Algorytmy klasyfikacji tekstu są podstawą różnych systemów, które przetwarzają dane tekstowe na dużą skalę. Oprogramowanie do obsługi e-maili wykorzystuje klasyfikację tekstu, aby określić, czy poczta przychodząca jest wysyłana do skrzynki odbiorczej czy filtrowana do folderu spamu. Fora dyskusyjne używają klasyfikacji tekstu do określania, czy komentarze powinny zostać oznaczone jako nieodpowiednie.
Są to 2 przykłady klasyfikacji tematów: kategoryzowanie dokumentu tekstowego do jednego z gotowych zestawów tematów. W wielu kwestiach związanych z tematem ta klasyfikacja opiera się głównie na słowach kluczowych w tekście.
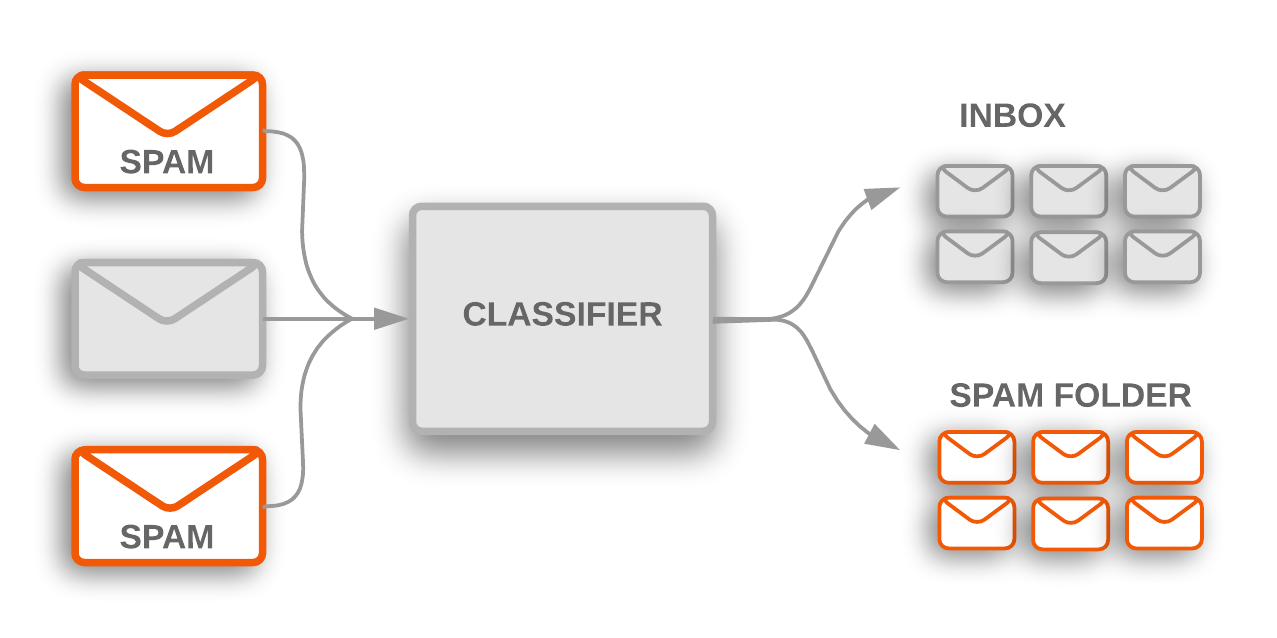
Rysunek 1. Klasyfikacja tematów służy do oznaczania przychodzących e-maili ze spamem, które są odfiltrowywane do folderu spamu.
Inną typową klasyfikacją tekstu jest analiza nastawienia, której celem jest określenie biegłości w treści tekstu: typ opinii, którą wyraża. Może to mieć formę binarnej oceny pozytywnej lub negatywnej bądź bardziej szczegółowego zestawu opcji, takich jak liczba gwiazdek od 1 do 5. Przykładem analizy może być analiza postów na Twitterze w celu określenia, czy użytkownikowi podoba się film „Czarna pantera” lub reakcja opinii publicznej na temat nowej marki butów Nike na podstawie opinii Walmart.
W tym przewodniku znajdziesz sprawdzone metody dotyczące systemów uczących się służące do rozwiązywania problemów z klasyfikacją tekstu. Dowiesz się, jak:
- Wysoki, kompleksowy przepływ pracy do rozwiązywania problemów z klasyfikacją tekstu za pomocą systemów uczących się
- Jak wybrać odpowiedni model problemu z klasyfikacją tekstu
- Jak wdrożyć wybrany model za pomocą TensorFlow
Przepływ pracy klasyfikacji tekstu
Oto ogólny przegląd przepływu pracy używany do rozwiązywania problemów z systemami uczącymi się:
- Krok 1. Zbierz dane
- Krok 2. Sprawdź swoje dane
- Krok 2.5. Wybierz model*
- Krok 3. Przygotuj dane
- Krok 4. Tworzenie, trenowanie i ocena modelu
- Krok 5. Dostosuj hiperparametry
- Krok 6. Wdróż model

Rysunek 2. Procedura rozwiązywania problemów z systemami uczącymi się
Poniżej znajdziesz szczegółowe omówienie każdego kroku i sposób implementacji tych danych w danych tekstowych.