Les algorithmes de classification de texte sont au cœur de nombreux systèmes logiciels qui traitent les données textuelles à grande échelle. Le logiciel de messagerie utilise la classification du texte pour déterminer si les messages entrants sont envoyés dans la boîte de réception ou filtrés dans le dossier "Spam". Les forums de discussion utilisent la classification du texte pour déterminer si les commentaires doivent être signalés comme inappropriés.
Il s'agit de deux exemples de classification de sujets, catégorisant un document texte dans l'un des ensembles prédéfinis de sujets. Dans de nombreux problèmes de classification thématique, cette catégorisation est principalement basée sur les mots clés contenus dans le texte.
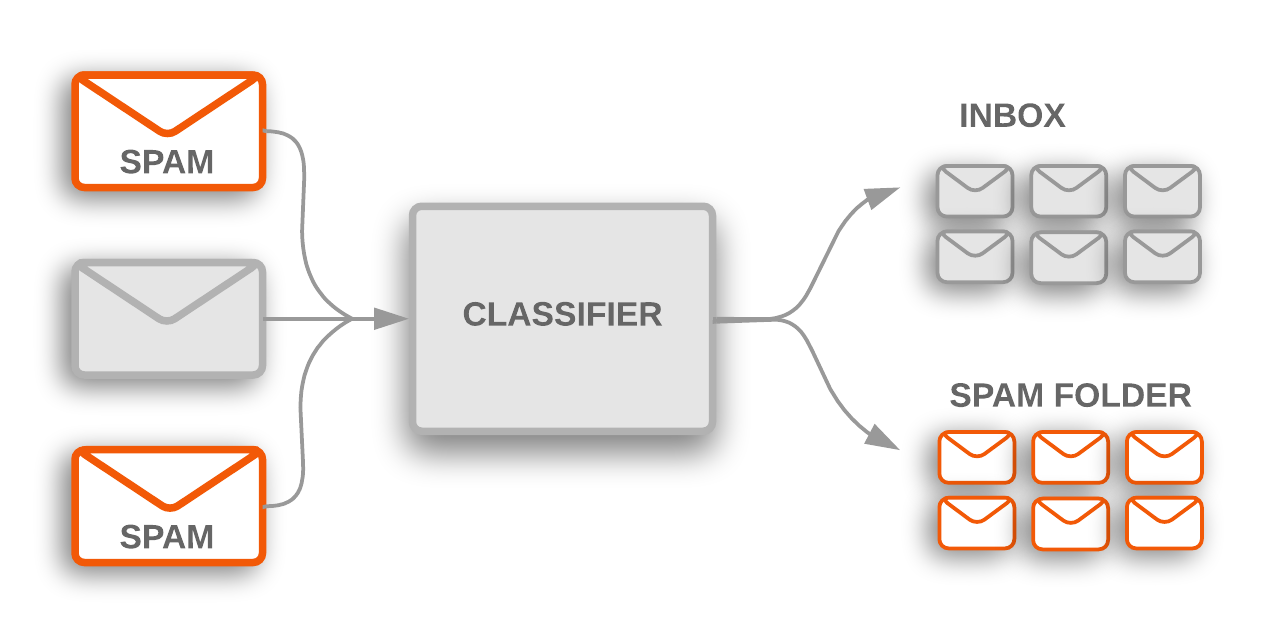
Figure 1: La classification des sujets permet de repérer les spams entrants qui sont filtrés dans un dossier de spam.
Un autre type de classification de texte courant est l'analyse des sentiments, qui vise à identifier la polarité du contenu textuel: le type d'opinion qu'il exprime. Il peut s'agir d'une note binaire "J'aime"/"Je n'aime pas" ou d'un ensemble plus précis d'options, comme une note entre 1 et 5. Par exemple, l'analyse des sentiments consiste à analyser les posts Twitter pour déterminer si les internautes ont aimé le film "La Panthère Noire", ou à extrapoler l'opinion générale du public concernant une nouvelle marque de chaussures Nike à partir des avis de Walmart.
Ce guide présente des bonnes pratiques essentielles de machine learning pour résoudre les problèmes de classification de texte. Dans ce document, vous découvrirez :
- Workflow de bout en bout permettant de résoudre les problèmes de classification de texte à l'aide du machine learning
- Choisir le modèle adapté à votre problème de classification de texte
- Implémenter le modèle de votre choix avec TensorFlow
Workflow de classification de texte
Voici une vue d'ensemble du workflow utilisé pour résoudre les problèmes liés au machine learning:
- Étape 1: Collectez les données
- Étape 2: Explorez vos données
- Étape 2.5: Choisir un modèle*
- Étape 3: Préparez vos données
- Étape 4: Créez, entraînez et évaluez votre modèle
- Étape 5: Ajustez les hyperparamètres
- Étape 6: Déployez votre modèle

Figure 2: Workflow pour résoudre les problèmes de machine learning
Les sections suivantes décrivent chaque étape en détail et expliquent comment les implémenter pour des données textuelles.