На этом этапе мы собрали наш набор данных и получили представление о ключевых характеристиках наших данных. Далее, на основе показателей, которые мы собрали на шаге 2 , нам следует подумать о том, какую модель классификации нам следует использовать. Это значит задавать такие вопросы, как:
- Как представить текстовые данные алгоритму, который ожидает числового ввода? (Это называется предварительной обработкой данных и векторизацией.)
- Какой тип модели следует использовать?
- Какие параметры конфигурации следует использовать для вашей модели?
Благодаря десятилетиям исследований у нас есть доступ к большому набору вариантов предварительной обработки данных и конфигурации моделей. Однако наличие очень большого количества жизнеспособных вариантов выбора может значительно увеличить сложность и масштаб конкретной проблемы. Учитывая, что лучшие варианты могут быть неочевидны, наивным решением было бы исчерпательно испробовать все возможные варианты, отсекая некоторые варианты с помощью интуиции. Однако это будет чрезвычайно дорого.
В этом руководстве мы пытаемся значительно упростить процесс выбора модели классификации текста. Для данного набора данных наша цель — найти алгоритм, который обеспечивает близкую к максимальной точности при минимизации времени вычислений, необходимого для обучения. Мы провели большое количество (~ 450 тыс.) экспериментов по задачам разных типов (особенно проблемам анализа настроений и классификации тем), используя 12 наборов данных, чередуя для каждого набора данных различные методы предварительной обработки данных и разные архитектуры моделей. Это помогло нам определить параметры набора данных, которые влияют на оптимальный выбор.
Алгоритм выбора модели и блок-схема ниже представляют собой краткое изложение наших экспериментов. Не волнуйтесь, если вы еще не понимаете все используемые в них термины; в следующих разделах данного руководства они будут объяснены более подробно.
Алгоритм подготовки данных и построения модели
- Рассчитайте количество образцов/количество слов на соотношение образцов.
- Если это соотношение меньше 1500, токенизируйте текст как n-граммы и используйте простую модель многослойного перцептрона (MLP) для их классификации (левая ветвь на блок-схеме ниже):
- Разделить образцы на n-граммы слов; преобразовать n-граммы в векторы.
- Оцените важность векторов, а затем выберите 20 тысяч лучших, используя оценки.
- Постройте модель MLP.
- Если соотношение больше 1500, токенизируйте текст как последовательности и используйте модель sepCNN для их классификации (правая ветвь на блок-схеме ниже):
- Разделите образцы на слова; выберите 20 тысяч самых популярных слов в зависимости от их частоты.
- Преобразуйте образцы в векторы последовательности слов.
- Если исходное соотношение количество выборок/количество слов на выборку составляет менее 15 000, использование точно настроенного предварительно обученного внедрения с моделью sepCNN, вероятно, даст наилучшие результаты.
- Измерьте производительность модели с различными значениями гиперпараметров, чтобы найти лучшую конфигурацию модели для набора данных.
На приведенной ниже блок-схеме желтые прямоугольники обозначают процессы подготовки данных и модели. Серые и зеленые прямоугольники обозначают варианты, которые мы рассматривали для каждого процесса. Зеленые прямоугольники обозначают рекомендуемый нами выбор для каждого процесса.
Вы можете использовать эту блок-схему в качестве отправной точки для построения своего первого эксперимента, поскольку она обеспечит хорошую точность при низких затратах на вычисления. Затем вы можете продолжать совершенствовать свою первоначальную модель в последующих итерациях.
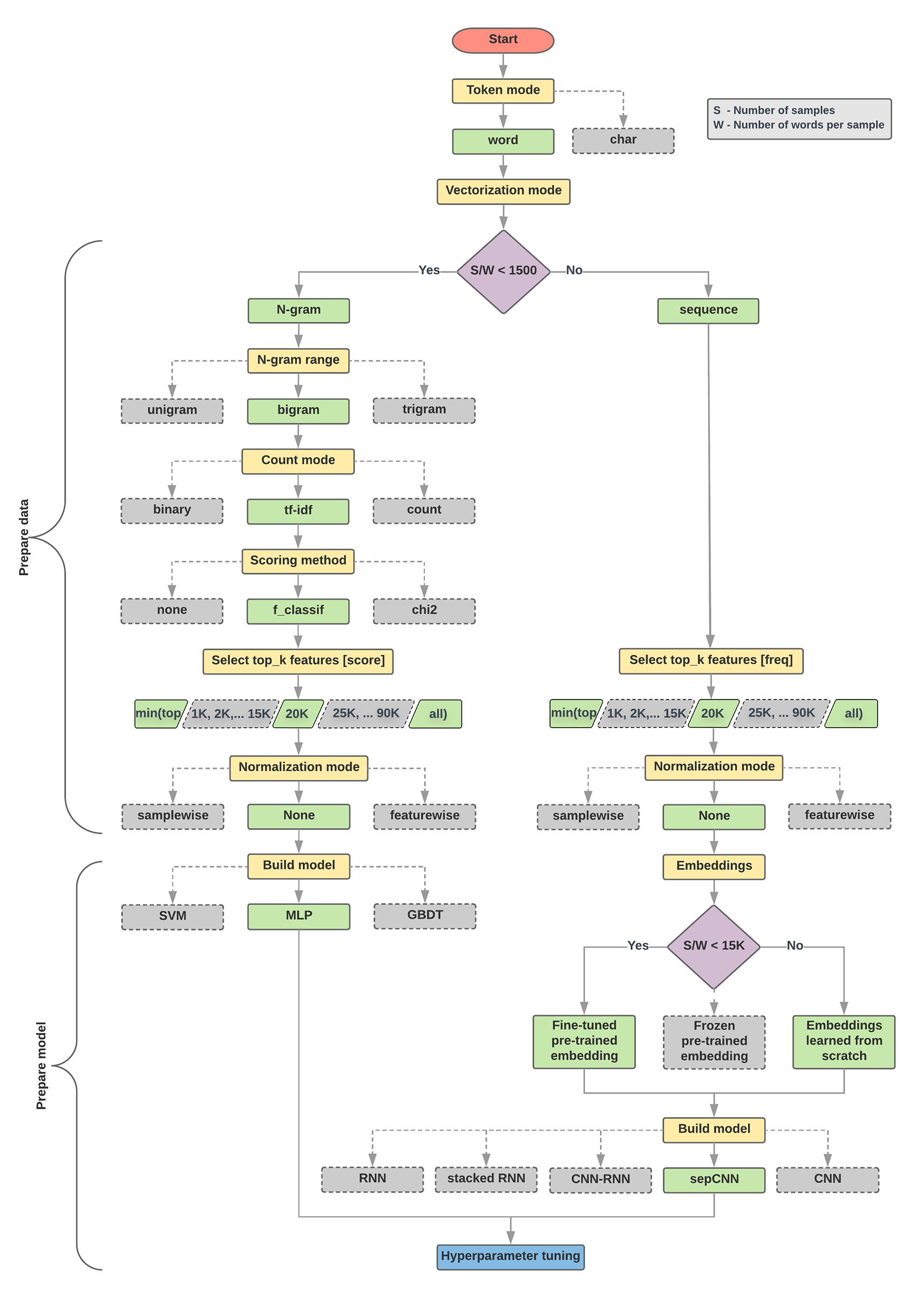
Рисунок 5. Блок-схема классификации текста.
Эта блок-схема отвечает на два ключевых вопроса:
- Какой алгоритм или модель обучения вам следует использовать?
- Как следует подготовить данные, чтобы эффективно изучить взаимосвязь между текстом и меткой?
Ответ на второй вопрос зависит от ответа на первый вопрос; способ предварительной обработки данных для загрузки в модель будет зависеть от того, какую модель мы выберем. Модели можно условно разделить на две категории: те, которые используют информацию о порядке слов (модели последовательностей), и те, которые рассматривают текст просто как «мешки» (наборы) слов (модели n-грамм). Типы моделей последовательностей включают сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN) и их варианты. Типы моделей n-грамм включают:
- логистическая регрессия
- простые многослойные перцептроны (MLP или полносвязные нейронные сети)
- Деревья с градиентным усилением
- опорные векторные машины
В результате наших экспериментов мы заметили, что соотношение «количества образцов» (S) к «количеству слов на образец» (W) коррелирует с тем, какая модель работает хорошо.
Когда значение этого отношения мало (<1500), небольшие многослойные перцептроны, которые принимают на вход n-граммы (которые мы назовем Вариантом А ), работают лучше или, по крайней мере, так же хорошо, как модели последовательностей. MLP легко определить и понять, и они требуют гораздо меньше вычислительного времени, чем модели последовательностей. Если значение этого отношения велико (>= 1500), используйте модель последовательности ( вариант B ). В последующих шагах вы можете перейти к соответствующим подразделам (помеченным A или B ) для типа модели, который вы выбрали на основе соотношения образцов/слов на образец.
В случае нашего набора данных обзора IMDb соотношение образцов/слов на образец составляет ~144. Это означает, что мы создадим модель MLP.