Bu noktada, veri kümemizi derledik ve verilerimizin temel özellikleri hakkında bilgi sahibi olduk. Ardından, 2. Adım'da topladığımız metriklere dayanarak hangi sınıflandırma modelini kullanmamız gerektiğini düşünmeliyiz. Bu, şöyle sorular sormanız anlamına gelir:
- Sayısal giriş bekleyen bir algoritmaya metin verilerini nasıl sunarsınız? (Buna veri ön işleme ve vektörleştirme adı verilir.)
- Ne tür bir model kullanmanız gerekir?
- Modeliniz için hangi yapılandırma parametrelerini kullanmalısınız?
Onlarca yıllık araştırmalar sayesinde çok çeşitli veri ön işleme ve model yapılandırma seçeneklerine erişebiliyoruz. Ancak çok sayıda uygun seçeneğin mevcut olması, belirli bir sorunun karmaşıklığını ve kapsamını büyük ölçüde artırabilir. En iyi seçeneklerin açıkça görülemeyebileceği düşünüldüğünde, olası her seçeneği etraflıca deneyerek sezgilerden bazılarını ayıklamak gibi naif bir çözüm olabilir. Ancak bu çok pahalı olurdu.
Bu kılavuzda, metin sınıflandırma modeli seçme işlemini önemli ölçüde basitleştirmeye çalışacağız. Belirli bir veri kümesi için hedefimiz, eğitim için gereken hesaplama süresini en aza indirirken maksimum doğruluğa yakın bir sonuç veren algoritmayı bulmaktır. Farklı türlerdeki sorunlarda (özellikle yaklaşım analizi ve konu sınıflandırma problemleri) çok sayıda (yaklaşık 450 bin) deneme gerçekleştirdik. 12 veri kümesi kullanarak farklı veri ön işleme teknikleri ve farklı model mimarileri arasında sırayla her veri kümesi için çalıştık. Bu, optimum seçimleri etkileyen veri kümesi parametrelerini belirlememize yardımcı oldu.
Aşağıdaki model seçme algoritması ve akış şeması, denemelerimizin bir özetidir. Bu terimlerde kullanılan tüm terimleri henüz anlamadıysanız endişelenmeyin; bu kılavuzun aşağıdaki bölümlerinde bu terimler ayrıntılı olarak açıklanmaktadır.
Veri Hazırlama ve Model Oluşturma Algoritması
- Örnek sayısı/örnek oranı başına kelime sayısını hesaplama.
- Bu oran 1.500'den azsa metni n-gram olarak jetona dönüştürün ve sınıflandırmak için basit bir çok katmanlı algılayıcı (MLP) modeli kullanın (aşağıdaki akış şemasında sol dal):
- Örnekleri n-gram sözcüklerine ayırma; n-gramları vektörlere dönüştürme.
- Vektörlerin önem derecesini değerlendirin ve ardından puanları kullanarak ilk 20.000’i seçin.
- MLP modeli oluşturma
- Oran 1.500'den büyükse metni sıralı olarak jetona dönüştürün ve sınıflandırmak için sepCNN modeli kullanın (aşağıdaki akış şemasında sağ dal):
- Örnekleri kelimelere bölüp sıklıklarına göre en iyi performans gösteren 20 bin kelimeyi seçin.
- Örnekleri kelime dizisi vektörlerine dönüştürün.
- Orijinal örnek sayısı/örnek başına kelime sayısı oranı 15.000'den azsa sepCNN modeliyle ayrıntılı olarak ayarlanmış bir önceden eğitilmiş yerleştirme kullanmak muhtemelen en iyi sonuçları sağlayacaktır.
- Veri kümesi için en iyi model yapılandırmasını bulmak amacıyla model performansını farklı hiperparametre değerleriyle ölçün.
Aşağıdaki akış şemasında yer alan sarı kutular veri ve model hazırlama işlemlerini gösterir. Gri kutular ve yeşil kutular, her işlem için dikkate aldığımız seçenekleri gösterir. Yeşil kutular, her işlem için önerdiğimiz seçeneği gösterir.
Bu akış şemasını, düşük hesaplama maliyetlerinde yüksek bir doğruluk sağlayacağından ilk denemenizi oluşturmak için başlangıç noktası olarak kullanabilirsiniz. Böylece ilk modelinizi sonraki iterasyonlarla geliştirmeye devam edebilirsiniz.
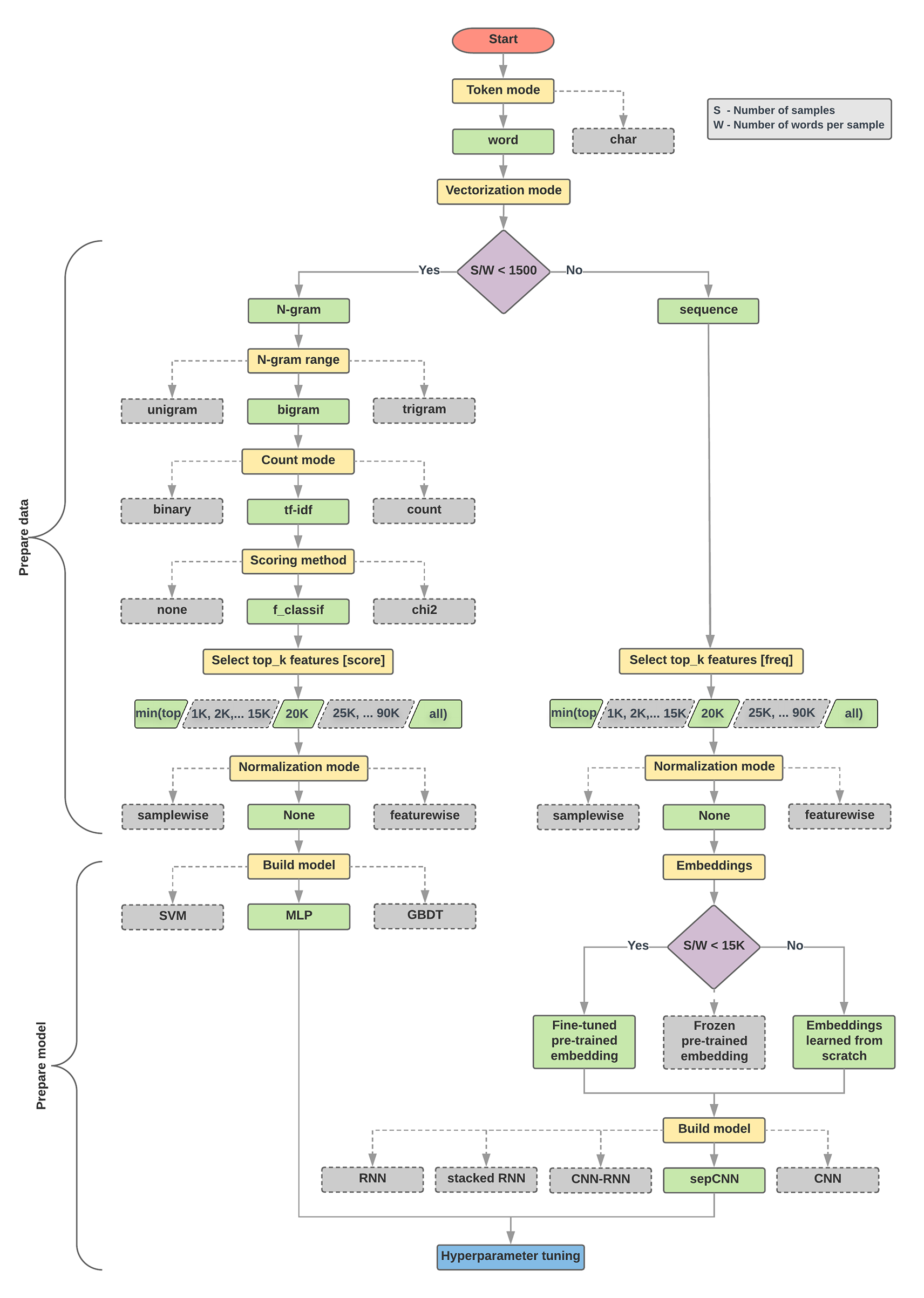
Şekil 5: Metin sınıflandırma akış şeması
Bu akış şeması iki temel soruyu yanıtlar:
- Hangi öğrenme algoritmasını veya modelini kullanmalısınız?
- Metin ve etiket arasındaki ilişkiyi verimli bir şekilde öğrenmek için verileri nasıl hazırlamalısınız?
İkinci sorunun cevabı, ilk sorunun cevabına bağlıdır. Bir modele aktarılacak verileri ön işleme şeklimiz, hangi modeli seçtiğimize bağlı olacaktır. Modeller genel olarak iki kategoriye ayrılabilir: Kelime sıralama bilgilerini kullananlar (sıra modelleri) ve metni yalnızca kelime "çantaları" (n-gram modelleri) olarak gören modeller. Dizi modeli türleri arasında evrişimsel nöral ağlar (CNN'ler), yinelenen nöral ağlar (RNN'ler) ve bunların varyasyonları yer alır. n-gram modeli türleri şunlardır:
- mantıksal regresyon
- basit çok katmanlı algılar (MLP'ler veya tamamen bağlı nöral ağlar)
- gradyan renklendirilmiş ağaçlar
- destek vektör makineleri
Denemelerimizde, "örnek sayısı"nın (S) "örnek başına kelime sayısı"na (W) oranının, hangi modelin iyi performans gösterdiğiyle ilişkili olduğunu gözlemledik.
Bu oranın değeri küçük olduğunda (<1.500) giriş olarak n-gramı alan (Option A adını veririz) çok katmanlı küçük algılayıcılar daha iyi veya en az dizi modeli kadar iyi performans gösterir. MLP'lerin tanımlanması ve anlaşılması kolaydır ve dizi modellerine kıyasla çok daha az işlem süresi alırlar. Bu oranın değeri büyük olduğunda (>= 1.500) bir dizi modeli kullanın (Seçenek B). Sonraki adımlarda, örnek/örnek başına kelime sayısına göre seçtiğiniz model türü için ilgili alt bölümlere (A veya B etiketli) geçebilirsiniz.
IMDb inceleme veri kümemizde, örnek/örnek başına kelime sayısı oranı yaklaşık 144'tür. Bu, bir MLP modeli oluşturacağımız anlamına geliyor.