Até aqui, reunimos nosso conjunto de dados e conseguimos insights sobre as principais características dos nossos dados. Em seguida, com base nas métricas coletadas na Etapa 2, devemos pensar sobre qual modelo de classificação usar. Isso significa fazer perguntas como:
- Como você apresenta os dados de texto para um algoritmo que espera entrada numérica? Isso é chamado de pré-processamento e vetorização de dados.
- Que tipo de modelo você deve usar?
- Quais parâmetros de configuração você deve usar no modelo?
Graças a décadas de pesquisa, temos acesso a uma grande variedade de opções de pré-processamento de dados e configuração de modelos. No entanto, a disponibilidade de uma grande variedade de opções viáveis pode aumentar muito a complexidade e o escopo de um problema específico. Como as melhores opções podem não ser óbvias, uma solução ingênua seria tentar exaustivamente todas as opções possíveis, removendo algumas escolhas por intuição. No entanto, isso seria extremamente caro.
Neste guia, tentamos simplificar significativamente o processo de seleção de um modelo de classificação de texto. Para um determinado conjunto de dados, nosso objetivo é encontrar o algoritmo que alcance uma precisão próxima à máxima, minimizando o tempo de computação necessário para o treinamento. Executamos um grande número (cerca de 450 mil) de experimentos em problemas de diferentes tipos (especialmente análise de sentimento e problemas de classificação de tópicos), usando 12 conjuntos de dados, alternando para cada conjunto de dados diferentes técnicas de pré-processamento de dados e arquiteturas de modelo distintas. Isso nos ajudou a identificar parâmetros do conjunto de dados que influenciam as escolhas ideais.
O algoritmo de seleção de modelos e o fluxograma abaixo são um resumo da nossa experimentação. Não se preocupe se ainda não entender todos os termos usados neles. As seções a seguir deste guia explicam tudo em detalhes.
Algoritmo para preparação de dados e criação de modelos
- Calcular o número de amostras/número de palavras por proporção de amostra.
- Se essa proporção for menor que 1.500, tokenize o texto como
n-grams e use um
modelo simples de perceptron (MLP) de várias camadas para classificá-lo (ramificação esquerda no
fluxograma abaixo):
- Divida as amostras em n-gramas de palavras e converta os n-gramas em vetores.
- Pontuar a importância dos vetores e selecionar os 20 mil principais usando as pontuações.
- Criar um modelo de MLP.
- Se a proporção for maior que 1.500, tokenize o texto como sequências e use um modelo sepCNN para classificá-lo (ramificação direita no fluxograma abaixo):
- Divida as amostras em palavras e selecione as 20 mil palavras principais com base na frequência delas.
- Converta as amostras em vetores de sequência de palavras.
- Se o número original de amostras/número de palavras por proporção de amostra for menor que 15 mil, o uso de uma incorporação pré-treinada bem ajustada com o modelo sepCNN provavelmente fornecerá os melhores resultados.
- Meça o desempenho do modelo com diferentes valores de hiperparâmetros para encontrar a melhor configuração de modelo para o conjunto de dados.
No fluxograma abaixo, as caixas amarelas indicam os processos de preparação de dados e modelos. As caixas cinza e verdes indicam as escolhas que consideramos para cada processo. As caixas verdes indicam nossa escolha recomendada para cada processo.
Use esse fluxograma como ponto de partida para criar seu primeiro experimento, já que ele oferece boa precisão com baixos custos de computação. É possível continuar melhorando o modelo inicial nas iterações subsequentes.
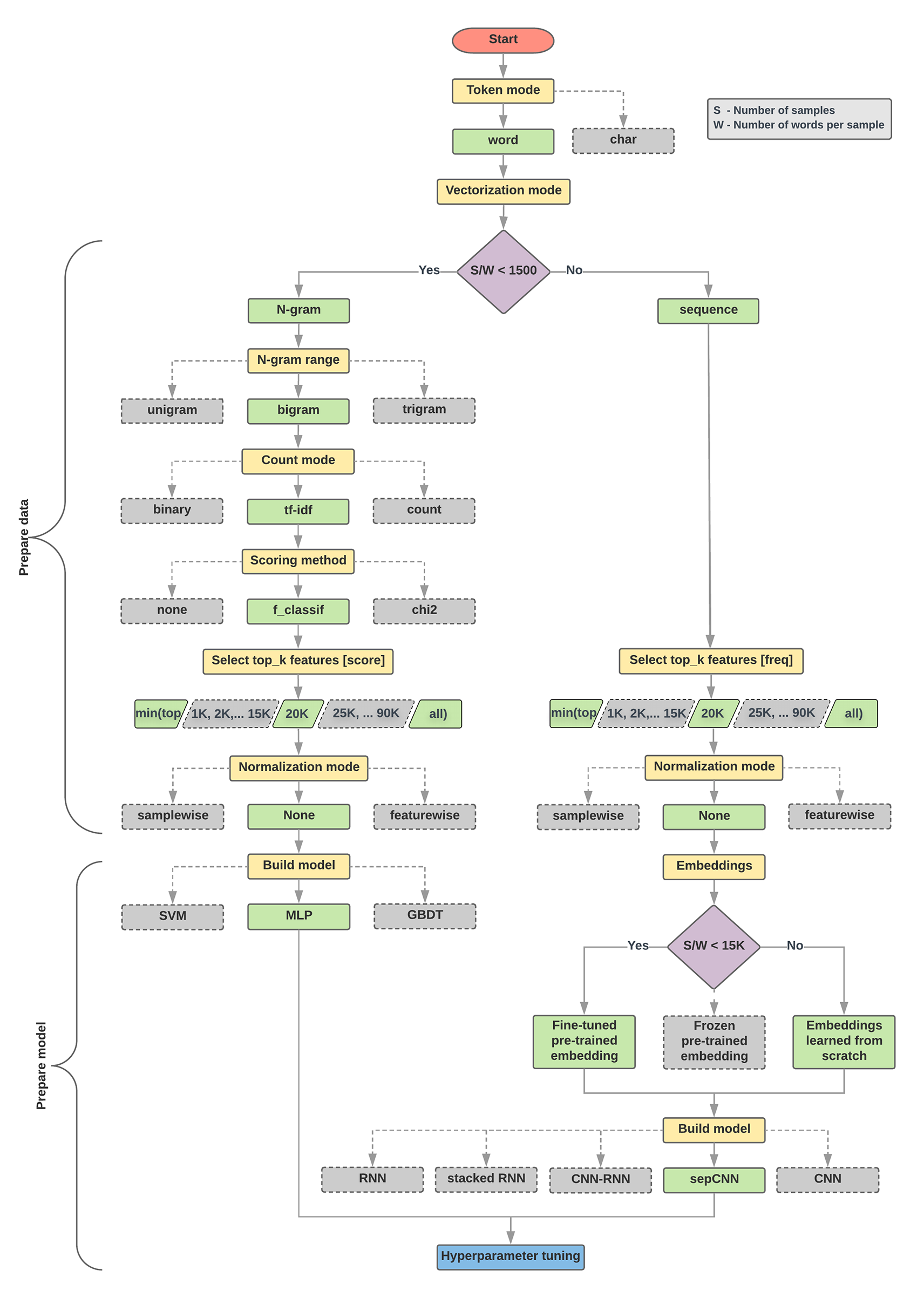
Figura 5: fluxograma de classificação de texto
Esse fluxograma responde a duas perguntas principais:
- Qual algoritmo ou modelo de aprendizado você deve usar?
- Como você deve preparar os dados para aprender de maneira eficiente a relação entre texto e rótulo?
A resposta à segunda pergunta depende da resposta à primeira pergunta. A maneira como pré-processamos os dados para serem alimentados em um modelo depende do modelo escolhido. Os modelos podem ser amplamente classificados em duas categorias: aqueles que usam informações de ordenação de palavras (modelos sequenciais) e aqueles que apenas veem o texto como "sacos" (conjuntos) de palavras (modelos n-grama). Os tipos de modelos sequenciais incluem redes neurais convolucionais (CNNs), redes neurais recorrentes (RNNs, na sigla em inglês) e as respectivas variações. Os tipos de modelos n-gram incluem:
- regressão logística
- perceptrons de várias camadas simples (MLPs, redes neurais totalmente conectadas)
- árvores otimizadas com gradiente
- máquinas de vetor de suporte
Com nossos experimentos, observamos que a proporção entre "número de amostras" (S) e "número de palavras por amostra" (W) está relacionada a qual modelo tem um bom desempenho.
Quando o valor dessa proporção é pequeno (<1.500), perceptrons pequenos de várias camadas que usam n-gramas como entrada (o que chamaremos de Opção A) têm um desempenho melhor ou pelo menos tão bom quanto os modelos sequenciais. As MLPs são simples de definir e entender, além de ter muito menos tempo de computação do que os modelos sequenciais. Quando o valor dessa proporção for grande (>= 1.500), use um modelo sequencial (opção B). Nas etapas a seguir, pule para as subseções relevantes (rotuladas como A ou B) para o tipo de modelo escolhido com base na proporção amostras/palavras por amostra.
No caso do nosso conjunto de dados de revisão do IMDb, a proporção amostras/palavras por amostra é de aproximadamente 144. Isso significa que vamos criar um modelo de MLP.