Pada titik ini, kita telah mengumpulkan set data dan mendapatkan insight tentang karakteristik utama dari data. Selanjutnya, berdasarkan metrik yang dikumpulkan di Langkah 2, kita harus memikirkan model klasifikasi mana yang harus digunakan. Hal ini berarti mengajukan pertanyaan seperti:
- Bagaimana Anda menyajikan data teks ke algoritma yang mengharapkan masukan numerik? (Hal ini disebut prapemrosesan dan vektorisasi data.)
- Jenis model apa yang sebaiknya Anda gunakan?
- Parameter konfigurasi apa yang harus digunakan untuk model Anda?
Berkat riset selama puluhan tahun, kami memiliki akses ke berbagai macam opsi pra-pemrosesan data dan konfigurasi model. Namun, ketersediaan array yang sangat besar dari opsi yang dapat dipilih dapat meningkatkan kerumitan dan cakupan masalah tertentu secara signifikan. Mengingat bahwa opsi terbaik mungkin tidak jelas, solusi yang naif adalah mencoba setiap kemungkinan opsi secara menyeluruh, memangkas beberapa pilihan melalui intuisi. Namun, itu akan sangat mahal.
Dalam panduan ini, kami berupaya menyederhanakan proses pemilihan model klasifikasi teks secara signifikan. Untuk set data tertentu, tujuan kita adalah menemukan algoritma yang mencapai akurasi mendekati maksimum sekaligus meminimalkan waktu komputasi yang diperlukan untuk pelatihan. Kami menjalankan sejumlah besar (~450 ribu) eksperimen untuk berbagai jenis masalah (terutama analisis sentimen dan masalah klasifikasi topik), menggunakan 12 set data, bergantian untuk setiap set data antara teknik pra-pemrosesan data yang berbeda dan arsitektur model yang berbeda. Hal ini membantu kami mengidentifikasi parameter set data yang memengaruhi pilihan optimal.
Algoritma pemilihan model dan diagram alir di bawah ini adalah ringkasan eksperimentasi kami. Jangan khawatir jika Anda belum memahami semua istilah yang digunakan di dalamnya; bagian berikut dalam panduan ini akan menjelaskannya secara mendalam.
Algoritma untuk Persiapan Data dan Pembuatan Model
- Hitung jumlah sampel/jumlah kata per rasio sampel.
- Jika rasio ini kurang dari 1.500, buat token teks sebagai n-gram dan gunakan model perceptron (MLP) multi-lapisan sederhana untuk mengklasifikasikannya (cabang kiri dalam diagram alir di bawah):
- Pisahkan sampel menjadi kata n-gram; konversikan n-gram menjadi vektor.
- Nilai pentingnya vektor dan kemudian pilih 20K teratas menggunakan skor tersebut.
- Membangun model MLP.
- Jika rasionya lebih besar dari 1500, buat token teks sebagai urutan dan gunakan model sepCNN untuk mengklasifikasikannya (cabang kanan pada diagram alir di bawah):
- Bagi contoh menjadi beberapa kata, pilih 20 ribu kata teratas berdasarkan frekuensinya.
- Konversi sampel menjadi vektor urutan kata.
- Jika jumlah asli sampel/jumlah kata per rasio sampel kurang dari 15 ribu, penggunaan penyematan terlatih yang telah disesuaikan dengan model sepCNN kemungkinan akan memberikan hasil terbaik.
- Ukur performa model dengan nilai hyperparameter yang berbeda untuk menemukan konfigurasi model terbaik untuk set data.
Pada diagram alir di bawah, kotak kuning menunjukkan data dan proses persiapan model. Kotak abu-abu dan kotak hijau menunjukkan pilihan yang kami pertimbangkan untuk setiap proses. Kotak hijau menunjukkan pilihan yang kami rekomendasikan untuk setiap proses.
Anda dapat menggunakan diagram alir ini sebagai titik awal untuk membuat eksperimen pertama karena alat ini akan memberi Anda akurasi yang baik dengan biaya komputasi yang rendah. Anda kemudian dapat terus meningkatkan kualitas model awal pada iterasi berikutnya.
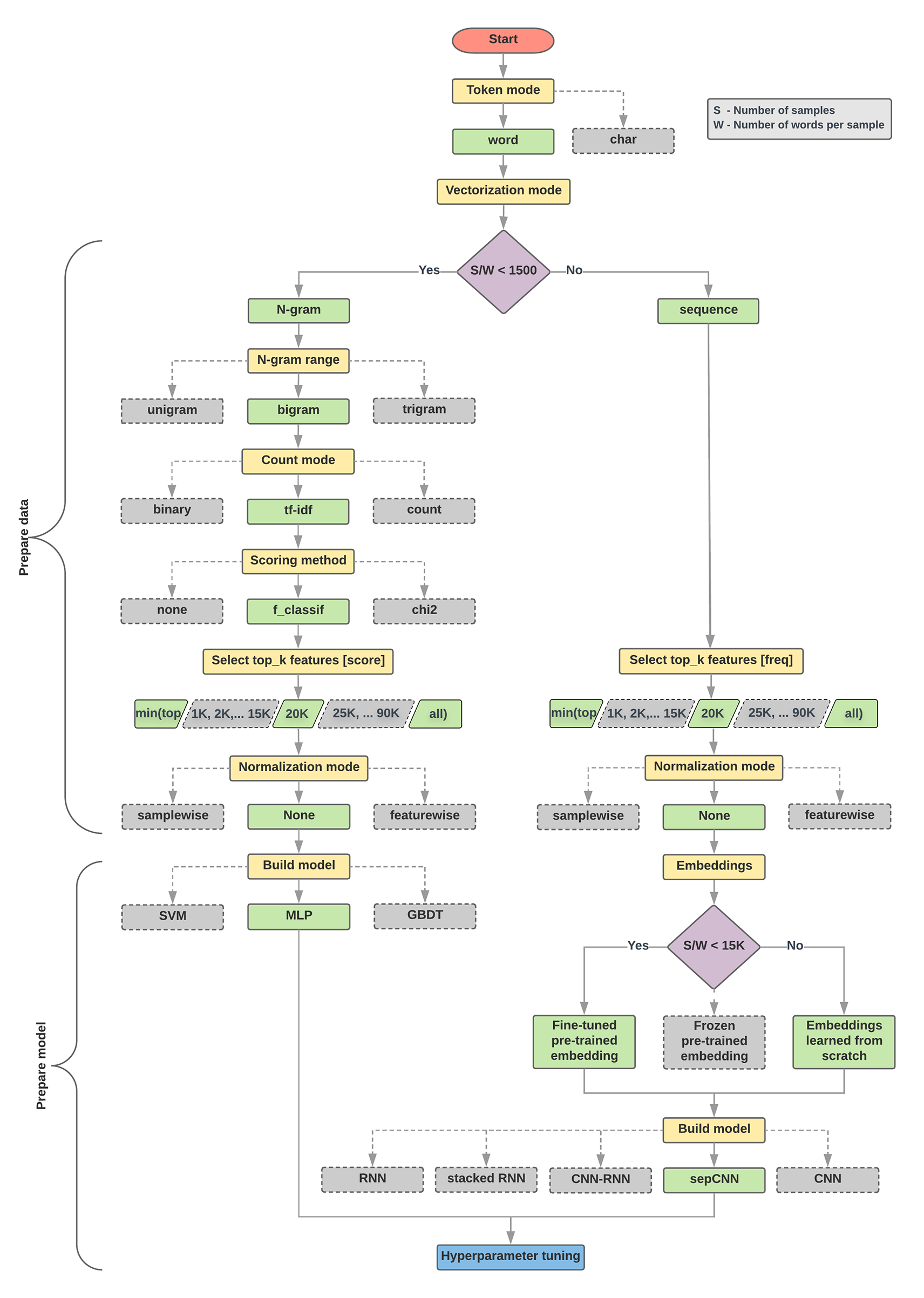
Gambar 5: Diagram alir klasifikasi teks
Diagram alir ini menjawab dua pertanyaan penting:
- Algoritma atau model pembelajaran mana yang harus Anda gunakan?
- Bagaimana Anda menyiapkan data untuk secara efisien mempelajari hubungan antara teks dan label?
Jawaban pertanyaan kedua bergantung pada jawaban pertanyaan pertama; cara kita melakukan prapemrosesan data untuk dimasukkan ke dalam model akan bergantung pada model yang kita pilih. Model dapat diklasifikasikan secara luas menjadi dua kategori: model yang menggunakan informasi pengurutan kata (model urutan), dan model yang hanya melihat teks sebagai “tas” (set) kata (model n-gram). Jenis model urutan meliputi jaringan neural konvolusional (CNN), jaringan saraf berulang (RNN), dan variasinya. Jenis model n-gram meliputi:
- regresi logistik
- perceptron multi-lapisan sederhana (MLP, atau jaringan neural yang terhubung sepenuhnya)
- pohon yang ditingkatkan gradien
- mendukung mesin vektor
Dari eksperimen, kami mengamati bahwa rasio “jumlah sampel” (S) terhadap “jumlah kata per sampel” (W) berkorelasi dengan model mana yang berperforma baik.
Jika nilai untuk rasio ini kecil (<1500), perseptron multi-lapisan kecil yang menggunakan n-gram sebagai input (yang disebut Opsi A) akan berperforma lebih baik atau tidak, sebaik model urutan. MLP mudah ditentukan dan dipahami, serta memerlukan waktu komputasi jauh lebih singkat daripada model urutan. Jika nilai untuk rasio ini besar (>= 1500), gunakan model urutan (Opsi B). Pada langkah-langkah berikutnya, Anda dapat langsung menuju ke subbagian yang relevan (berlabel A atau B) untuk jenis model yang dipilih berdasarkan rasio sampel/kata-per-sampel.
Dalam kasus set data ulasan IMDb, rasio sampel/kata-per-sampel adalah ~144. Artinya, kita akan membuat model MLP.