यहीं तक हमने अपना डेटासेट तैयार किया है और हमें अपने डेटा की मुख्य विशेषताओं के बारे में अहम जानकारी मिली है. इसके बाद, दूसरे चरण में इकट्ठा की गई मेट्रिक के आधार पर, हमें सोचना चाहिए कि हमें किस क्लासिफ़िकेशन मॉडल का इस्तेमाल करना चाहिए. इसका मतलब है, इस तरह के सवाल पूछना:
- ऐसे एल्गोरिदम में टेक्स्ट डेटा कैसे दिखाया जाता है जिसमें संख्या वाले इनपुट शामिल होते हैं? (इसे डेटा प्री-प्रोसेसिंग और वेक्टराइज़ेशन कहा जाता है.)
- आपको किस तरह का मॉडल इस्तेमाल करना चाहिए?
- आपको अपने मॉडल के लिए किन कॉन्फ़िगरेशन पैरामीटर का इस्तेमाल करना चाहिए?
दशकों की रिसर्च की बदौलत, हमारे पास डेटा प्री-प्रोसेसिंग और मॉडल कॉन्फ़िगरेशन के कई विकल्पों का ऐक्सेस है. हालांकि, चुनने के लिए कारगर विकल्पों की एक बड़ी रेंज उपलब्ध होने से, किसी खास समस्या की जटिलता और दायरा काफ़ी बढ़ सकता है. ऐसा हो सकता है कि सबसे अच्छे विकल्प साफ़ तौर पर न दिखें. इसलिए, एक आसान तरीका यह होगा कि हम हर संभावित विकल्प को एक साथ आज़माएं और कुछ विकल्पों को अपने हिसाब से काट दें. हालांकि, यह बहुत महंगा होगा.
इस गाइड में, हम टेक्स्ट की कैटगरी तय करने वाले मॉडल को चुनने की प्रोसेस को आसान बनाने की कोशिश करते हैं. हमारा लक्ष्य ऐसे एल्गोरिदम का पता लगाना है जो ट्रेनिंग के लिए ज़रूरी कंप्यूटेशन टाइम को कम करते हुए, ज़्यादा से ज़्यादा सटीक हो. हमने 12 डेटासेट का इस्तेमाल करके, अलग-अलग तरह की समस्याओं (खास तौर पर, भावनाओं से जुड़े विश्लेषण और विषय की कैटगरी तय करने से जुड़ी समस्याओं) पर बहुत सारे (~4.50 लाख) एक्सपेरिमेंट किए. इसके लिए, हमने अलग-अलग डेटा प्री-प्रोसेसिंग तकनीकों और अलग-अलग मॉडल आर्किटेक्चर के बीच, हर डेटासेट के लिए बारी-बारी से एक्सपेरिमेंट किए. इससे हमें ऐसे डेटासेट पैरामीटर का पता लगाने में मदद मिली जो सबसे सही विकल्पों पर असर डालते हैं.
नीचे दिए गए मॉडल चुनने के एल्गोरिदम और फ़्लोचार्ट में, हमारे प्रयोग की खास जानकारी दी गई है. अगर उनमें इस्तेमाल किए गए सभी शब्द आपको अब तक समझ नहीं आए हैं, तो चिंता न करें. इस गाइड के नीचे दिए गए सेक्शन में इनके बारे में विस्तार से बताया गया है.
डेटा तैयार करने और मॉडल बनाने के लिए एल्गोरिदम
- प्रति सैंपल अनुपात में सैंपल/शब्दों की संख्या की गणना करें.
- अगर यह रेशियो 1,500 से कम है, तो टेक्स्ट को n-ग्राम के तौर पर टोकन करें. इसके बाद, उनकी कैटगरी तय करने के लिए, आसान मल्टी-लेयर पर्सेप्ट्रॉन (एमएलपी) मॉडल का इस्तेमाल करें (नीचे दिए गए फ़्लोचार्ट में बाईं ब्रांच):
- सैंपल को वर्ड n-ग्राम में बांटें; एन-ग्राम को वेक्टर में बदलें.
- वेक्टर की अहमियत को स्कोर करें और फिर स्कोर का इस्तेमाल करके टॉप 20 हज़ार चुनें.
- एक एमएलपी मॉडल बनाएं.
- अगर यह अनुपात 1500 से ज़्यादा है, तो टेक्स्ट को क्रम के तौर पर टोकन करें. इसके बाद, उनकी कैटगरी तय करने के लिए sepCNN मॉडल का इस्तेमाल करें (नीचे दिए गए फ़्लोचार्ट में दाईं ओर मौजूद ब्रांच):
- सैंपल को शब्दों में बांटें. फ़्रीक्वेंसी के आधार पर, टॉप 20 हज़ार शब्दों को चुनें.
- सैंपल को शब्द क्रम वाले वेक्टर में बदलें.
- अगर हर सैंपल रेशियो में सैंपल की संख्या/शब्दों की संख्या 15K से कम है, तो sepCNN मॉडल की मदद से बेहतर तरीके से तैयार की गई एम्बेडिंग का इस्तेमाल करके, सबसे अच्छे नतीजे मिल सकते हैं.
- डेटासेट के लिए सबसे सही मॉडल कॉन्फ़िगरेशन ढूंढने के लिए, अलग-अलग हाइपर पैरामीटर वैल्यू की मदद से मॉडल की परफ़ॉर्मेंस मेज़र करें.
नीचे दिए गए फ़्लोचार्ट में, पीले रंग के बॉक्स डेटा और मॉडल तैयार करने की प्रक्रियाओं को दिखाते हैं. स्लेटी रंग के बॉक्स और हरे बॉक्स से पता चलता है कि हर प्रोसेस के लिए हमने किन विकल्पों पर विचार किया. हरे रंग के बॉक्स, हर प्रोसेस के लिए हमारे सुझाए गए विकल्प को दिखाते हैं.
अपना पहला प्रयोग बनाने के लिए, इस फ़्लोचार्ट का इस्तेमाल एक शुरुआती पॉइंट के तौर पर किया जा सकता है. इससे आपको कम कंप्यूटेशन (हिसाब लगाना) लागत में ज़्यादा सटीक जानकारी मिलेगी. इसके बाद, आने वाले समय में अपने शुरुआती मॉडल को बेहतर बनाना जारी रखा जा सकता है.
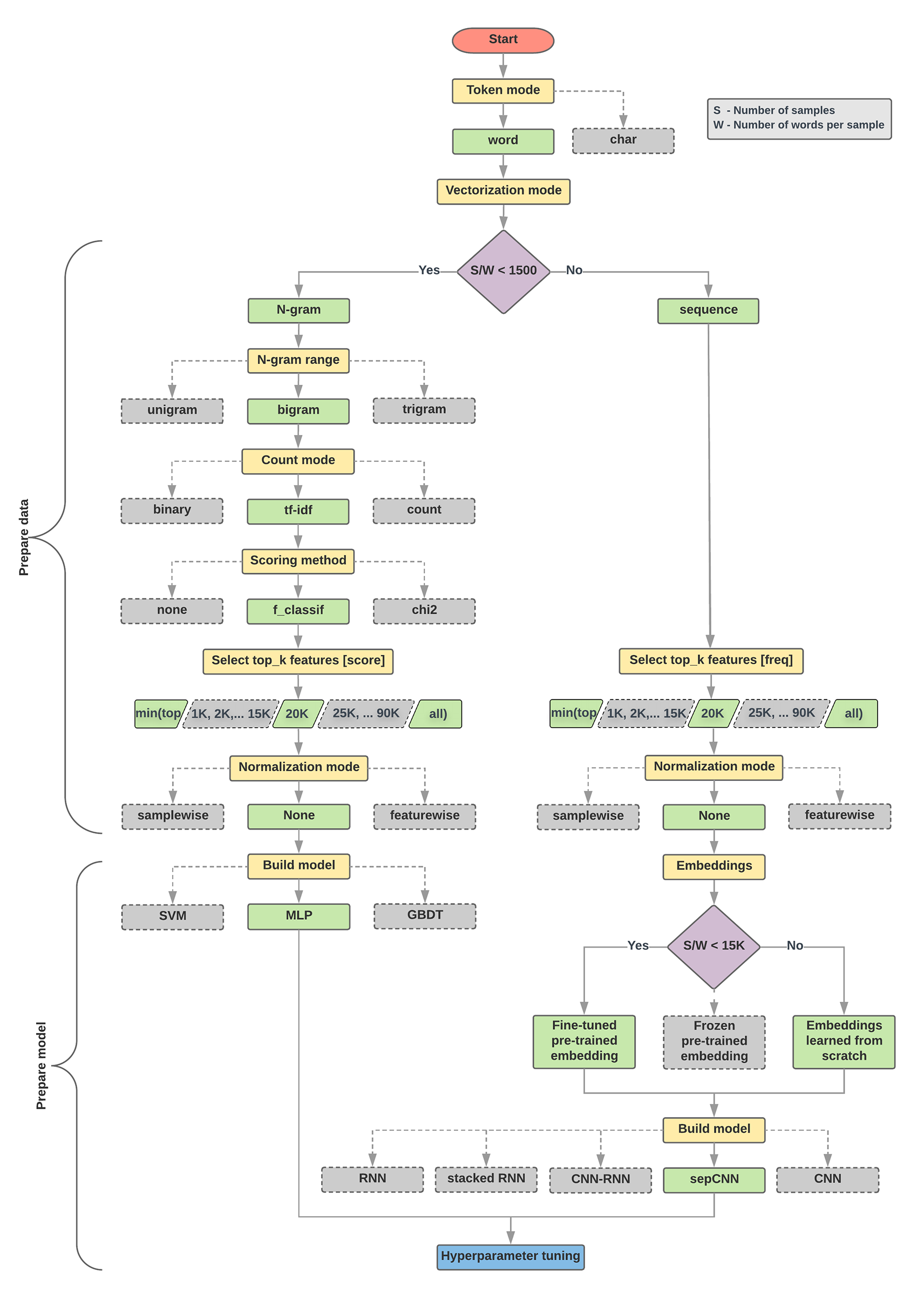
पांचवी इमेज: टेक्स्ट की कैटगरी तय करने वाला फ़्लोचार्ट
इस फ़्लोचार्ट में दो अहम सवालों के जवाब मिलते हैं:
- आपको किस लर्निंग एल्गोरिदम या मॉडल का इस्तेमाल करना चाहिए?
- टेक्स्ट और लेबल के बीच के संबंध को बेहतर ढंग से समझने के लिए, आपको डेटा को कैसे तैयार करना चाहिए?
दूसरे सवाल का जवाब, पहले सवाल के जवाब पर निर्भर करता है; हम मॉडल में फ़ीड करने के लिए, डेटा को पहले से प्रोसेस करने का तरीका इस बात पर निर्भर करते हैं कि हम कौनसा मॉडल चुनते हैं. मॉडल को दो कैटगरी में बांटा जा सकता है: वे जो शब्द के क्रम की जानकारी का इस्तेमाल करती हैं (क्रम मॉडल). दूसरी कैटगरी, जिनमें सिर्फ़ शब्दों के “बैग” (सेट) (एन-ग्राम) के तौर पर टेक्स्ट दिखता है. सीक्वेंस मॉडल के टाइप में कंवोलूशनल न्यूरल नेटवर्क (सीएनएन), बार-बार होने वाले न्यूरल नेटवर्क (आरएनएन), और उनके वैरिएशन शामिल हैं. एन-ग्राम मॉडल टाइप में ये शामिल हैं:
- लॉजिस्टिक रिग्रेशन
- कई लेयर वाले आसान पर्सेप्शन (एमएलपी या पूरी तरह से जुड़े न्यूरल नेटवर्क)
- ग्रेडिएंट बूस्टेड ट्री
- सपोर्ट वेक्टर मशीन
अपने प्रयोगों से, हमने पाया है कि “सैंपल की संख्या” (S) और “हर सैंपल के लिए शब्दों की संख्या” (W) का अनुपात, इस बात से जुड़ा है कि कौनसा मॉडल अच्छा परफ़ॉर्म करता है.
अगर इस अनुपात की वैल्यू कम (1,500) होती है, तो कई लेयर वाले छोटे पर्सेप्ट्रॉन, इनपुट के रूप में एन-ग्राम (जिसे हम विकल्प A कहते हैं) से बेहतर या कम से कम क्रम वाले मॉडल की परफ़ॉर्मेंस लेते हैं. MLP को परिभाषित करना और समझना आसान होता है. साथ ही, सीक्वेंस मॉडल की तुलना में इनमें कम समय लगता है. इस अनुपात की वैल्यू ज़्यादा (>= 1,500) होने पर, क्रम के मॉडल (विकल्प B) का इस्तेमाल करें. आगे दिए गए चरणों में, आप सीधे सैंपल/शब्द-प्रति-सैंपल अनुपात के आधार पर चुने गए मॉडल टाइप के लिए काम के सब-सेक्शन (जिन्हें A या B लेबल किया गया है) पर जा सकते हैं.
हमारे आईएमडीबी रिव्यू डेटासेट के मामले में, सैंपल/शब्द-प्रति-सैंपल का अनुपात ~144 है. इसका मतलब है कि हम एक एमएलपी मॉडल बनाएंगे.