижает уровень холестерина, предполагается, что оно также снижает риск сердечно-сосудистых заболеваний. Однако эта цепочка корреляций может быть неверной, или же порядок причинно-следственной связи может отличаться от того, который предполагает исследователь. Дополнительные примеры и подробности см. Вайнтрауб и др., «Опасности суррогатных конечных точек» . Эквивалентная ситуация в ML – это ситуация с прокси-метками .
Математик Абрахам Уолд, как известно, выявил проблему выборки данных, теперь известную как ошибка выжившего . Военные самолеты возвращались с пулевыми отверстиями в одних местах, а не в других. Американские военные хотели добавить больше брони к самолетам в местах с наибольшим количеством пулевых отверстий, но исследовательская группа Уолда рекомендовала вместо этого добавлять броню в области без пулевых отверстий. Они правильно сделали вывод, что их выборка данных была искажена, поскольку самолеты, обстрелянные в этих районах, были настолько сильно повреждены, что не смогли вернуться на базу.
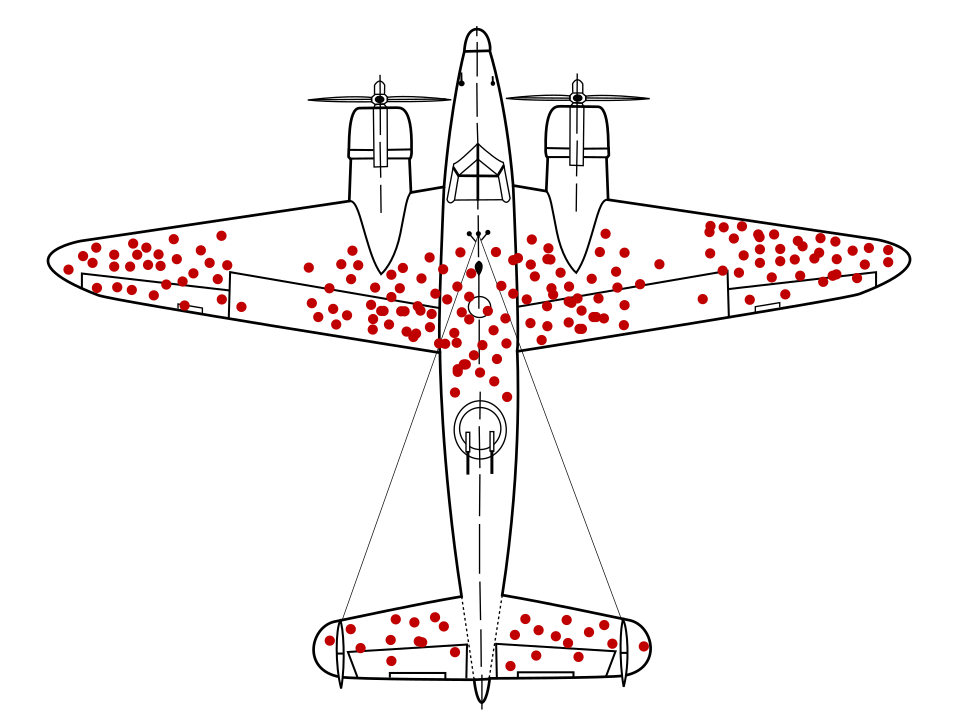
Если бы модель, рекомендовавшая броню, была обучена исключительно на диаграммах возвращающихся боевых самолетов, без учета систематической ошибки выживаемости, присутствующей в данных, эта модель рекомендовала бы укрепить области большим количеством пулевых отверстий.
Предвзятость самоотбора может возникнуть в результате добровольного участия людей в исследовании. Например, заключённые, мотивированные подписаться на программу по снижению рецидивизма, могут представлять собой группу населения, менее склонную к совершению преступлений в будущем, чем основная масса заключённых. Это исказило бы результаты. 4
Более тонкая проблема выборки — это смещение воспоминаний , связанное с податливостью воспоминаний людей. В 1993 году Эдвард Джовануччи спросил группу женщин одинакового возраста, у некоторых из которых был диагностирован рак, об их прошлых пищевых привычках. Те же женщины прошли опрос о пищевых привычках до того, как им поставили диагноз рака. Джованнуччи обнаружил, что женщины без диагноза рака точно помнят свою диету, но женщины с раком молочной железы сообщили, что потребляют больше жиров, чем сообщали ранее, неосознанно давая возможное (хотя и неточное) объяснение их рака. 5
Просить:
- Что на самом деле представляет собой выборка набора данных?
- Сколько уровней выборки имеется?
- Какая систематическая ошибка может возникнуть на каждом уровне выборки?
- Показывают ли используемые косвенные измерения (будь то биомаркер, онлайн-опрос или пулевое отверстие) реальную корреляцию или причинно-следственную связь?
- Чего может не хватать в выборке и методе отбора проб?
Модуль «Справедливость» ускоренного курса машинного обучения охватывает способы оценки и смягчения дополнительных источников систематической ошибки в наборах демографических данных.
Определения и рейтинги
Дайте четкое и точное определение терминам или спросите о ясных и точных определениях. Это необходимо, чтобы понять, какие особенности данных рассматриваются и что именно прогнозируется или утверждается. Чарльз Уилан в книге «Голая статистика » предлагает «здоровье производства в США» в качестве примера неоднозначного термина. Является ли производство в США «здоровым» или нет, полностью зависит от того, как определяется этот термин. Статья Грега Ипа в журнале The Economist, опубликованная в марте 2011 года, иллюстрирует эту двусмысленность. Если показателем «здоровья» является «производство обрабатывающей промышленности», то в 2011 году производство в США было все более здоровым. Однако, если показатель «здоровья» определять как «рабочие места в производстве», то производство в США находилось в упадке. 6
Рейтинги часто страдают от аналогичных проблем, включая неясные или бессмысленные веса, присвоенные различным компонентам рейтинга, непоследовательность рейтингов и недействительные варианты. Малкольм Гладуэлл в статье для The New Yorker упоминает председателя Верховного суда Мичигана Томаса Бреннана, который однажды разослал опрос сотне юристов с просьбой оценить десять юридических школ по качеству: некоторые известные, некоторые нет. Эти юристы поставили юридическую школу Пенсильванского университета примерно на пятое место, хотя на момент опроса в Пенсильванском университете не было юридической школы. 7 Многие известные рейтинги включают в себя столь же субъективный репутационный компонент. Спросите, какие компоненты входят в рейтинг и почему этим компонентам присвоен определенный вес.
Маленькие количества и большие эффекты
Неудивительно, что если вы подбрасываете монету дважды, то выпадет 100% орел или 100% решка. Неудивительно и то, что после подбрасывания монеты четыре раза выпадает 25% орлов, а при следующих четырех подбрасываниях — 75% орлов, хотя это демонстрирует очевидно огромный прирост (который можно ошибочно приписать сэндвичу, съеденному между подходами подбрасываний монеты). или любой другой ложный фактор). Но по мере увеличения количества подбрасываний монеты, скажем, до 1000 или 2000, большие процентные отклонения от ожидаемых 50% становятся исчезающе маловероятными.
Количество измерений или экспериментальных субъектов в исследовании часто обозначается как N. Большие пропорциональные изменения, вызванные случайностью, гораздо чаще происходят в наборах данных и выборках с низким N.
При проведении анализа или документировании набора данных в карте данных укажите N , чтобы другие люди могли учитывать влияние шума и случайности.
Поскольку качество модели имеет тенденцию увеличиваться с увеличением количества примеров, набор данных с низким N обычно приводит к моделям низкого качества.
Регрессия к среднему значению
Точно так же любое измерение, на которое в некоторой степени влияет случайность, подвержено эффекту, известному как регрессия к среднему значению . Это описывает, как измерение после особенно экстремального измерения в среднем может быть менее экстремальным или ближе к среднему значению из-за того, насколько маловероятно, чтобы экстремальное измерение произошло вообще. Эффект более выражен, если для наблюдения была выбрана группа с уровнем выше или ниже среднего, независимо от того, являются ли эта группа самыми высокими людьми в популяции, худшими спортсменами в команде или теми, кто наиболее подвержен риску инсульта. Дети самых высоких людей в среднем, вероятно, будут ниже своих родителей, худшие спортсмены, вероятно, будут показывать лучшие результаты после исключительно неудачного сезона, а те, кто наиболее подвержен риску инсульта, вероятно, продемонстрируют снижение риска после любого вмешательства или лечения. не из-за причинных факторов, а из-за свойств и вероятностей случайности.
Одним из способов смягчения последствий регрессии к среднему значению при изучении вмешательств или лечения для группы с уровнем выше среднего или ниже среднего является разделение субъектов на исследуемую группу и контрольную группу, чтобы изолировать причинные эффекты. В контексте МО это явление предполагает уделять особое внимание любой модели, которая предсказывает исключительные или выпадающие значения, например:
- экстремальная погода или температура
- самые эффективные магазины или спортсмены
- самые популярные видео на сайте
Если текущие прогнозы модели об этих исключительных значениях с течением времени не соответствуют действительности (например, предсказание того, что очень успешный магазин или видео будет продолжать пользоваться успехом, хотя на самом деле это не так), спросите:
- Может ли проблема заключаться в регрессии к среднему значению?
- Действительно ли признаки с наибольшим весом более предсказуемы, чем признаки с меньшим весом?
- Изменяет ли сбор данных, которые имеют базовое значение для этих функций, часто нулевое (по сути, контрольную группу), прогнозы модели?
Ссылки
Хафф, Даррелл. Как лгать со статистикой. Нью-Йорк: WW Нортон, 1954.
Джонс, Бен. Как избежать ошибок в данных. Хобокен, Нью-Джерси: Уайли, 2020.
О'Коннор, Кейлин и Джеймс Оуэн Уэзеролл. Эпоха дезинформации. Нью-Хейвен: Йельский университет, 2019.
Ринглер, Адам, Дэвид Мейсон, Габи Ласке и Мэри Темплтон. «Почему мои закорючки выглядят смешно? Галерея скомпрометированных сейсмических сигналов». Письма о сейсмологических исследованиях 92 вып. 6 (июль 2021 г.). DOI: 10.1785/0220210094
Вайнтрауб, Уильям С., Томас Ф. Люшер и Стюарт Покок. «Опасности суррогатных конечных точек». Европейский кардиологический журнал 36 вып. 33 (сентябрь 2015 г.): 2212–2218. DOI: 10.1093/eurheartj/ehv164.
Уилан, Чарльз. Голая статистика: избавление от страха от данных. Нью-Йорк: WW Нортон, 2013 г.
Ссылка на изображение
«Предвзятость выжившего». Мартин Гранжан, МакГеддон и Кэмерон Молл, 2021 г. CC BY-SA 4.0. Источник
{kind=link}
Джонс 25-29. ↩
О'Коннор и Уэзералл 22-3. ↩
Ринглинг и др. ↩
Уилан 120. ↩
Сиддхартха Мукерджи, «Вызывают ли мобильные телефоны рак мозга?» в The New York Times, 13 апреля 2011 г. Цитируется по Wheelan 122. ↩
Уилан 39-40. ↩
Малкольм Гладуэлл, «Порядок вещей» , в The New Yorker , 14 февраля 2011 г. Цитируется в Wheelan 56. ↩
«Мусор на входе, мусор на выходе».
— Пословица раннего программирования
За каждой моделью машинного обучения, каждым расчетом корреляции и каждой рекомендацией политики на основе данных лежит один или несколько наборов необработанных данных. Независимо от того, насколько красивы, ярки или убедительны конечные продукты, если лежащие в основе данные были ошибочными, плохо собранными или низкого качества, результирующая модель, прогноз, визуализация или вывод также будут низкого качества. Любой, кто визуализирует, анализирует и обучает модели на основе наборов данных, должен задавать сложные вопросы об источнике своих данных.
Приборы для сбора данных могут работать со сбоями или быть плохо откалиброваны. Люди, собирающие данные, могут быть уставшими, вредными, непоследовательными или плохо обученными. Люди совершают ошибки, а также разные люди могут обоснованно расходиться во взглядах на классификацию неоднозначных сигналов. В результате может пострадать качество и достоверность данных, и они могут не отражать реальность. Бен Джонс, автор книги «Как избежать ловушек данных », называет это разрывом между данными и реальностью , напоминая читателю: «Это не преступление, это зарегистрированная преступность. Дело не в количестве метеоритных ударов, а в количестве зарегистрированных метеоритных ударов».
Примеры разрыва между данными и реальностью:
Джонс отображает пики измерений времени с 5-минутными интервалами и измерения веса с интервалами 5 фунтов не потому, что такие пики существуют в данных, а потому, что люди, собирающие данные, в отличие от приборов, имеют тенденцию округлять свои числа до ближайшего 0. или 5. 1
В 1985 году Джо Фарман, Брайан Гардинер и Джонатан Шанклин, работавшие в Британской антарктической службе (BAS), обнаружили, что их измерения указывают на сезонную дыру в озоновом слое над южным полушарием. Это противоречило данным НАСА, в которых такой дыры не зафиксировано. Физик НАСА Ричард Столарски исследовал и обнаружил, что программное обеспечение НАСА для обработки данных было разработано с учетом предположения, что уровни озона никогда не могут упасть ниже определенного уровня, а обнаруженные очень, очень низкие значения озона автоматически отбрасывались как бессмысленные выбросы. 2
Приборы испытывают различные режимы отказа, иногда даже во время сбора данных. Адам Ринглер и др. предоставить галерею показаний сейсмографа, возникших в результате сбоев приборов (и соответствующих сбоев) в статье 2021 года «Почему мои закорючки выглядят забавно?» 3 Активность в примерах показаний не соответствует фактической сейсмической активности.
Для специалистов по ОД важно понимать:
- Кто собирал данные
- Как и когда были собраны данные и при каких условиях
- Чувствительность и состояние средств измерений
- Как могут выглядеть отказы приборов и человеческие ошибки в конкретном контексте
- Человеческие склонности округлять числа и давать желаемые ответы
Почти всегда существует хотя бы небольшая разница между данными и реальностью, также известная как основная истина . Учет этой разницы является ключом к получению правильных выводов и принятию правильных решений. Это включает в себя решение:
- какие проблемы можно и нужно решить с помощью ML.
- какие проблемы не лучше всего решаются с помощью ML.
- какие проблемы еще не имеют достаточно качественных данных для решения с помощью ML.
Спросите: что в самом строгом и буквальном смысле передают данные? Не менее важно и то, о чем не сообщают данные?
Грязь в данных
Помимо изучения условий сбора данных, сам набор данных может содержать грубые ошибки, ошибки, а также нулевые или недопустимые значения (например, отрицательные измерения концентрации). Краудсорсинговые данные могут быть особенно запутанными. Работа с набором данных неизвестного качества может привести к неточным результатам.
Общие проблемы включают в себя:
- Ошибки в написании строковых значений, таких как место, вид или название бренда.
- Неправильные преобразования единиц измерения, единицы измерения или типы объектов.
- Отсутствующие значения
- Постоянные неправильные классификации или неправильная маркировка
- Значимые цифры, оставшиеся от математических операций, превышающие фактическую чувствительность прибора.
Очистка набора данных часто включает в себя выбор нулевых и отсутствующих значений (сохранить ли их как нулевые, удалить их или заменить нулями), исправление написания до единой версии, исправление единиц измерения и преобразований и т. д. Более продвинутый метод — вменение пропущенных значений, который описан в разделе «Характеристики данных» ускоренного курса машинного обучения.
Выборка, систематическая ошибка выживаемости и проблема суррогатной конечной точки
Статистика позволяет достоверно и точно экстраполировать результаты чисто случайной выборки на большую популяцию. Непроверенная хрупкость этого предположения, а также несбалансированные и неполные данные обучения привели к громким сбоям во многих приложениях ML, включая модели, используемые для проверки резюме и контроля. Это также привело к провалам опросов и другим ошибочным выводам о демографических группах. В большинстве случаев, за исключением искусственных компьютерных данных, чисто случайные выборки слишком дороги и их слишком трудно получить. Вместо этого используются различные обходные пути и доступные прокси, которые создают различные источники предвзятости .
Например, чтобы использовать метод стратифицированной выборки, вам необходимо знать распространенность каждой выбранной страты в более крупной популяции. Если вы предполагаете, что распространенность на самом деле неверна, ваши результаты будут неточными. Аналогичным образом, онлайн-опрос редко представляет собой случайную выборку населения страны, а представляет собой выборку подключенного к Интернету населения (часто из нескольких стран), которое видит опрос и желает принять участие в нем. Эта группа, вероятно, будет отличаться от настоящей случайной выборки. Вопросы в опросе представляют собой образец возможных вопросов. Ответы на эти вопросы опроса, опять же, представляют собой не случайную выборку реальных мнений респондентов, а выборку мнений, которые респонденты готовы высказать, и которые могут отличаться от их фактических мнений.
Клинические исследователи в области здравоохранения сталкиваются с аналогичной проблемой, известной как проблема суррогатной конечной точки . Поскольку проверка влияния препарата на продолжительность жизни пациентов занимает слишком много времени, исследователи используют прокси-биомаркеры, которые, как предполагается, связаны с продолжительностью жизни, но на самом деле это не так. Уровни холестерина используются в качестве суррогатного критерия оценки сердечных приступов и смертей, вызванных сердечно-сосудистыми заболеваниями: если лекарство снижает уровень холестерина, предполагается, что оно также снижает риск сердечно-сосудистых заболеваний. Однако эта цепочка корреляций может быть неверной, или же порядок причинно-следственной связи может отличаться от того, который предполагает исследователь. Дополнительные примеры и подробности см. Вайнтрауб и др., «Опасности суррогатных конечных точек» . Эквивалентная ситуация в ML – это ситуация с прокси-метками .
Математик Абрахам Уолд, как известно, выявил проблему выборки данных, теперь известную как ошибка выжившего . Военные самолеты возвращались с пулевыми отверстиями в одних местах, а не в других. Американские военные хотели добавить больше брони к самолетам в местах с наибольшим количеством пулевых отверстий, но исследовательская группа Уолда рекомендовала вместо этого добавлять броню в области без пулевых отверстий. Они правильно сделали вывод, что их выборка данных была искажена, поскольку самолеты, обстрелянные в этих районах, были настолько сильно повреждены, что не смогли вернуться на базу.
Если бы модель, рекомендовавшая броню, была обучена исключительно на диаграммах возвращающихся боевых самолетов, без учета систематической ошибки выживаемости, присутствующей в данных, эта модель рекомендовала бы укрепить области большим количеством пулевых отверстий.
Предвзятость самоотбора может возникнуть в результате добровольного участия людей в исследовании. Например, заключённые, мотивированные подписаться на программу по снижению рецидивизма, могут представлять собой группу населения, менее склонную к совершению преступлений в будущем, чем основная масса заключённых. Это исказило бы результаты. 4
Более тонкая проблема выборки — это смещение воспоминаний , связанное с податливостью воспоминаний людей. В 1993 году Эдвард Джовануччи спросил группу женщин одинакового возраста, у некоторых из которых был диагностирован рак, об их прошлых пищевых привычках. Те же женщины прошли опрос о пищевых привычках до того, как им поставили диагноз рака. Джованнуччи обнаружил, что женщины без диагноза рака точно помнят свою диету, но женщины с раком молочной железы сообщили, что потребляют больше жиров, чем сообщали ранее, неосознанно давая возможное (хотя и неточное) объяснение их рака. 5
Просить:
- Что на самом деле представляет собой выборка набора данных?
- Сколько уровней выборки имеется?
- Какая систематическая ошибка может возникнуть на каждом уровне выборки?
- Показывают ли используемые косвенные измерения (будь то биомаркер, онлайн-опрос или пулевое отверстие) реальную корреляцию или причинно-следственную связь?
- Чего может не хватать в выборке и методе отбора проб?
Модуль «Справедливость» ускоренного курса машинного обучения охватывает способы оценки и смягчения дополнительных источников систематической ошибки в наборах демографических данных.
Определения и рейтинги
Дайте четкое и точное определение терминам или спросите о ясных и точных определениях. Это необходимо, чтобы понять, какие особенности данных рассматриваются и что именно прогнозируется или утверждается. Чарльз Уилан в книге «Голая статистика » предлагает «здоровье производства в США» в качестве примера неоднозначного термина. Является ли производство в США «здоровым» или нет, полностью зависит от того, как определяется этот термин. Статья Грега Ипа в журнале The Economist, опубликованная в марте 2011 года, иллюстрирует эту двусмысленность. Если показателем «здоровья» является «производство обрабатывающей промышленности», то в 2011 году производство в США было все более здоровым. Однако, если показатель «здоровья» определять как «рабочие места в производстве», то производство в США находилось в упадке. 6
Рейтинги часто страдают от аналогичных проблем, включая неясные или бессмысленные веса, присвоенные различным компонентам рейтинга, непоследовательность рейтингов и недействительные варианты. Малкольм Гладуэлл в статье для The New Yorker упоминает председателя Верховного суда Мичигана Томаса Бреннана, который однажды разослал опрос сотне юристов с просьбой оценить десять юридических школ по качеству: некоторые известные, некоторые нет. Эти юристы поставили юридическую школу Пенсильванского университета примерно на пятое место, хотя на момент опроса в Пенсильванском университете не было юридической школы. 7 Многие известные рейтинги включают в себя столь же субъективный репутационный компонент. Спросите, какие компоненты входят в рейтинг и почему этим компонентам присвоен определенный вес.
Маленькие количества и большие эффекты
Неудивительно, что если вы подбрасываете монету дважды, то выпадет 100% орел или 100% решка. Неудивительно и то, что после подбрасывания монеты четыре раза выпадает 25% орлов, а при следующих четырех подбрасываниях — 75% орлов, хотя это демонстрирует очевидно огромный прирост (который можно ошибочно приписать сэндвичу, съеденному между подходами подбрасываний монеты). или любой другой ложный фактор). Но по мере увеличения количества подбрасываний монеты, скажем, до 1000 или 2000, большие процентные отклонения от ожидаемых 50% становятся исчезающе маловероятными.
Количество измерений или экспериментальных субъектов в исследовании часто обозначается как N. Большие пропорциональные изменения, вызванные случайностью, гораздо чаще происходят в наборах данных и выборках с низким N.
При проведении анализа или документировании набора данных в карте данных укажите N , чтобы другие люди могли учитывать влияние шума и случайности.
Поскольку качество модели имеет тенденцию увеличиваться с увеличением количества примеров, набор данных с низким N обычно приводит к моделям низкого качества.
Регрессия к среднему значению
Точно так же любое измерение, на которое в некоторой степени влияет случайность, подвержено эффекту, известному как регрессия к среднему значению . Это описывает, как измерение после особенно экстремального измерения в среднем может быть менее экстремальным или ближе к среднему значению из-за того, насколько маловероятно, чтобы экстремальное измерение произошло вообще. Эффект более выражен, если для наблюдения была выбрана группа с уровнем выше или ниже среднего, независимо от того, являются ли эта группа самыми высокими людьми в популяции, худшими спортсменами в команде или теми, кто наиболее подвержен риску инсульта. Дети самых высоких людей в среднем, вероятно, будут ниже своих родителей, худшие спортсмены, вероятно, будут показывать лучшие результаты после исключительно неудачного сезона, а те, кто наиболее подвержен риску инсульта, вероятно, продемонстрируют снижение риска после любого вмешательства или лечения. не из-за причинных факторов, а из-за свойств и вероятностей случайности.
Одним из способов смягчения последствий регрессии к среднему значению при изучении вмешательств или лечения для группы с уровнем выше среднего или ниже среднего является разделение субъектов на исследуемую группу и контрольную группу, чтобы изолировать причинные эффекты. В контексте МО это явление предполагает уделять особое внимание любой модели, которая предсказывает исключительные или выпадающие значения, например:
- экстремальная погода или температура
- самые эффективные магазины или спортсмены
- самые популярные видео на сайте
Если текущие прогнозы модели об этих исключительных значениях с течением времени не соответствуют действительности (например, предсказание того, что очень успешный магазин или видео будет продолжать пользоваться успехом, хотя на самом деле это не так), спросите:
- Может ли проблема заключаться в регрессии к среднему значению?
- Действительно ли признаки с наибольшим весом более предсказуемы, чем признаки с меньшим весом?
- Изменяет ли сбор данных, которые имеют базовое значение для этих функций, часто нулевое (по сути, контрольную группу), прогнозы модели?
Ссылки
Хафф, Даррелл. Как лгать со статистикой. Нью-Йорк: WW Нортон, 1954.
Джонс, Бен. Как избежать ошибок в данных. Хобокен, Нью-Джерси: Уайли, 2020.
О'Коннор, Кейлин и Джеймс Оуэн Уэзеролл. Эпоха дезинформации. Нью-Хейвен: Йельский университет, 2019.
Ринглер, Адам, Дэвид Мейсон, Габи Ласке и Мэри Темплтон. «Почему мои закорючки выглядят смешно? Галерея скомпрометированных сейсмических сигналов». Письма о сейсмологических исследованиях 92 вып. 6 (июль 2021 г.). DOI: 10.1785/0220210094
Вайнтрауб, Уильям С., Томас Ф. Люшер и Стюарт Покок. «Опасности суррогатных конечных точек». Европейский кардиологический журнал 36 вып. 33 (сентябрь 2015 г.): 2212–2218. DOI: 10.1093/eurheartj/ehv164.
Уилан, Чарльз. Голая статистика: избавление от страха от данных. Нью-Йорк: WW Нортон, 2013 г.
Ссылка на изображение
«Предвзятость выжившего». Мартин Гранжан, МакГеддон и Кэмерон Молл, 2021 г. CC BY-SA 4.0. Источник
Джонс 25-29. ↩
О'Коннор и Уэзералл 22-3. ↩
Ринглинг и др. ↩
Уилан 120. ↩
Сиддхартха Мукерджи, «Вызывают ли мобильные телефоны рак мозга?» в The New York Times, 13 апреля 2011 г. Цитируется по Wheelan 122. ↩
Уилан 39-40. ↩
Малкольм Гладуэлл, «Порядок вещей» , в The New Yorker , 14 февраля 2011 г. Цитируется в Wheelan 56. ↩
«Мусор на входе, мусор на выходе».
— Пословица раннего программирования
За каждой моделью машинного обучения, каждым расчетом корреляции и каждой рекомендацией политики на основе данных лежит один или несколько наборов необработанных данных. Независимо от того, насколько красивы, ярки или убедительны конечные продукты, если лежащие в основе данные были ошибочными, плохо собранными или низкого качества, результирующая модель, прогноз, визуализация или вывод также будут низкого качества. Любой, кто визуализирует, анализирует и обучает модели на основе наборов данных, должен задавать сложные вопросы об источнике своих данных.
Приборы для сбора данных могут работать со сбоями или быть плохо откалиброваны. Люди, собирающие данные, могут быть уставшими, вредными, непоследовательными или плохо обученными. Люди совершают ошибки, а также разные люди могут обоснованно расходиться во взглядах на классификацию неоднозначных сигналов. В результате может пострадать качество и достоверность данных, и они могут не отражать реальность. Бен Джонс, автор книги «Как избежать ловушек данных », называет это разрывом между данными и реальностью , напоминая читателю: «Это не преступление, это зарегистрированная преступность. Дело не в количестве метеоритных ударов, а в количестве зарегистрированных метеоритных ударов».
Примеры разрыва между данными и реальностью:
Джонс отображает пики измерений времени с 5-минутными интервалами и измерения веса с интервалами 5 фунтов не потому, что такие пики существуют в данных, а потому, что люди, собирающие данные, в отличие от приборов, имеют тенденцию округлять свои числа до ближайшего 0. или 5. 1
В 1985 году Джо Фарман, Брайан Гардинер и Джонатан Шанклин, работавшие в Британской антарктической службе (BAS), обнаружили, что их измерения указывают на сезонную дыру в озоновом слое над южным полушарием. Это противоречило данным НАСА, в которых такой дыры не зафиксировано. Физик НАСА Ричард Столарски исследовал и обнаружил, что программное обеспечение НАСА для обработки данных было разработано с учетом предположения, что уровни озона никогда не могут упасть ниже определенного уровня, а обнаруженные очень, очень низкие значения озона автоматически отбрасывались как бессмысленные выбросы. 2
Приборы испытывают различные режимы отказа, иногда даже во время сбора данных. Адам Ринглер и др. предоставить галерею показаний сейсмографа, возникших в результате сбоев приборов (и соответствующих сбоев) в статье 2021 года «Почему мои закорючки выглядят забавно?» 3 Активность в примерах показаний не соответствует фактической сейсмической активности.
Для специалистов по ОД важно понимать:
- Кто собирал данные
- Как и когда были собраны данные и при каких условиях
- Чувствительность и состояние средств измерений
- Как могут выглядеть отказы приборов и человеческие ошибки в конкретном контексте
- Человеческие склонности округлять числа и давать желаемые ответы
Почти всегда существует хотя бы небольшая разница между данными и реальностью, также известная как основная истина . Учет этой разницы является ключом к получению правильных выводов и принятию правильных решений. Это включает в себя решение:
- какие проблемы можно и нужно решить с помощью ML.
- какие проблемы не лучше всего решаются с помощью ML.
- какие проблемы еще не имеют достаточно качественных данных для решения с помощью ML.
Спросите: что в самом строгом и буквальном смысле передают данные? Не менее важно и то, о чем не сообщают данные?
Грязь в данных
Помимо изучения условий сбора данных, сам набор данных может содержать грубые ошибки, ошибки, а также нулевые или недопустимые значения (например, отрицательные измерения концентрации). Краудсорсинговые данные могут быть особенно запутанными. Работа с набором данных неизвестного качества может привести к неточным результатам.
Общие проблемы включают в себя:
- Ошибки в написании строковых значений, таких как место, вид или название бренда.
- Неправильные преобразования единиц измерения, единицы измерения или типы объектов.
- Отсутствующие значения
- Постоянные неправильные классификации или неправильная маркировка
- Значимые цифры, оставшиеся от математических операций, превышающие фактическую чувствительность прибора.
Очистка набора данных часто включает в себя выбор нулевых и отсутствующих значений (сохранить ли их как нулевые, удалить их или заменить нулями), исправление написания до единой версии, исправление единиц измерения и преобразований и т. д. Более продвинутый метод — вменение пропущенных значений, который описан в разделе «Характеристики данных» ускоренного курса машинного обучения.
Выборка, систематическая ошибка выживаемости и проблема суррогатной конечной точки
Статистика позволяет достоверно и точно экстраполировать результаты чисто случайной выборки на большую популяцию. Непроверенная хрупкость этого предположения, а также несбалансированные и неполные данные обучения привели к громким сбоям во многих приложениях ML, включая модели, используемые для проверки резюме и контроля. Это также привело к провалам опросов и другим ошибочным выводам о демографических группах. В большинстве случаев, за исключением искусственных компьютерных данных, чисто случайные выборки слишком дороги и их слишком трудно получить. Вместо этого используются различные обходные пути и доступные прокси, которые создают различные источники предвзятости .
Например, чтобы использовать метод стратифицированной выборки, вам необходимо знать распространенность каждой выбранной страты в более крупной популяции. Если вы предполагаете, что распространенность на самом деле неверна, ваши результаты будут неточными. Аналогичным образом, онлайн-опрос редко представляет собой случайную выборку населения страны, а представляет собой выборку подключенного к Интернету населения (часто из нескольких стран), которое видит опрос и желает принять участие в нем. Эта группа, вероятно, будет отличаться от настоящей случайной выборки. Вопросы в опросе представляют собой образец возможных вопросов. Ответы на эти вопросы опроса, опять же, представляют собой не случайную выборку реальных мнений респондентов, а выборку мнений, которые респонденты готовы высказать, и которые могут отличаться от их фактических мнений.
Клинические исследователи в области здравоохранения сталкиваются с аналогичной проблемой, известной как проблема суррогатной конечной точки . Поскольку проверка влияния препарата на продолжительность жизни пациентов занимает слишком много времени, исследователи используют прокси-биомаркеры, которые, как предполагается, связаны с продолжительностью жизни, но на самом деле это не так. Уровни холестерина используются в качестве суррогатного критерия оценки сердечных приступов и смертей, вызванных сердечно-сосудистыми заболеваниями: если лекарство снижает уровень холестерина, предполагается, что оно также снижает риск сердечно-сосудистых заболеваний. Однако эта цепочка корреляций может быть неверной, или же порядок причинно-следственной связи может отличаться от того, который предполагает исследователь. Дополнительные примеры и подробности см. Вайнтрауб и др., «Опасности суррогатных конечных точек» . Эквивалентная ситуация в ML – это ситуация с прокси-метками .
Математик Абрахам Уолд, как известно, выявил проблему выборки данных, теперь известную как ошибка выжившего . Военные самолеты возвращались с пулевыми отверстиями в одних местах, а не в других. Американские военные хотели добавить больше брони к самолетам в местах с наибольшим количеством пулевых отверстий, но исследовательская группа Уолда рекомендовала вместо этого добавлять броню в области без пулевых отверстий. Они правильно сделали вывод, что их выборка данных была искажена, поскольку самолеты, обстрелянные в этих районах, были настолько сильно повреждены, что не смогли вернуться на базу.
Если бы модель, рекомендовавшая броню, была обучена исключительно на диаграммах возвращающихся боевых самолетов, без учета систематической ошибки выживаемости, присутствующей в данных, эта модель рекомендовала бы укрепить области большим количеством пулевых отверстий.
Предвзятость самоотбора может возникнуть в результате добровольного участия людей в исследовании. Например, заключённые, мотивированные подписаться на программу по снижению рецидивизма, могут представлять собой группу населения, менее склонную к совершению преступлений в будущем, чем основная масса заключённых. Это исказило бы результаты. 4
Более тонкая проблема выборки — это смещение воспоминаний , связанное с податливостью воспоминаний людей. В 1993 году Эдвард Джовануччи спросил группу женщин одинакового возраста, у некоторых из которых был диагностирован рак, об их прошлых пищевых привычках. Те же женщины прошли опрос о пищевых привычках до того, как им поставили диагноз рака. Джованнуччи обнаружил, что женщины без диагноза рака точно помнят свою диету, но женщины с раком молочной железы сообщили, что потребляют больше жиров, чем сообщали ранее, неосознанно давая возможное (хотя и неточное) объяснение их рака. 5
Просить:
- Что на самом деле представляет собой выборка набора данных?
- Сколько уровней выборки имеется?
- Какая систематическая ошибка может возникнуть на каждом уровне выборки?
- Показывают ли используемые косвенные измерения (будь то биомаркер, онлайн-опрос или пулевое отверстие) реальную корреляцию или причинно-следственную связь?
- Чего может не хватать в выборке и методе отбора проб?
Модуль «Справедливость» ускоренного курса машинного обучения охватывает способы оценки и смягчения дополнительных источников систематической ошибки в наборах демографических данных.
Определения и рейтинги
Дайте четкое и точное определение терминам или спросите о ясных и точных определениях. Это необходимо, чтобы понять, какие особенности данных рассматриваются и что именно прогнозируется или утверждается. Чарльз Уилан в книге «Голая статистика » предлагает «здоровье производства в США» в качестве примера неоднозначного термина. Является ли производство в США «здоровым» или нет, полностью зависит от того, как определяется этот термин. Статья Грега Ипа в журнале The Economist, опубликованная в марте 2011 года, иллюстрирует эту двусмысленность. Если показателем «здоровья» является «производство обрабатывающей промышленности», то в 2011 году производство в США было все более здоровым. Однако, если показатель «здоровья» определять как «рабочие места в производстве», то производство в США находилось в упадке. 6
Рейтинги часто страдают от аналогичных проблем, включая неясные или бессмысленные веса, присвоенные различным компонентам рейтинга, непоследовательность рейтингов и недействительные варианты. Малкольм Гладуэлл в статье для The New Yorker упоминает председателя Верховного суда Мичигана Томаса Бреннана, который однажды разослал опрос сотне юристов с просьбой оценить десять юридических школ по качеству: некоторые известные, некоторые нет. Эти юристы поставили юридическую школу Пенсильванского университета примерно на пятое место, хотя на момент опроса в Пенсильванском университете не было юридической школы. 7 Многие известные рейтинги включают в себя столь же субъективный репутационный компонент. Спросите, какие компоненты входят в рейтинг и почему этим компонентам присвоен определенный вес.
Маленькие количества и большие эффекты
Неудивительно, что если вы подбрасываете монету дважды, то выпадет 100% орел или 100% решка. Неудивительно и то, что после подбрасывания монеты четыре раза выпадает 25% орлов, а при следующих четырех подбрасываниях — 75% орлов, хотя это демонстрирует очевидно огромный прирост (который можно ошибочно приписать сэндвичу, съеденному между подходами подбрасываний монеты). или любой другой ложный фактор). Но по мере увеличения количества подбрасываний монеты, скажем, до 1000 или 2000, большие процентные отклонения от ожидаемых 50% становятся исчезающе маловероятными.
Количество измерений или экспериментальных субъектов в исследовании часто обозначается как N. Большие пропорциональные изменения, вызванные случайностью, гораздо чаще происходят в наборах данных и выборках с низким N.
При проведении анализа или документировании набора данных в карте данных укажите N , чтобы другие люди могли учитывать влияние шума и случайности.
Поскольку качество модели имеет тенденцию увеличиваться с увеличением количества примеров, набор данных с низким N обычно приводит к моделям низкого качества.
Регрессия к среднему значению
Точно так же любое измерение, на которое в некоторой степени влияет случайность, подвержено эффекту, известному как регрессия к среднему значению . Это описывает, как измерение после особенно экстремального измерения в среднем может быть менее экстремальным или ближе к среднему значению из-за того, насколько маловероятно, чтобы экстремальное измерение произошло вообще. Эффект более выражен, если для наблюдения была выбрана группа с уровнем выше или ниже среднего, независимо от того, являются ли эта группа самыми высокими людьми в популяции, худшими спортсменами в команде или теми, кто наиболее подвержен риску инсульта. Дети самых высоких людей в среднем, вероятно, будут ниже своих родителей, худшие спортсмены, вероятно, будут показывать лучшие результаты после исключительно неудачного сезона, а те, кто наиболее подвержен риску инсульта, вероятно, продемонстрируют снижение риска после любого вмешательства или лечения. не из-за причинных факторов, а из-за свойств и вероятностей случайности.
Одним из способов смягчения последствий регрессии к среднему значению при изучении вмешательств или лечения для группы с уровнем выше среднего или ниже среднего является разделение субъектов на исследуемую группу и контрольную группу, чтобы изолировать причинные эффекты. В контексте МО это явление предполагает уделять особое внимание любой модели, которая предсказывает исключительные или выпадающие значения, например:
- экстремальная погода или температура
- самые эффективные магазины или спортсмены
- самые популярные видео на сайте
Если текущие прогнозы модели об этих исключительных значениях с течением времени не соответствуют действительности (например, предсказание того, что очень успешный магазин или видео будет продолжать пользоваться успехом, хотя на самом деле это не так), спросите:
- Может ли проблема заключаться в регрессии к среднему значению?
- Действительно ли признаки с наибольшим весом более предсказуемы, чем признаки с меньшим весом?
- Изменяет ли сбор данных, которые имеют базовое значение для этих функций, часто нулевое (по сути, контрольную группу), прогнозы модели?
Ссылки
Хафф, Даррелл. Как лгать со статистикой. Нью-Йорк: WW Нортон, 1954.
Джонс, Бен. Как избежать ошибок в данных. Хобокен, Нью-Джерси: Уайли, 2020.
О'Коннор, Кейлин и Джеймс Оуэн Уэзеролл. Эпоха дезинформации. Нью-Хейвен: Йельский университет, 2019.
Ринглер, Адам, Дэвид Мейсон, Габи Ласке и Мэри Темплтон. «Почему мои закорючки выглядят смешно? Галерея скомпрометированных сейсмических сигналов». Письма о сейсмологических исследованиях 92 вып. 6 (июль 2021 г.). DOI: 10.1785/0220210094
Вайнтрауб, Уильям С., Томас Ф. Люшер и Стюарт Покок. «Опасности суррогатных конечных точек». Европейский кардиологический журнал 36 вып. 33 (сентябрь 2015 г.): 2212–2218. DOI: 10.1093/eurheartj/ehv164.
Уилан, Чарльз. Голая статистика: избавление от страха от данных. Нью-Йорк: WW Нортон, 2013 г.
Ссылка на изображение
«Предвзятость выжившего». Мартин Гранжан, МакГеддон и Кэмерон Молл, 2021 г. CC BY-SA 4.0. Источник
Джонс 25-29. ↩
О'Коннор и Уэзералл 22-3. ↩
Ринглинг и др. ↩
Уилан 120. ↩
Сиддхартха Мукерджи, «Вызывают ли мобильные телефоны рак мозга?» в The New York Times, 13 апреля 2011 г. Цитируется по Wheelan 122. ↩
Уилан 39-40. ↩
Малкольм Гладуэлл, «Порядок вещей» , в The New Yorker , 14 февраля 2011 г. Цитируется в Wheelan 56. ↩
«Мусор на входе, мусор на выходе».
— Пословица раннего программирования
За каждой моделью машинного обучения, каждым расчетом корреляции и каждой рекомендацией политики на основе данных лежит один или несколько наборов необработанных данных. Независимо от того, насколько красивы, ярки или убедительны конечные продукты, если лежащие в основе данные были ошибочными, плохо собранными или низкого качества, результирующая модель, прогноз, визуализация или вывод также будут низкого качества. Любой, кто визуализирует, анализирует и обучает модели на основе наборов данных, должен задавать сложные вопросы об источнике своих данных.
Приборы для сбора данных могут работать со сбоями или быть плохо откалиброваны. Люди, собирающие данные, могут быть уставшими, вредными, непоследовательными или плохо обученными. Люди совершают ошибки, а также разные люди могут обоснованно расходиться во взглядах на классификацию неоднозначных сигналов. В результате может пострадать качество и достоверность данных, и они могут не отражать реальность. Бен Джонс, автор книги «Как избежать ловушек данных », называет это разрывом между данными и реальностью , напоминая читателю: «Это не преступление, это зарегистрированная преступность. Дело не в количестве метеоритных ударов, а в количестве зарегистрированных метеоритных ударов».
Примеры разрыва между данными и реальностью:
Джонс отображает пики измерений времени с 5-минутными интервалами и измерения веса с интервалами 5 фунтов не потому, что такие пики существуют в данных, а потому, что люди, собирающие данные, в отличие от приборов, имеют тенденцию округлять свои числа до ближайшего 0. или 5. 1
В 1985 году Джо Фарман, Брайан Гардинер и Джонатан Шанклин, работавшие в Британской антарктической службе (BAS), обнаружили, что их измерения указывают на сезонную дыру в озоновом слое над южным полушарием. Это противоречило данным НАСА, в которых такой дыры не зафиксировано. Физик НАСА Ричард Столарски исследовал и обнаружил, что программное обеспечение НАСА для обработки данных было разработано с учетом предположения, что уровни озона никогда не могут упасть ниже определенного уровня, а обнаруженные очень, очень низкие значения озона автоматически отбрасывались как бессмысленные выбросы. 2
Приборы испытывают различные режимы отказа, иногда даже во время сбора данных. Адам Ринглер и др. предоставить галерею показаний сейсмографа, возникших в результате сбоев приборов (и соответствующих сбоев) в статье 2021 года «Почему мои закорючки выглядят забавно?» 3 Активность в примерах показаний не соответствует фактической сейсмической активности.
Для специалистов по ОД важно понимать:
- Кто собирал данные
- Как и когда были собраны данные и при каких условиях
- Чувствительность и состояние средств измерений
- Как могут выглядеть отказы приборов и человеческие ошибки в конкретном контексте
- Человеческие склонности округлять числа и давать желаемые ответы
Почти всегда существует хотя бы небольшая разница между данными и реальностью, также известная как основная истина . Учет этой разницы является ключом к получению правильных выводов и принятию правильных решений. Это включает в себя решение:
- какие проблемы можно и нужно решить с помощью ML.
- какие проблемы не лучше всего решаются с помощью ML.
- какие проблемы еще не имеют достаточно качественных данных для решения с помощью ML.
Спросите: что в самом строгом и буквальном смысле передают данные? Не менее важно и то, о чем не сообщают данные?
Грязь в данных
Помимо изучения условий сбора данных, сам набор данных может содержать грубые ошибки, ошибки, а также нулевые или недопустимые значения (например, отрицательные измерения концентрации). Краудсорсинговые данные могут быть особенно запутанными. Работа с набором данных неизвестного качества может привести к неточным результатам.
Общие проблемы включают в себя:
- Ошибки в написании строковых значений, таких как место, вид или название бренда.
- Неправильные преобразования единиц измерения, единицы измерения или типы объектов.
- Отсутствующие значения
- Постоянные неправильные классификации или неправильная маркировка
- Значимые цифры, оставшиеся от математических операций, превышающие фактическую чувствительность прибора.
Очистка набора данных часто включает в себя выбор нулевых и отсутствующих значений (сохранить ли их как нулевые, удалить их или заменить нулями), исправление написания до единой версии, исправление единиц измерения и преобразований и т. д. Более продвинутый метод — вменение пропущенных значений, который описан в разделе «Характеристики данных» ускоренного курса машинного обучения.
Выборка, систематическая ошибка выживаемости и проблема суррогатной конечной точки
Статистика позволяет достоверно и точно экстраполировать результаты чисто случайной выборки на большую популяцию. Непроверенная хрупкость этого предположения, а также несбалансированные и неполные данные обучения привели к громким сбоям во многих приложениях ML, включая модели, используемые для проверки резюме и контроля. Это также привело к провалам опросов и другим ошибочным выводам о демографических группах. В большинстве случаев, за исключением искусственных компьютерных данных, чисто случайные выборки слишком дороги и их слишком трудно получить. Вместо этого используются различные обходные пути и доступные прокси, которые создают различные источники предвзятости .
Например, чтобы использовать метод стратифицированной выборки, вам необходимо знать распространенность каждой выбранной страты в более крупной популяции. Если вы предполагаете, что распространенность на самом деле неверна, ваши результаты будут неточными. Аналогичным образом, онлайн-опрос редко представляет собой случайную выборку населения страны, а представляет собой выборку подключенного к Интернету населения (часто из нескольких стран), которое видит опрос и желает принять участие в нем. Эта группа, вероятно, будет отличаться от настоящей случайной выборки. Вопросы в опросе представляют собой образец возможных вопросов. Ответы на эти вопросы опроса, опять же, представляют собой не случайную выборку реальных мнений респондентов, а выборку мнений, которые респонденты готовы высказать, и которые могут отличаться от их фактических мнений.
Клинические исследователи в области здравоохранения сталкиваются с аналогичной проблемой, известной как проблема суррогатной конечной точки . Поскольку проверка влияния препарата на продолжительность жизни пациентов занимает слишком много времени, исследователи используют прокси-биомаркеры, которые, как предполагается, связаны с продолжительностью жизни, но на самом деле это не так. Уровни холестерина используются в качестве суррогатного критерия оценки сердечных приступов и смертей, вызванных сердечно-сосудистыми заболеваниями: если лекарство снижает уровень холестерина, предполагается, что оно также снижает риск сердечно-сосудистых заболеваний. Однако эта цепочка корреляций может быть неверной, или же порядок причинно-следственной связи может отличаться от того, который предполагает исследователь. Дополнительные примеры и подробности см. Вайнтрауб и др., «Опасности суррогатных конечных точек» . Эквивалентная ситуация в ML – это ситуация с прокси-метками .
Математик Абрахам Уолд, как известно, выявил проблему выборки данных, теперь известную как ошибка выжившего . Военные самолеты возвращались с пулевыми отверстиями в одних местах, а не в других. Американские военные хотели добавить больше брони к самолетам в местах с наибольшим количеством пулевых отверстий, но исследовательская группа Уолда рекомендовала вместо этого добавлять броню в области без пулевых отверстий. Они правильно сделали вывод, что их выборка данных была искажена, поскольку самолеты, обстрелянные в этих районах, были настолько сильно повреждены, что не смогли вернуться на базу.
Если бы модель, рекомендовавшая броню, была обучена исключительно на диаграммах возвращающихся боевых самолетов, без учета систематической ошибки выживаемости, присутствующей в данных, эта модель рекомендовала бы укрепить области большим количеством пулевых отверстий.
Предвзятость самоотбора может возникнуть в результате добровольного участия людей в исследовании. Например, заключённые, мотивированные подписаться на программу по снижению рецидивизма, могут представлять собой группу населения, менее склонную к совершению преступлений в будущем, чем основная масса заключённых. Это исказило бы результаты. 4
Более тонкая проблема выборки — это смещение воспоминаний , связанное с податливостью воспоминаний людей. В 1993 году Эдвард Джовануччи спросил группу женщин одинакового возраста, у некоторых из которых был диагностирован рак, об их прошлых пищевых привычках. Те же женщины прошли опрос о пищевых привычках до того, как им поставили диагноз рака. Джованнуччи обнаружил, что женщины без диагноза рака точно помнят свою диету, но женщины с раком молочной железы сообщили, что потребляют больше жиров, чем сообщали ранее, неосознанно давая возможное (хотя и неточное) объяснение их рака. 5
Просить:
- Что на самом деле представляет собой выборка набора данных?
- Сколько уровней выборки имеется?
- Какая систематическая ошибка может возникнуть на каждом уровне выборки?
- Показывают ли используемые косвенные измерения (будь то биомаркер, онлайн-опрос или пулевое отверстие) реальную корреляцию или причинно-следственную связь?
- Чего может не хватать в выборке и методе отбора проб?
Модуль «Справедливость» ускоренного курса машинного обучения охватывает способы оценки и смягчения дополнительных источников систематической ошибки в наборах демографических данных.
Определения и рейтинги
Дайте четкое и точное определение терминам или спросите о ясных и точных определениях. Это необходимо, чтобы понять, какие особенности данных рассматриваются и что именно прогнозируется или утверждается. Чарльз Уилан в книге «Голая статистика » предлагает «здоровье производства в США» в качестве примера неоднозначного термина. Является ли производство в США «здоровым» или нет, полностью зависит от того, как определяется этот термин. Статья Грега Ипа в журнале The Economist, опубликованная в марте 2011 года, иллюстрирует эту двусмысленность. Если показателем «здоровья» является «производство обрабатывающей промышленности», то в 2011 году производство в США было все более здоровым. Однако, если показатель «здоровья» определять как «рабочие места в производстве», то производство в США находилось в упадке. 6
Рейтинги часто страдают от аналогичных проблем, включая неясные или бессмысленные веса, присвоенные различным компонентам рейтинга, непоследовательность рейтингов и недействительные варианты. Малкольм Гладуэлл в статье для The New Yorker упоминает председателя Верховного суда Мичигана Томаса Бреннана, который однажды разослал опрос сотне юристов с просьбой оценить десять юридических школ по качеству: некоторые известные, некоторые нет. Эти юристы поставили юридическую школу Пенсильванского университета примерно на пятое место, хотя на момент опроса в Пенсильванском университете не было юридической школы. 7 Многие известные рейтинги включают в себя столь же субъективный репутационный компонент. Спросите, какие компоненты входят в рейтинг и почему этим компонентам присвоен определенный вес.
Маленькие количества и большие эффекты
Неудивительно, что если вы подбрасываете монету дважды, то выпадет 100% орел или 100% решка. Неудивительно и то, что после подбрасывания монеты четыре раза выпадает 25% орлов, а при следующих четырех подбрасываниях — 75% орлов, хотя это демонстрирует очевидно огромный прирост (который можно ошибочно приписать сэндвичу, съеденному между подходами подбрасываний монеты). или любой другой ложный фактор). Но по мере увеличения количества подбрасываний монеты, скажем, до 1000 или 2000, большие процентные отклонения от ожидаемых 50% становятся исчезающе маловероятными.
Количество измерений или экспериментальных субъектов в исследовании часто обозначается как N. Большие пропорциональные изменения, вызванные случайностью, гораздо чаще происходят в наборах данных и выборках с низким N.
При проведении анализа или документировании набора данных в карте данных укажите N , чтобы другие люди могли учитывать влияние шума и случайности.
Поскольку качество модели имеет тенденцию увеличиваться с увеличением количества примеров, набор данных с низким N обычно приводит к моделям низкого качества.
Регрессия к среднему значению
Точно так же любое измерение, на которое в некоторой степени влияет случайность, подвержено эффекту, известному как регрессия к среднему значению . Это описывает, как измерение после особенно экстремального измерения в среднем может быть менее экстремальным или ближе к среднему значению из-за того, насколько маловероятно, чтобы экстремальное измерение произошло вообще. Эффект более выражен, если для наблюдения была выбрана группа с уровнем выше или ниже среднего, независимо от того, являются ли эта группа самыми высокими людьми в популяции, худшими спортсменами в команде или теми, кто наиболее подвержен риску инсульта. Дети самых высоких людей в среднем, вероятно, будут ниже своих родителей, худшие спортсмены, вероятно, будут показывать лучшие результаты после исключительно неудачного сезона, а те, кто наиболее подвержен риску инсульта, вероятно, продемонстрируют снижение риска после любого вмешательства или лечения. не из-за причинных факторов, а из-за свойств и вероятностей случайности.
Одним из способов смягчения последствий регрессии к среднему значению при изучении вмешательств или лечения для группы с уровнем выше среднего или ниже среднего является разделение субъектов на исследуемую группу и контрольную группу, чтобы изолировать причинные эффекты. В контексте МО это явление предполагает уделять особое внимание любой модели, которая предсказывает исключительные или выпадающие значения, например:
- экстремальная погода или температура
- самые эффективные магазины или спортсмены
- самые популярные видео на сайте
Если текущие прогнозы модели об этих исключительных значениях с течением времени не соответствуют действительности (например, предсказание того, что очень успешный магазин или видео будет продолжать пользоваться успехом, хотя на самом деле это не так), спросите:
- Может ли проблема заключаться в регрессии к среднему значению?
- Действительно ли признаки с наибольшим весом более предсказуемы, чем признаки с меньшим весом?
- Изменяет ли сбор данных, которые имеют базовое значение для этих функций, часто нулевое (по сути, контрольную группу), прогнозы модели?
Ссылки
Хафф, Даррелл. Как лгать со статистикой. Нью-Йорк: WW Нортон, 1954.
Джонс, Бен. Как избежать ошибок в данных. Хобокен, Нью-Джерси: Уайли, 2020.
О'Коннор, Кейлин и Джеймс Оуэн Уэзеролл. Эпоха дезинформации. Нью-Хейвен: Йельский университет, 2019.
Ринглер, Адам, Дэвид Мейсон, Габи Ласке и Мэри Темплтон. «Почему мои закорючки выглядят смешно? Галерея скомпрометированных сейсмических сигналов». Письма о сейсмологических исследованиях 92 вып. 6 (июль 2021 г.). DOI: 10.1785/0220210094
Вайнтрауб, Уильям С., Томас Ф. Люшер и Стюарт Покок. «Опасности суррогатных конечных точек». Европейский кардиологический журнал 36 вып. 33 (сентябрь 2015 г.): 2212–2218. DOI: 10.1093/eurheartj/ehv164.
Уилан, Чарльз. Голая статистика: избавление от страха от данных. Нью-Йорк: WW Нортон, 2013 г.
Ссылка на изображение
«Предвзятость выжившего». Мартин Гранжан, МакГеддон и Кэмерон Молл, 2021 г. CC BY-SA 4.0. Источник
Джонс 25-29. ↩
О'Коннор и Уэзералл 22-3. ↩
Ринглинг и др. ↩
Уилан 120. ↩
Сиддхартха Мукерджи, «Вызывают ли мобильные телефоны рак мозга?» в The New York Times, 13 апреля 2011 г. Цитируется по Wheelan 122. ↩
Уилан 39-40. ↩
Малкольм Гладуэлл, «Порядок вещей» , в The New Yorker , 14 февраля 2011 г. Цитируется в Wheelan 56. ↩