ในตอนนี้ เราได้รวบรวมชุดข้อมูลและได้ข้อมูลเชิงลึกเกี่ยวกับคุณลักษณะที่สำคัญของข้อมูล ถัดไป เราควรคำนึงถึงโมเดลการจัดประเภทที่เราควรใช้โดยพิจารณาจากเมตริกที่รวบรวมในขั้นตอนที่ 2 ซึ่งหมายถึง การถามคำถามต่างๆ เช่น
- คุณจะนำเสนอข้อมูลที่เป็นข้อความกับอัลกอริทึมที่คาดว่าจะป้อนตัวเลขอย่างไร (ซึ่งเรียกว่าการประมวลผลข้อมูลและเวกเตอร์ข้อมูลล่วงหน้า)
- คุณควรใช้รุ่นประเภทใด
- คุณควรใช้พารามิเตอร์การกำหนดค่าใดสำหรับโมเดลของคุณ
จากการวิจัยหลายสิบปี ทำให้เราสามารถเข้าถึงตัวเลือกการประมวลผลข้อมูลล่วงหน้าและการกำหนดค่าโมเดลได้มากมาย อย่างไรก็ตาม การที่ตัวเลือกที่มีจำนวนมากให้เลือกนั้นสามารถเพิ่มความซับซ้อนและขอบเขตของปัญหาหนึ่งๆ ได้เป็นอย่างมาก เนื่องจากตัวเลือกที่ดีที่สุดอาจไม่ชัดเจนนัก การแก้ปัญหาแบบซื่อสัตย์จึงเป็นการพยายามทำทุกตัวเลือกให้รอบคอบ โดยตัดบางตัวเลือกผ่านสัญชาตญาณ แต่ก็จะมีค่าใช้จ่ายมหาศาล
ในคู่มือนี้ เราพยายามลดความซับซ้อนของขั้นตอนการเลือกโมเดลการจัดประเภทข้อความ สำหรับชุดข้อมูลหนึ่งๆ เป้าหมายของเราคือการค้นหาอัลกอริทึมที่ได้เกือบแม่นยำที่สุด ในขณะเดียวกันก็ลดเวลาที่ใช้ในการคำนวณที่ต้องใช้ในการฝึก เราทำการทดสอบจำนวนมาก (ประมาณ 450,000) กับโจทย์ประเภทต่างๆ (โดยเฉพาะปัญหาการวิเคราะห์ความเห็นและปัญหาการจัดประเภทหัวข้อ) โดยใช้ชุดข้อมูล 12 ชุด โดยสลับกันสำหรับแต่ละชุดข้อมูลระหว่างเทคนิคการประมวลผลข้อมูลแบบต่างๆ และสถาปัตยกรรมโมเดลที่แตกต่างกัน ข้อมูลนี้ช่วยให้เราระบุพารามิเตอร์ชุดข้อมูลที่ส่งผลต่อตัวเลือกที่เหมาะสมที่สุด
อัลกอริทึมการเลือกโมเดลและโฟลว์ชาร์ตด้านล่างคือสรุปการทดลองของเรา ไม่ต้องกังวลหากคุณยังไม่เข้าใจคำศัพท์ทั้งหมดที่ใช้ในคำเหล่านี้ ส่วนต่อไปนี้ในคู่มือนี้จะอธิบายคำศัพท์เหล่านั้นในเชิงลึก
อัลกอริทึมสำหรับการเตรียมข้อมูลและการสร้างโมเดล
- คำนวณจำนวนตัวอย่าง/จำนวนคำต่ออัตราส่วนตัวอย่าง
- หากอัตราส่วนนี้น้อยกว่า 1500 ให้แปลงข้อความเป็นโทเค็นในรูปแบบ n-กรัม และใช้โมเดล Perceptron (MLP) หลายเลเยอร์แบบง่ายเพื่อจำแนกข้อความ (สาขาซ้ายในโฟลว์ชาร์ตด้านล่าง)
- แยกตัวอย่างเป็น n-กรัม แปลง n-กรัมเป็นเวกเตอร์
- ให้คะแนนความสำคัญของเวกเตอร์ แล้วเลือก 20,000 รายการแรกโดยใช้คะแนน
- สร้างโมเดล MLP
- หากอัตราส่วนสูงกว่า 1500 ให้แปลงข้อความเป็นโทเค็นเป็นลำดับ และใช้โมเดล sepCNN เพื่อแยกประเภท (สาขาที่ถูกต้องในโฟลว์ชาร์ตด้านล่าง)
- แยกตัวอย่างเป็นคำ เลือกคำ 20,000 คำแรกตามความถี่ของคำ
- แปลงตัวอย่างเป็นเวกเตอร์ลำดับคำ
- หากจำนวนตัวอย่าง/จำนวนคำดั้งเดิมต่ออัตราส่วนตัวอย่างน้อยกว่า 15, 000 คำ การใช้การฝังก่อนการฝึกที่ปรับแต่งมาอย่างดีด้วยโมเดล sepCNN จะช่วยให้ได้ผลลัพธ์ที่ดีที่สุด
- วัดประสิทธิภาพโมเดลด้วยค่าไฮเปอร์พารามิเตอร์ต่างๆ เพื่อค้นหาการกำหนดค่าโมเดลที่ดีที่สุดสำหรับชุดข้อมูล
ในโฟลว์ชาร์ตด้านล่าง ช่องสีเหลืองจะระบุกระบวนการเตรียมข้อมูลและโมเดล ช่องสีเทาและช่องสีเขียวคือตัวเลือกที่เราพิจารณาสำหรับแต่ละกระบวนการ ช่องสีเขียวคือตัวเลือกที่เราแนะนำสำหรับแต่ละกระบวนการ
คุณใช้โฟลว์ชาร์ตนี้เป็นจุดเริ่มต้นในการสร้างการทดสอบแรกของคุณได้ เนื่องจากจะให้ความแม่นยำที่ดีสำหรับต้นทุนการคำนวณต่ำ จากนั้นคุณจะสามารถทำการปรับปรุงบนโมเดลเริ่มต้นต่อไปในการทำซ้ำหลังจากนั้นได้
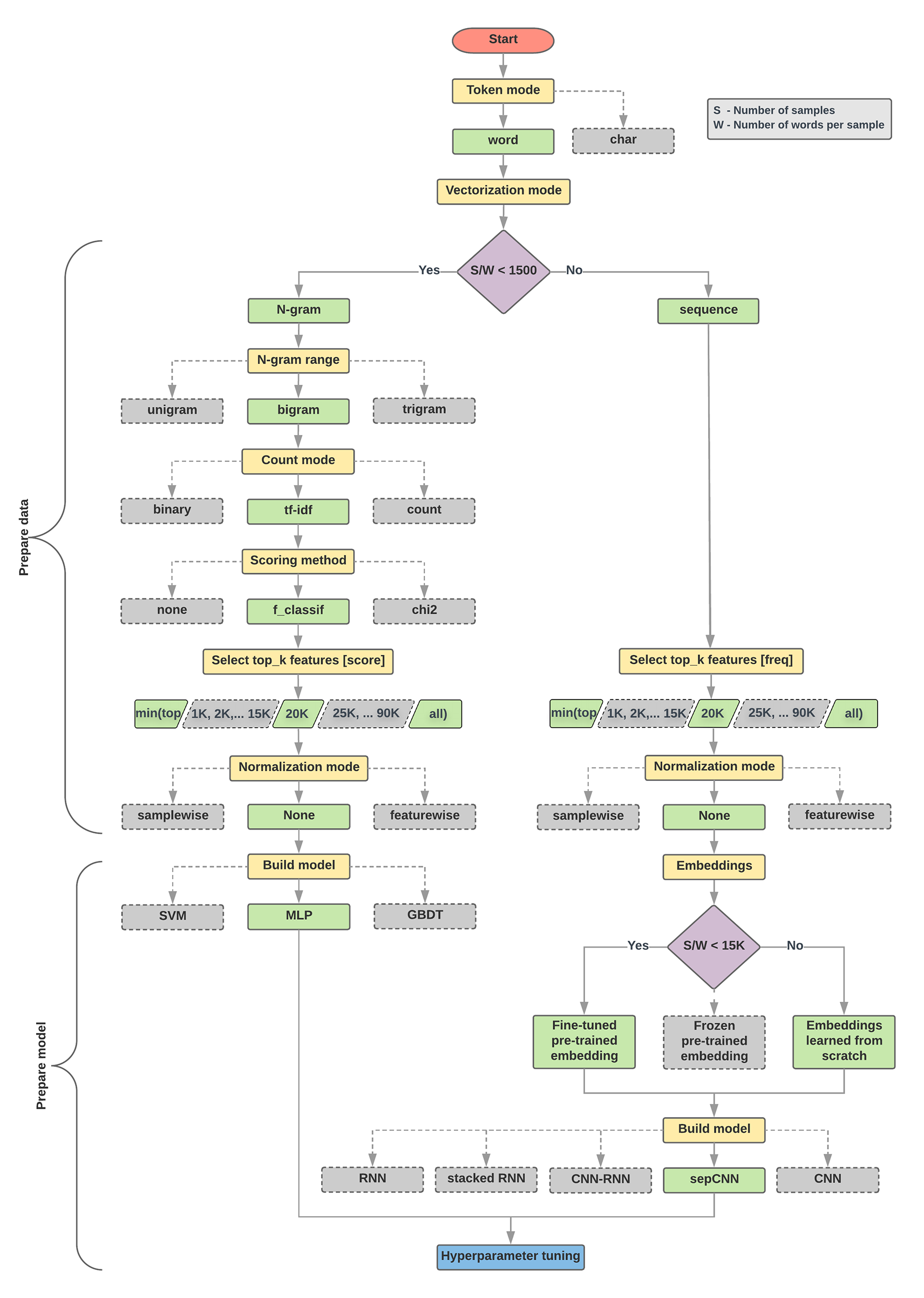
รูปที่ 5: โฟลว์ชาร์ตการแยกประเภทข้อความ
โฟลว์ชาร์ตนี้จะตอบคำถามสำคัญ 2 ข้อต่อไปนี้
- คุณควรใช้โมเดลหรืออัลกอริทึมการเรียนรู้ในข้อใด
- คุณควรเตรียมข้อมูลอย่างไรเพื่อให้เรียนรู้ความสัมพันธ์ระหว่างข้อความและป้ายกำกับได้อย่างมีประสิทธิภาพ
คำตอบของคำถามที่ 2 ขึ้นอยู่กับคำตอบของคำถามแรก วิธีที่เราประมวลผลข้อมูลล่วงหน้าเพื่อใส่ลงในโมเดลจะขึ้นอยู่กับโมเดลที่เราเลือก โมเดลสามารถแบ่งออกเป็น 2 หมวดหมู่กว้างๆ คือโมเดลที่ใช้ข้อมูลการเรียงลำดับคำ (รูปแบบลำดับ) และโมเดลที่เห็นแค่ข้อความเป็น "ถุง" (ชุด) ของคำ (โมเดล n-gram) ประเภทของโมเดลลำดับ ได้แก่ โครงข่ายระบบประสาทเทียมแบบคอนโวลูชัน (CNN) โครงข่ายประสาทแบบเกิดซ้ำ (RNN) และรูปแบบต่างๆ ประเภทของโมเดล n-gram มีดังนี้:
- การถดถอยแบบโลจิสติกส์
- เพอร์เซปรอนหลายชั้นแบบง่าย (MLP หรือโครงข่ายระบบประสาทเทียมที่เชื่อมต่อโดยสมบูรณ์)
- ต้นไม้ที่ไล่ระดับสี
- รองรับเครื่องเวกเตอร์
จากการทดสอบ เราพบว่าอัตราส่วนของ "จำนวนตัวอย่าง" (S) ต่อ "จำนวนคำต่อตัวอย่าง" (W) สัมพันธ์กับโมเดลที่มีประสิทธิภาพดี
เมื่อค่าสำหรับอัตราส่วนนี้มีค่าต่ำ (<1500) หน่วย Perceptron แบบหลายเลเยอร์ขนาดเล็กที่รับหน่วย n กรัมเป็นอินพุต (ซึ่งเราเรียกว่าตัวเลือก A) จะทำงานได้ดีกว่าหรืออย่างน้อย และมีรูปแบบตามลำดับ MLP กำหนดค่าและทำความเข้าใจได้ง่าย รวมถึงใช้เวลาประมวลผลน้อยกว่าโมเดลลำดับมาก เมื่อค่าสำหรับอัตราส่วนนี้ใหญ่ (>= 1500) ให้ใช้โมเดลลำดับ (ตัวเลือก B) ในขั้นตอนต่อๆ มา คุณสามารถข้ามไปยังส่วนย่อยที่เกี่ยวข้อง (ติดป้ายกำกับเป็น A หรือ B) สำหรับประเภทโมเดลที่เลือกโดยอิงตามอัตราส่วนตัวอย่าง/คำต่อตัวอย่าง
ในกรณีของชุดข้อมูลการตรวจสอบ IMDb อัตราส่วนตัวอย่าง/คำต่อตัวอย่างจะอยู่ที่ประมาณ 144 ซึ่งหมายความว่าเราจะสร้างโมเดล MLP