Na tym etapie zebraliśmy nasz zbiór danych i uzyskaliśmy wgląd w najważniejsze cechy naszych danych. Następnie na podstawie wskaźników zebranych w kroku 2 trzeba zastanowić się, którego modelu klasyfikacji powinniśmy użyć. Oznacza to zadawanie pytań, takich jak:
- Jak prezentujesz dane tekstowe algorytmowi, który oczekuje danych liczbowych? Jest to tzw. wstępne przetwarzanie danych i wektoryzacja.
- Jakiego typu modelu użyjesz?
- Jakich parametrów konfiguracji musisz użyć w modelu?
Dzięki dekadom badań mamy dostęp do szerokiej gamy opcji wstępnego przetwarzania danych i konfiguracji modeli. Jednak dostęp do szerokiej gamy opcji może znacznie zwiększyć złożoność i zakres konkretnego problemu. Biorąc pod uwagę, że najlepsze rozwiązania mogą nie być oczywiste, naiwnym rozwiązaniem jest dokładne wypróbowanie wszystkich możliwych opcji i wyeliminowanie niektórych z nich dzięki intuicji. Byłoby to jednak bardzo kosztowne.
W tym przewodniku próbujemy znacznie uprościć proces wyboru modelu klasyfikacji tekstu. W przypadku danego zbioru danych naszym celem jest znalezienie algorytmu, który osiąga prawie maksymalną dokładność, a jednocześnie minimalizuje czas potrzebny na obliczenia do trenowania. Przeprowadziliśmy dużą liczbę (ok. 450 tys.) eksperymentów dotyczących różnych problemów (w szczególności analizy nastawienia i problemów z klasyfikacją tematów), wykorzystując 12 zbiorów danych na zmianę dla każdego zbioru danych, wykorzystując różne techniki wstępnego przetwarzania danych i różne architektury modeli. Pomogło nam to zidentyfikować parametry zbioru danych, które wpływają na wybór optymalny.
Algorytm wyboru modelu i schemat blokowy poniżej to podsumowanie naszych eksperymentów. Nie przejmuj się, jeśli nie rozumiesz jeszcze wszystkich użytych w nich terminów – w kolejnych sekcjach tego przewodnika znajdziesz ich więcej.
Algorytm przygotowywania danych i tworzenia modeli
- Oblicz liczbę próbek/liczbę słów na współczynnik próbki.
- Jeśli współczynnik wynosi mniej niż 1500, tokenizuj tekst jako n-gramów i sklasyfikuj go za pomocą prostego wielowarstwowego modelu perceptrona (MLP) (lewa gałąź na poniższym schemacie blokowym):
- Podziel próbki na słowa n-gramów i przekonwertuj n-gramów na wektory.
- Określ znaczenie wektorów, a następnie na podstawie wyników wybierz 20 tysięcy o największym znaczeniu.
- Utworzenie modelu MLP.
- Jeśli współczynnik jest większy niż 1500, tokenizuj tekst jako sekwencje i sklasyfikuj je za pomocą modelu sepCNN (prawa gałąź na poniższym schemacie blokowym):
- Podziel próbki na słowa i wybierz 20 tys. najlepszych słów na podstawie częstotliwości występowania.
- Przekształć próbki w wektory sekwencji słów.
- Jeśli pierwotna liczba próbek/liczba słów na próbkę wynosi mniej niż 15 tys., najlepsze będzie prawdopodobnie użycie dostrojonego, wytrenowanego wektora dystrybucyjnego z modelem sepCNN.
- Mierz wydajność modelu przy użyciu różnych wartości hiperparametrów, aby znaleźć najlepszą konfigurację modelu dla zbioru danych.
Na poniższym schemacie blokowym żółte pola wskazują procesy przygotowywania danych i modeli. Szare pola i zielone pola oznaczają opcje, które uwzględniliśmy w każdym procesie. Zielone pola oznaczają zalecany przez nas wybór dla każdego procesu.
Ten schemat blokowy może służyć jako punkt wyjścia przy tworzeniu pierwszego eksperymentu, ponieważ zapewnia dużą dokładność przy niskich kosztach obliczeń. Potem możesz kontynuować ulepszanie początkowego modelu w kolejnych iteracjach.
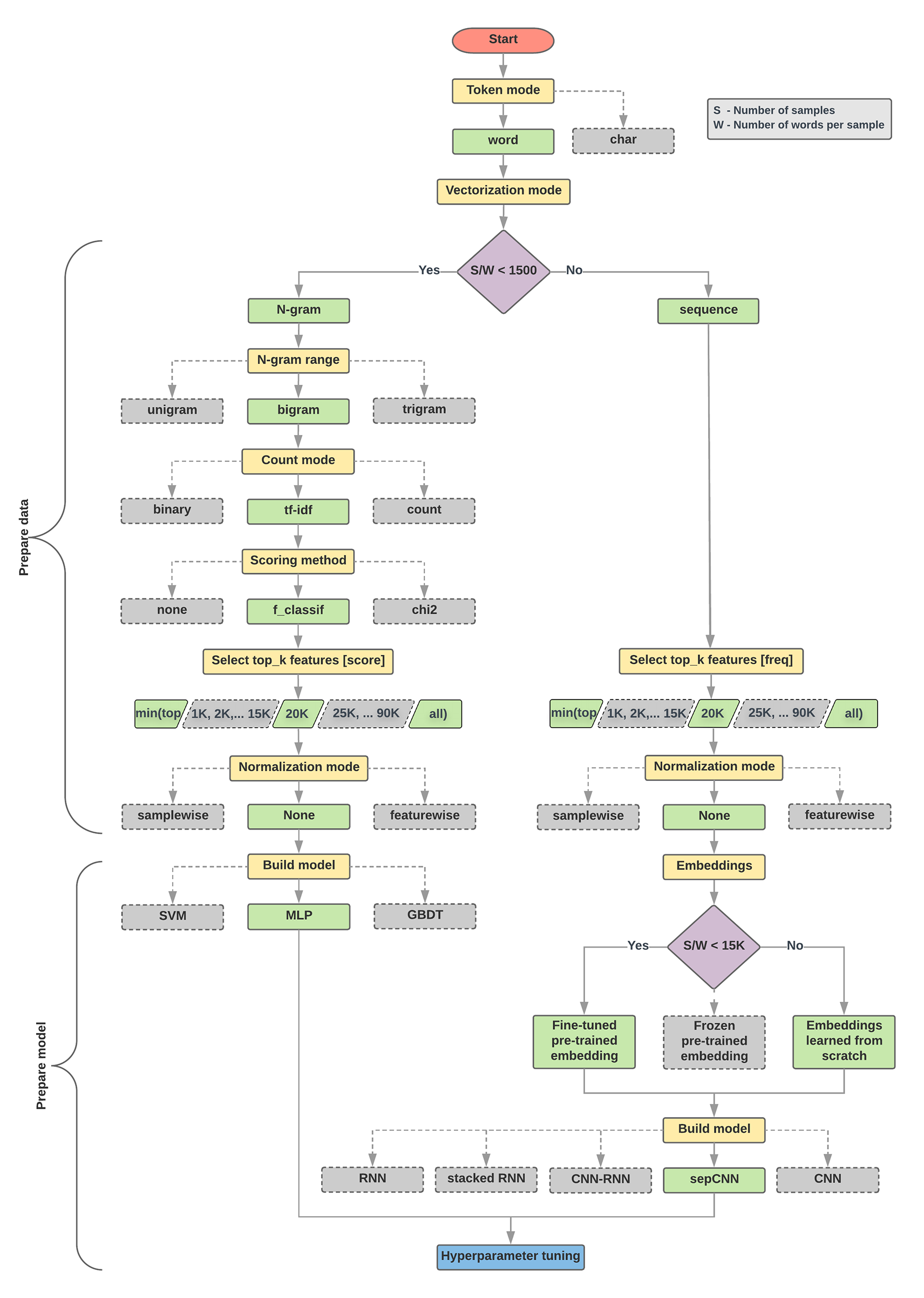
Rys. 5. Schemat blokowy klasyfikacji tekstu
Ten schemat blokowy odpowiada na 2 kluczowe pytania:
- Który algorytm lub model uczenia się wykorzystasz?
- Jak przygotować dane, aby skutecznie poznawać zależności między tekstem a etykietą?
Odpowiedź na drugie pytanie zależy od odpowiedzi na pierwsze. Sposób, w jaki wstępnie przetwarzamy dane, które zostaną wprowadzone do modelu, zależy od wybranego modelu. Modele można ogólnie podzielić na 2 kategorie: te, które korzystają z informacji o kolejności słów (modele sekwencyjne), i te, które postrzegają tekst jako „torebki” (zbiory słów) (modele n-gram). Typy modeli sekwencji obejmują splotowe sieci neuronowe (CNN), powtarzające się sieci neuronowe (RNN) i ich odmiany. Typy modeli n-gram:
- regresja logistyczna
- proste wielowarstwowe perceptrony (MLP, czyli w pełni połączone sieci neuronowe)
- drzewa z motywem gradientu
- obsługuj maszyny wektorowe
Z naszych eksperymentów zaobserwowaliśmy, że stosunek „liczby próbek” (S) do „liczby słów na próbkę” (W) ma związek z tym, który model dobrze sobie radzi.
Gdy wartość tego współczynnika jest mała (< 1500), małe wielowarstwowe perceptrony, które przyjmują n-gramów jako dane wejściowe (którą nazywamy opcją A), działają lepiej lub są co najmniej tak skuteczne jak modele sekwencyjne. Modele MLP są proste do zdefiniowania i zrozumienia, a obliczenia wymagają znacznie mniej czasu niż modele sekwencyjne. Gdy wartość tego współczynnika jest duża (>= 1500), użyj modelu sekwencyjnego (Opcja B). W kolejnych krokach możesz przejść do odpowiednich podsekcji (oznaczonych jako A lub B) dla wybranego typu modelu na podstawie stosunku próbek do liczby słów na próbkę.
W przypadku naszego zbioru danych z recenzji IMDb stosunek próbek do słów na próbkę wynosi około 144. Oznacza to, że utworzymy model MLP.