Jetzt haben wir unser Dataset zusammengestellt und Erkenntnisse zu den wichtigsten Merkmalen unserer Daten gewonnen. Als Nächstes sollten wir basierend auf den in Schritt 2 gesammelten Messwerten überlegen, welches Klassifizierungsmodell wir verwenden sollten. Das bedeutet, Fragen zu stellen wie:
- Wie präsentieren Sie die Textdaten einem Algorithmus, der numerische Eingaben erwartet? Dies wird als Datenvorverarbeitung und Vektorisierung bezeichnet.
- Welche Art von Modell sollten Sie verwenden?
- Welche Konfigurationsparameter sollten Sie für Ihr Modell verwenden?
Dank jahrzehntelanger Forschung haben wir Zugriff auf eine Vielzahl von Optionen zur Datenvorverarbeitung und Modellkonfiguration. Die Verfügbarkeit einer sehr großen Auswahl möglicher Optionen kann jedoch die Komplexität und den Umfang eines bestimmten Problems erheblich erhöhen. Da die besten Optionen vielleicht nicht offensichtlich sind, wäre eine naive Lösung darin, alle möglichen Optionen vollständig auszuprobieren und einige Auswahlmöglichkeiten durch Intuition zu kürzen. Das wäre jedoch enorm teuer.
In diesem Leitfaden versuchen wir, die Auswahl eines Textklassifizierungsmodells erheblich zu vereinfachen. Unser Ziel für ein bestimmtes Dataset ist es, den Algorithmus zu finden, der nahezu maximale Genauigkeit erreicht und gleichzeitig die für das Training erforderliche Rechenzeit minimiert. Wir haben mit 12 Datasets eine große Anzahl (ca. 450.000) für Probleme verschiedener Typen (insbesondere Probleme bei der Sentimentanalyse und Klassifizierung von Themen) mit 12 Datasets durchgeführt, wobei sich für jedes Dataset verschiedene Datenvorverarbeitungstechniken und verschiedene Modellarchitekturen abwechseln. So konnten wir Dataset-Parameter identifizieren, die optimale Entscheidungen beeinflussen.
Der Algorithmus und das Flussdiagramm für die Modellauswahl unten sind eine Zusammenfassung unserer Experimente. Es ist kein Problem, wenn Sie noch nicht alle verwendeten Begriffe verstehen. In den folgenden Abschnitten dieses Leitfadens werden sie ausführlich erläutert.
Algorithmus für Datenvorbereitung und Modellerstellung
- Berechnen Sie die Anzahl der Stichproben/die Anzahl der Wörter pro Stichprobenverhältnis.
- Wenn dieses Verhältnis kleiner als 1.500 ist, tokenisieren Sie den Text als n-Gramme und verwenden Sie ein einfaches Multi-Layer-Perceptron-Modell (MLP), um sie zu klassifizieren (linker Zweig im Flussdiagramm unten):
- Die Proben in Wort-N-Gramme aufteilen und die N-Gramme in Vektoren umwandeln.
- Bewerten Sie die Bedeutung der Vektoren und wählen Sie dann die besten 20.000 mithilfe der Punktzahlen aus.
- MLP-Modell erstellen
- Wenn das Verhältnis größer als 1.500 ist, tokenisieren Sie den Text als Sequenzen und verwenden Sie ein sepCNN-Modell, um sie zu klassifizieren (rechter Zweig im folgenden Flussdiagramm):
- Teilen Sie die Beispiele in Wörter auf und wählen Sie die 20.000 Wörter mit der größten Häufigkeit basierend auf ihrer Häufigkeit aus.
- Konvertieren Sie die Beispiele in Wortsequenzvektoren.
- Wenn die ursprüngliche Anzahl von Stichproben/Wörtern pro Stichprobenverhältnis weniger als 15.000 beträgt, werden mit einer fein abgestimmten vortrainierten Einbettung mit dem sepCNN-Modell wahrscheinlich die besten Ergebnisse erzielt.
- Messen Sie die Modellleistung mit verschiedenen Hyperparameter-Werten, um die beste Modellkonfiguration für das Dataset zu ermitteln.
Im folgenden Flussdiagramm stehen die gelben Felder für Daten- und Modellvorbereitungsprozesse. Graue und grüne Felder zeigen Auswahlmöglichkeiten an, die wir für jeden Prozess in Betracht gezogen haben. Grüne Kästchen zeigen unsere empfohlene Auswahl für den jeweiligen Prozess an.
Sie können dieses Flussdiagramm als Ausgangspunkt für Ihren ersten Test verwenden, da es Ihnen eine hohe Genauigkeit bei geringen Berechnungskosten bietet. Sie können Ihr ursprüngliches Modell dann in den nachfolgenden Iterationen weiter verbessern.
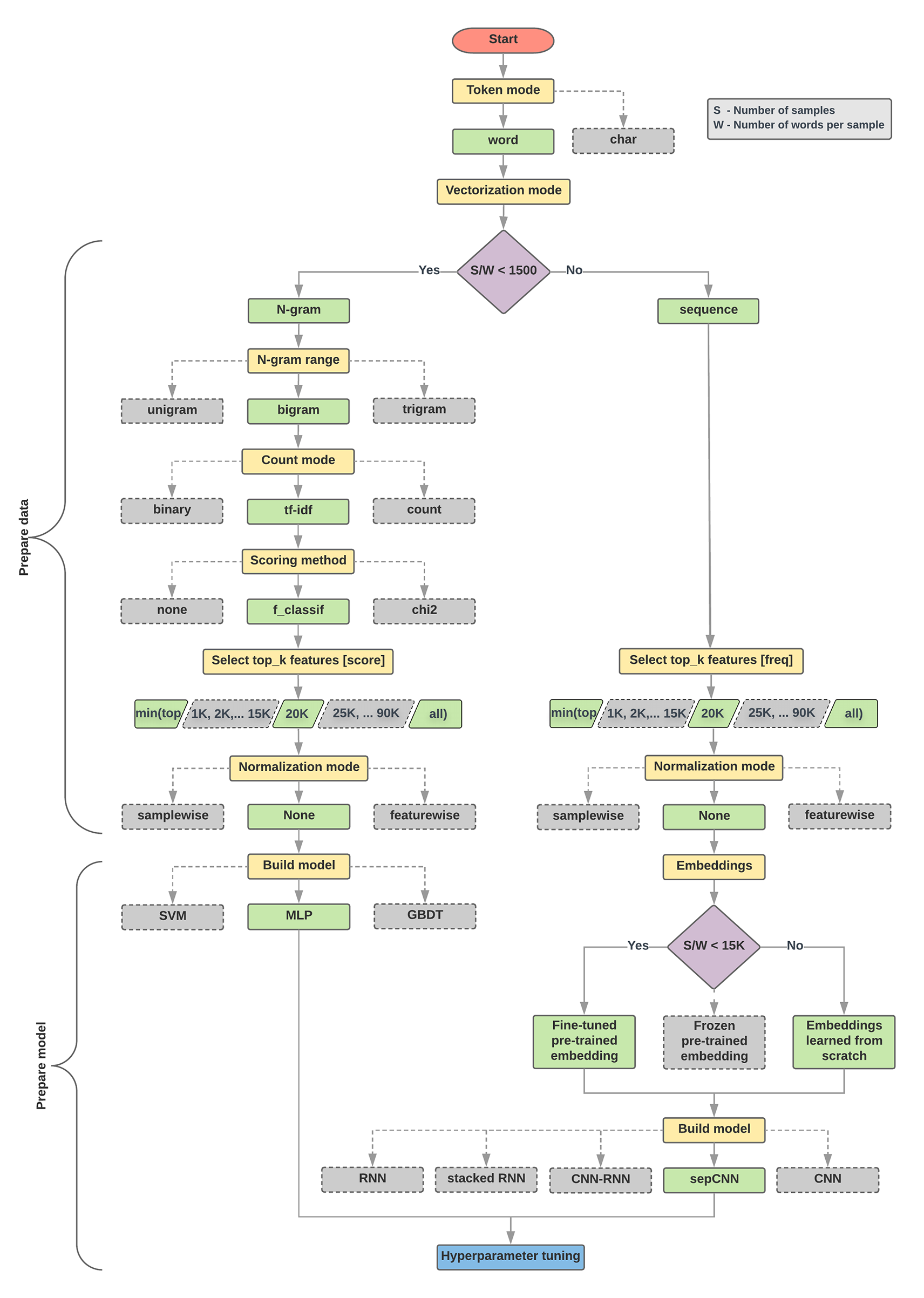
Abbildung 5: Flussdiagramm zur Textklassifizierung
Dieses Flussdiagramm beantwortet zwei zentrale Fragen:
- Welchen Lernalgorithmus oder welches Modell sollten Sie verwenden?
- Wie sollten Sie die Daten vorbereiten, um effizient die Beziehung zwischen Text und Label zu erlernen?
Die Antwort auf die zweite Frage hängt von der Antwort auf die erste Frage ab. Wie die Daten vorverarbeitet werden, die in ein Modell eingespeist werden, hängt davon ab, welches Modell wir auswählen. Modelle können grob in zwei Kategorien unterteilt werden: solche, die Informationen zur Wortreihenfolge verwenden (Sequenzmodelle), und solche, die nur Text als „Taschen“ (Mengen) von Wörtern sehen (N-Gramm-Modelle). Zu den Arten von Sequenzmodellen gehören Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs) und ihre Variationen. Zu den Arten von N-Gramm-Modellen gehören:
- logistische Regression
- einfache mehrschichtige Perceptrons (MLPs oder vollständig verbundene neuronale Netzwerke)
- Verbesserte Bäume mit Farbverlauf
- Unterstützung von Vektormaschinen
In unseren Tests haben wir festgestellt, dass das Verhältnis von „Anzahl der Stichproben“ (S) zu „Anzahl der Wörter pro Stichprobe“ (W) mit der Leistung des Modells zusammenhängt.
Wenn der Wert für dieses Verhältnis klein ist (<1.500), erzielen kleine mehrschichtige Perceptrons, die N-Gramme als Eingabe aufnehmen (die wir Option A nennen), eine bessere Leistung oder mindestens ebenso wie Sequenzmodelle. MLPs sind einfach zu definieren und zu verstehen und benötigen viel weniger Rechenzeit als Sequenzmodelle. Wenn der Wert für dieses Verhältnis groß ist (≥ 1.500), verwenden Sie ein Sequenzmodell (Option B). In den folgenden Schritten können Sie zu den relevanten Unterabschnitten (mit A oder B) für den Modelltyp springen, den Sie basierend auf dem Verhältnis von Stichproben/Wörter pro Stichprobe ausgewählt haben.
Bei unserem IMDb-Rezensions-Dataset liegt das Verhältnis der Stichproben/Wörter pro Stichprobe bei ca. 144. Wir erstellen also ein MLP-Modell.