À ce stade, nous avons rassemblé notre ensemble de données et obtenu des insights sur les principales caractéristiques de nos données. Ensuite, sur la base des métriques que nous avons recueillies à l'étape 2, nous devons réfléchir au modèle de classification à utiliser. Cela signifie poser des questions telles que:
- Comment présenter les données textuelles à un algorithme qui attend une entrée numérique ? (C'est ce qu'on appelle le prétraitement et la vectorisation des données.)
- Quel type de modèle devez-vous utiliser ?
- Quels paramètres de configuration devez-vous utiliser pour votre modèle ?
Grâce à des décennies de recherche, nous avons accès à un large éventail d'options de prétraitement des données et de configuration de modèle. Cependant, la disponibilité d'un très grand nombre d'options viables peut augmenter considérablement la complexité et la portée d'un problème particulier. Sachant que les meilleures options ne sont peut-être pas évidentes, une solution simple consisterait à essayer chaque option possible de manière exhaustive, en éliminant quelques choix par l'intuition. Cependant, cela coûterait extrêmement cher.
Dans ce guide, nous essayons de simplifier considérablement le processus de sélection d'un modèle de classification de texte. Pour un ensemble de données donné, notre objectif est de trouver l'algorithme qui offre une précision proche du maximum tout en réduisant au maximum le temps de calcul nécessaire à l'entraînement. Nous avons effectué un grand nombre (environ 450 000) d'expériences sur des problèmes de différents types (en particulier les problèmes d'analyse des sentiments et de classification des sujets) à l'aide de 12 ensembles de données, en alternant différentes techniques de prétraitement des données et différentes architectures de modèle. Cela nous a aidés à identifier les paramètres de l'ensemble de données qui influencent les choix optimaux.
L'algorithme de sélection du modèle et l'organigramme ci-dessous constituent un résumé de nos tests. Ne vous inquiétez pas si vous ne comprenez pas encore tous les termes qui y sont utilisés. Les sections suivantes de ce guide les expliquent en détail.
Algorithme de préparation des données et création de modèle
- Calculer le nombre d'échantillons/nombre de mots par ratio d'échantillon
- Si ce ratio est inférieur à 1 500, tokenisez le texte en n-grammes et utilisez un modèle MLP simple de perceptron à plusieurs couches pour les classer (branche gauche dans l'organigramme ci-dessous) :
- Diviser les échantillons en n-grammes et convertir les n-grammes en vecteurs
- Évaluez l'importance des vecteurs, puis sélectionnez les 20 000 premiers en utilisant les scores.
- Créer un modèle MLP
- Si le ratio est supérieur à 1 500, segmentez le texte sous forme de séquences et utilisez un modèle sepCNN pour les classer (branche droite dans l'organigramme ci-dessous) :
- Divisez les échantillons en mots et sélectionnez les 20 000 mots les plus utilisés en fonction de leur fréquence.
- Convertir les échantillons en vecteurs de séquence de mots
- Si le nombre d'échantillons/nombre de mots par rapport d'échantillon est inférieur à 15 000, l'utilisation d'une représentation vectorielle continue pré-entraînée affinée avec le modèle sepCNN fournira probablement les meilleurs résultats.
- mesurer les performances du modèle avec différentes valeurs d'hyperparamètres afin de trouver la meilleure configuration de modèle pour l'ensemble de données ;
Dans l'organigramme ci-dessous, les cases jaunes représentent les processus de préparation des données et du modèle. Les cases grises et vertes indiquent les choix que nous avons envisagés pour chaque processus. Les cases vertes indiquent notre choix recommandé pour chaque processus.
Vous pouvez utiliser cet organigramme comme point de départ pour élaborer votre premier test, car il offre une bonne précision pour de faibles coûts de calcul. Vous pouvez ensuite continuer à améliorer votre modèle initial au cours des itérations suivantes.
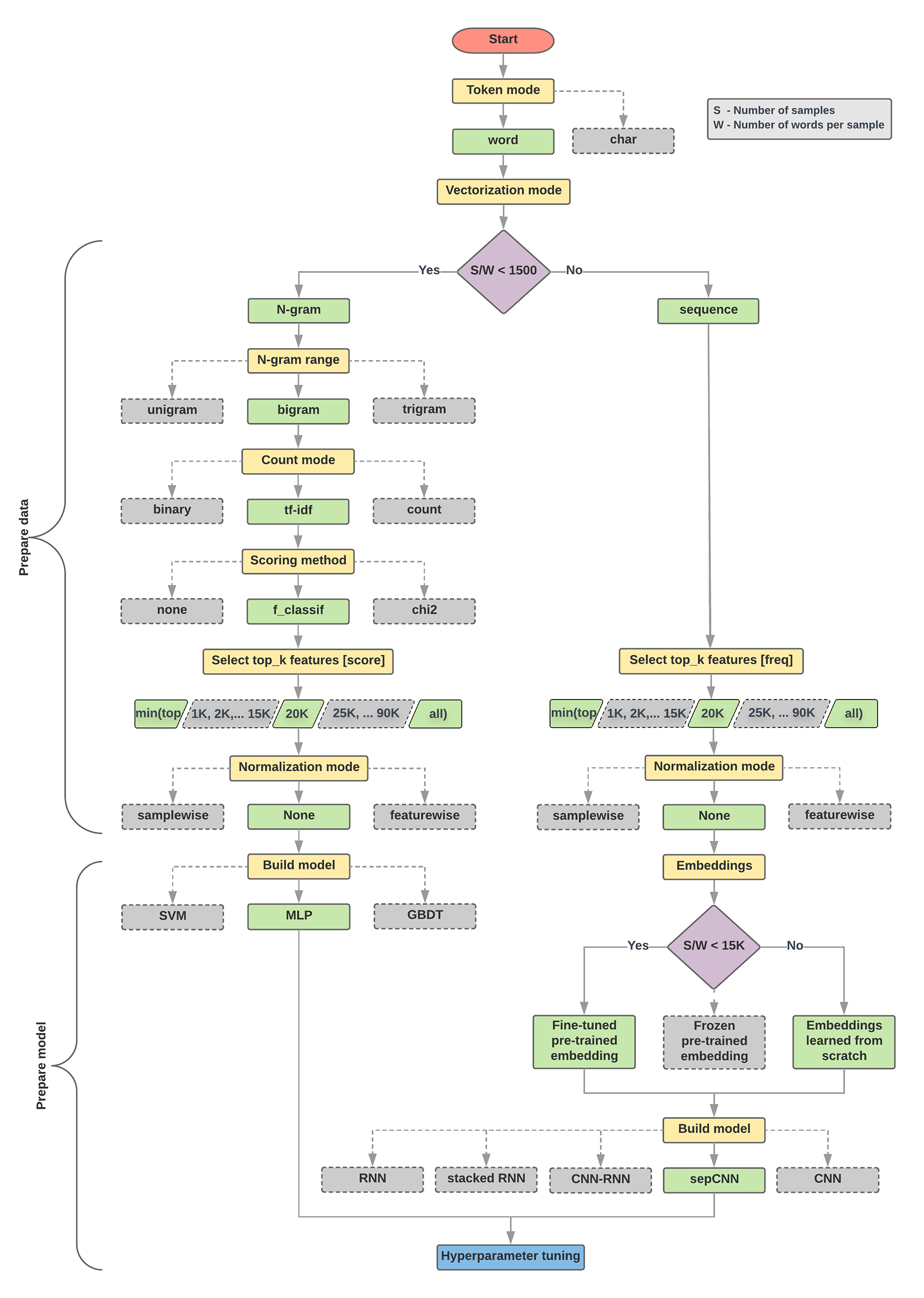
Figure 5: Organigramme de classification de texte
Cet organigramme répond à deux questions clés:
- Quel algorithme ou modèle d'apprentissage devez-vous utiliser ?
- Comment devez-vous préparer les données pour apprendre efficacement la relation entre le texte et l'étiquette ?
La réponse à la deuxième question dépend de la réponse à la première. La manière dont nous prétraitons les données à alimenter dans un modèle dépend du modèle que nous choisissons. Les modèles peuvent être généralement classés en deux catégories: ceux qui utilisent des informations d'ordre des mots (modèles de séquence) et ceux qui ne voient que le texte comme des "sacs" (ensembles) de mots (modèles de n-grammes). Les types de modèles de séquence incluent les réseaux de neurones convolutifs (CNN), les réseaux de neurones récurrents (RNN) et leurs variantes. Les types de modèles de n-grammes incluent:
- Régression logistique
- Perceptrons à plusieurs couches simples (MLP, ou réseaux de neurones entièrement connectés)
- arbres à boosting de gradient
- sont compatibles avec les machines vectorielles
D'après nos tests, le ratio entre le "nombre d'échantillons" (S) et le "nombre de mots par échantillon" (W) est en corrélation avec le modèle qui fonctionne le mieux.
Lorsque la valeur de ce ratio est faible (< 1 500), les petits perceptrons multicouches qui prennent en entrée des n-grammes (appelés Option A) sont plus performants, ou du moins aussi bien que les modèles de séquence. Les MLP sont simples à définir et à comprendre, et prennent beaucoup moins de temps de calcul que les modèles de séquence. Lorsque la valeur de ce ratio est élevée (>= 1 500), utilisez un modèle de séquence (Option B). Dans les étapes suivantes, vous pouvez passer aux sous-sections appropriées (étiquetées A ou B) pour le type de modèle que vous avez choisi en fonction du ratio échantillons/mots par échantillon.
Dans le cas de notre ensemble de données d'avis sur IMDb, le ratio échantillons/mots par échantillon est d'environ 144. Cela signifie que nous allons créer un modèle MLP.