A questo punto, abbiamo assemblato il set di dati e acquisito insight sulle caratteristiche chiave dei nostri dati. Successivamente, in base alle metriche raccolte nel Passaggio 2, dovremmo pensare al modello di classificazione da utilizzare. Ciò significa porre domande quali:
- Come presentate i dati di testo a un algoritmo che prevede un input numerico? (Questo processo è chiamato pre-elaborazione e vettorizzazione dei dati.)
- Che tipo di modello dovresti usare?
- Quali parametri di configurazione dovresti utilizzare per il tuo modello?
Grazie a decenni di ricerca, abbiamo accesso a una vasta gamma di opzioni di pre-elaborazione dei dati e configurazione di modelli. Tuttavia, la disponibilità di una gamma molto ampia di opzioni tra cui scegliere può aumentare notevolmente la complessità e la portata di un determinato problema. Dato che le opzioni migliori potrebbero non essere ovvie, una soluzione ingenua sarebbe provare ogni possibile opzione in modo esaustivo, eliminando alcune scelte tramite l'intuizione. Tuttavia, l'operazione sarebbe estremamente costosa.
In questa guida, cerchiamo di semplificare notevolmente il processo di selezione di un modello di classificazione del testo. Per un determinato set di dati, il nostro obiettivo è trovare l'algoritmo che raggiunge la massima accuratezza, riducendo al minimo il tempo di calcolo richiesto per l'addestramento. Abbiamo eseguito un numero elevato (circa 450.000) di esperimenti su problemi di diversi tipi (in particolare problemi di analisi del sentiment e classificazione degli argomenti), utilizzando 12 set di dati, alternando per ogni set di dati tra diverse tecniche di pre-elaborazione dei dati e diverse architetture dei modelli. Questo ci ha aiutato a identificare i parametri del set di dati che influenzano le scelte ottimali.
L'algoritmo di selezione dei modelli e il diagramma di flusso riportati di seguito sono un riepilogo della nostra sperimentazione. Non preoccuparti se non comprendi ancora tutti i termini utilizzati; le sezioni seguenti di questa guida li spiegheranno in modo approfondito.
Algoritmo per la preparazione dei dati e la creazione di modelli
- Calcola il numero di campioni/il numero di parole per rapporto di campionamento.
- Se questo rapporto è inferiore a 1500, tokenizza il testo come
n-grammi e utilizza un
semplice modello perceptrone a più strati (MLP) per classificarli (ramo sinistro nel
diagramma di flusso in basso):
- Suddividi i campioni in n-grammi di parole e converti gli n-grammi in vettori.
- Assegna un punteggio all'importanza dei vettori e seleziona i primi 20.000 utilizzando i punteggi.
- Creare un modello MLP.
- Se il rapporto è maggiore di 1500, tokenizza il testo come sequenze e utilizza un modello sepCNN per classificarli (ramo destro nel diagramma di flusso in basso):
- Suddividi i campioni in parole; seleziona le 20.000 parole principali in base alla loro frequenza.
- Converti i campioni in vettori di sequenza di parole.
- Se il numero originale di campioni/numero di parole per rapporto di campionamento è inferiore a 15.000, l'utilizzo di un incorporamento preaddestrato ottimizzato con il modello sepCNN probabilmente fornirà i risultati migliori.
- Misurare le prestazioni del modello con diversi valori degli iperparametri per trovare la migliore configurazione del modello per il set di dati.
Nel diagramma di flusso seguente, le caselle gialle indicano i processi di preparazione dei dati e del modello. Le caselle grigie e verdi indicano le scelte che abbiamo preso in considerazione per ogni processo. Le caselle verdi indicano la scelta consigliata per ciascun processo.
Puoi utilizzare questo diagramma di flusso come punto di partenza per costruire il tuo primo esperimento, poiché ti offrirà una buona precisione a bassi costi di calcolo. Puoi quindi continuare a migliorare il modello iniziale nelle iterazioni successive.
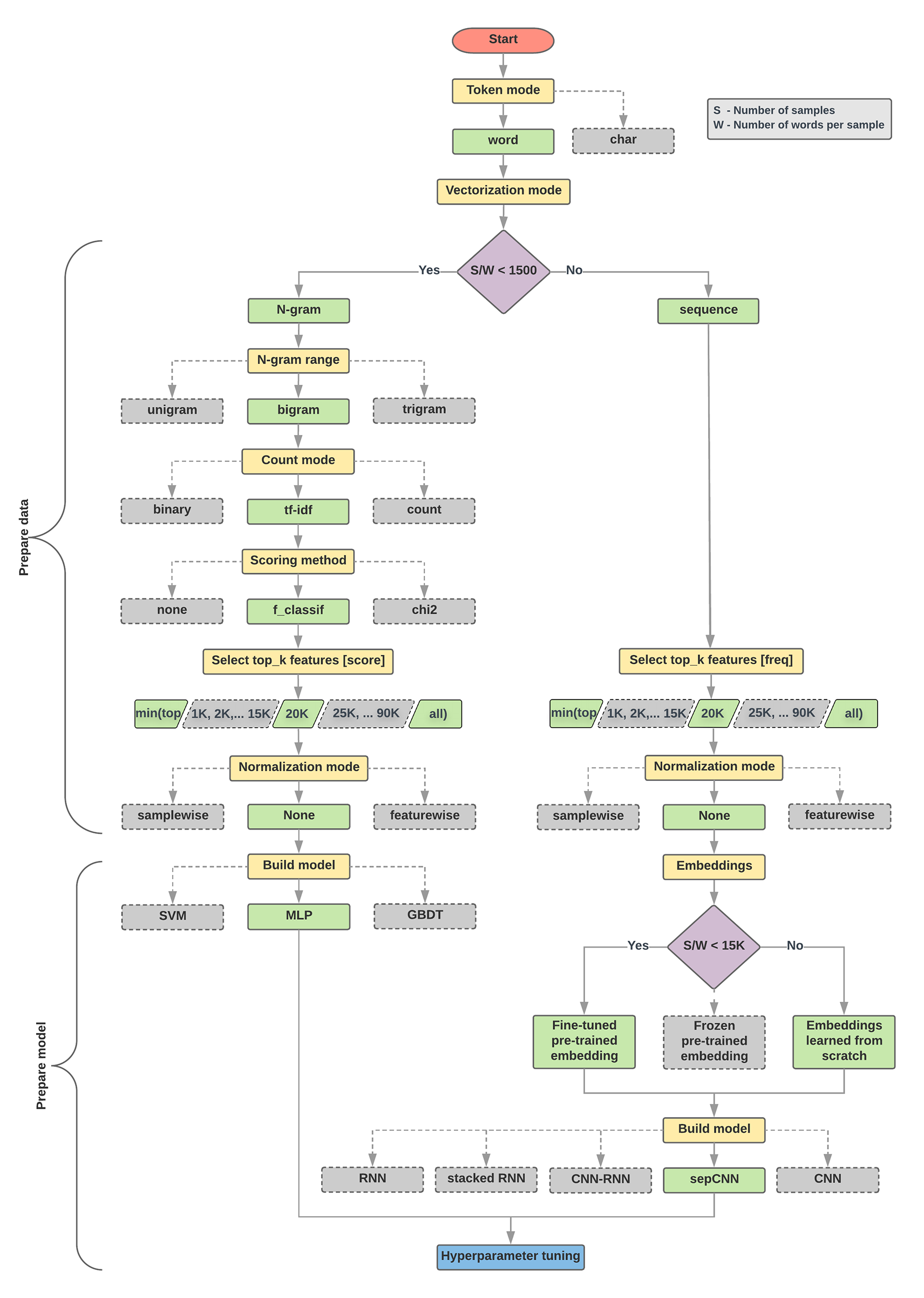
Figura 5: diagramma di flusso per la classificazione del testo
Questo diagramma di flusso risponde a due domande chiave:
- Quale algoritmo o modello di apprendimento dovresti utilizzare?
- Come dovresti preparare i dati per apprendere in modo efficiente la relazione tra testo ed etichetta?
La risposta alla seconda domanda dipende dalla risposta alla prima domanda; il modo in cui pre-elaborare i dati da inserire in un modello dipenderà dal modello scelto. I modelli possono essere classificati in due categorie generali: quelli che utilizzano informazioni sull'ordinamento delle parole (modelli di sequenza) e quelli che invece vedono il testo semplicemente come "bags" (insiemi) di parole (modelli n-grammi). I tipi di modelli di sequenza includono le reti CNN (Convolutional Neural Network, rete neurale convoluzionale), RNN (Recurrent Neural Network) e le relative varianti. I tipi di modelli n-grammi includono:
- regressione logistica
- perceptroni a più livelli semplici (MLP, reti neurali completamente connesse)
- alberi con gradiente
- supportano le macchine vettoriali
Dai nostri esperimenti, abbiamo osservato che il rapporto tra "numero di campioni" (S) e "numero di parole per campione" (W) è in correlazione con il modello che ha un buon rendimento.
Quando il valore di questo rapporto è piccolo (<1500), i piccoli percetroni multi-strato che prendono n-grammi come input (che chiameremo Opzione A) hanno un rendimento migliore o almeno così come i modelli in sequenza. Gli MLP sono semplici da definire e da comprendere e richiedono molto meno tempo di calcolo rispetto ai modelli sequenza. Quando il valore di questa relazione è elevato (>= 1500), utilizza un modello di sequenza (Opzione B). Nei passaggi che seguono, puoi passare alle sottosezioni pertinenti (con etichetta A o B) per il tipo di modello scelto in base al rapporto campioni/parole per campione.
Nel caso del nostro set di dati di revisione IMDb, il rapporto campioni/parole per campione è ~144. Ciò significa che creeremo un modello MLP.