Sebelum dapat diinput ke model, data perlu diubah ke format yang dapat dipahami model.
Pertama, sampel data yang telah kita kumpulkan mungkin dalam urutan tertentu. Kami tidak ingin informasi apa pun yang terkait dengan urutan sampel mempengaruhi hubungan antara teks dan label. Misalnya, jika suatu {i>dataset <i}diurutkan berdasarkan kelas dan kemudian dibagi menjadi set pelatihan/validasi, set ini tidak akan mewakili keseluruhan distribusi data.
Praktik terbaik yang sederhana untuk memastikan model tidak terpengaruh oleh urutan data adalah selalu mengacak data sebelum melakukan hal lain. Jika data Anda sudah dibagi menjadi set pelatihan dan validasi, pastikan untuk mengubah validasi data dengan cara yang sama Anda mengubah data pelatihan. Jika Anda belum set validasi dan pelatihan terpisah, Anda dapat membagi sampel setelah mengacak; hal yang umum adalah menggunakan 80% sampel untuk pelatihan dan 20% untuk validasi.
Kedua, algoritma machine learning menggunakan angka sebagai input. Ini berarti bahwa kita perlu mengonversi teks menjadi vektor numerik. Ada dua langkah untuk proses ini:
Tokenisasi: Bagi teks menjadi kata-kata atau sub-teks yang lebih kecil, yang akan memungkinkan generalisasi hubungan yang baik antara teks dan label. Ini menentukan “kosakata” dari {i>dataset<i} (kumpulan token unik yang ada dalam data).
Vektorisasi: Menentukan ukuran numerik yang baik untuk menggambarkannya teks.
Mari kita lihat bagaimana melakukan dua langkah ini untuk vektor n-gram dan urutan vektor, serta cara mengoptimalkan representasi vektor menggunakan teknik pemilihan dan normalisasi.
Vektor N-gram [Opsi A]
Di paragraf berikutnya, kita akan melihat cara melakukan tokenisasi dan vektorisasi untuk model n-gram. Kita juga akan membahas bagaimana kita dapat mengoptimalkan gram menggunakan teknik pemilihan fitur dan normalisasi.
Dalam vektor n-gram, teks direpresentasikan sebagai kumpulan n-gram unik:
kumpulan n token yang berdekatan (biasanya, kata). Pertimbangkan teks The mouse ran
up the clock. Di sini:
- Kata unigram (n = 1) adalah
['the', 'mouse', 'ran', 'up', 'clock']. - Kata bigram (n = 2) adalah
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - Dan seterusnya.
Tokenisasi
Kita telah menemukan bahwa tokenisasi menjadi unigram kata + bigram memberikan hasil lebih akurat dengan waktu komputasi yang lebih singkat.
Vektorisasi
Setelah kita membagi contoh teks menjadi n-gram, kita perlu mengubah n-gram ini menjadi vektor numerik yang dapat diproses oleh model machine learning kita. Contoh di bawah ini menunjukkan indeks yang ditetapkan ke unigram dan bigram yang dihasilkan untuk dua teks.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Setelah indeks ditetapkan ke n-gram, kami biasanya menggunakan vektorisasi opsi berikut.
Encoding one-hot: Setiap contoh teks ditampilkan sebagai vektor yang menunjukkan ada atau tidaknya token di dalam teks.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Encoding jumlah: Setiap teks contoh ditampilkan sebagai vektor yang menunjukkan
jumlah token di dalam teks. Perhatikan, elemen yang sesuai dengan
unigram 'the' sekarang direpresentasikan sebagai 2 karena kata "the"
muncul dua kali dalam teks.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Encoding Tf-idf: Masalahnya dengan dua pendekatan di atas adalah kata-kata umum yang muncul dalam frekuensi di semua dokumen (yaitu, kata-kata yang tidak terlalu unik untuk sampel teks dalam set data) tidak dikenakan sanksi. Misalnya, kata-kata seperti “a” akan sangat sering muncul di semua teks. Jumlah token yang lebih tinggi untuk "{i>the<i}" daripada untuk kata lain yang lebih bermakna tidak terlalu berguna.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Lihat Scikit-learn TfidfTransformer)
Ada banyak representasi vektor lainnya, tetapi tiga representasi sebelumnya adalah paling umum digunakan.
Kami mengamati bahwa pengkodean tf-idf sedikit lebih baik daripada dua lainnya di hal akurasi (rata-rata: 0,25-15% lebih tinggi), dan merekomendasikan penggunaan metode ini untuk vektorisasi n-gram. Namun, perlu diingat bahwa tindakan ini menghabiskan lebih banyak memori (karena metode ini menggunakan representasi floating point) dan memerlukan waktu komputasi yang lebih lama, terutama untuk {i>dataset<i} besar (bisa memakan waktu dua kali lebih lama dalam beberapa kasus).
Pilihan fitur
Saat kita mengonversi semua teks dalam {i>dataset<i} ke dalam token kata uni+bigram, kita akan menghasilkan puluhan ribu token. Tidak semua token/fitur ini berkontribusi pada prediksi label. Kita bisa melepaskan token tertentu, misalnya yang sangat jarang terjadi di seluruh {i>dataset<i}. Kita juga bisa mengukur tingkat kepentingan fitur (berapa besar kontribusi setiap token terhadap prediksi label), dan hanya mencakup token yang paling informatif.
Ada banyak fungsi statistik yang menggunakan fitur dan fungsi label dan menghasilkan skor tingkat kepentingan fitur. Dua fungsi yang umum digunakan adalah f_classif dan chi2. Dengan eksperimen menunjukkan bahwa kedua fungsi ini bekerja dengan sama baiknya.
Yang lebih penting, kami melihat bahwa akurasi mencapai puncaknya sekitar 20.000 fitur bagi banyak set data (Lihat Gambar 6). Penambahan fitur lainnya melalui nilai minimum ini berkontribusi sangat sedikit dan kadang-kadang bahkan mengarah pada overfitting dan menurunkan performa.

Gambar 6: Fitur Top K versus Akurasi. Di seluruh set data, akurasinya mencapai sekitar 20 ribu fitur teratas.
Normalisasi
Normalisasi mengonversi semua nilai fitur/sampel menjadi nilai yang kecil dan serupa. Hal ini menyederhanakan konvergensi penurunan gradien dalam algoritma pembelajaran. Dari apa yang kita lihat, normalisasi selama pra-pemrosesan data tampaknya tidak menambah dalam masalah klasifikasi teks; sebaiknya lewati langkah ini.
Kode berikut menyatukan semua langkah di atas:
- Membuat token sampel teks ke dalam kata uni+bigram,
- Vektorisasi menggunakan pengkodean tf-idf,
- Pilih hanya 20.000 fitur teratas dari vektor token dengan membuang token yang muncul kurang dari 2 kali dan menggunakan f_classif untuk menghitung fitur tingkat kepentingan.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
Dengan representasi vektor n-gram, kita membuang banyak informasi tentang kata urutan dan tata bahasa (paling baik, kita dapat mempertahankan beberapa informasi pemesanan parsial saat n > 1.) Hal ini disebut pendekatan kantong kata. Representasi ini digunakan bersama dengan model yang tidak memperhitungkan pengurutan, seperti regresi logistik, perseptron multi-lapisan, mesin penguat gradien, mendukung mesin vektor.
Vektor Urutan [Opsi B]
Di paragraf berikutnya, kita akan melihat cara melakukan tokenisasi dan vektorisasi untuk model urutan. Kita juga akan membahas cara mengoptimalkan urutan yang menggunakan teknik pemilihan fitur dan normalisasi.
Untuk beberapa contoh teks, urutan kata sangat penting untuk makna teks. Sebagai contoh, kalimat, “Saya dulu benci perjalanan saya. Sepeda baru saya mengubahnya sepenuhnya” hanya dapat dipahami ketika dibaca secara berurutan. Model seperti CNN/RNN dapat menyimpulkan makna dari urutan kata-kata dalam sampel. Untuk model ini, kita mewakili teks sebagai urutan token, menjaga ketertibannya.
Tokenisasi
Teks dapat direpresentasikan sebagai urutan karakter, atau urutan kata. Kami telah menemukan bahwa menggunakan representasi tingkat kata memberikan performa daripada token karakter. Inilah norma umum yang diikuti oleh industri. Token karakter dapat digunakan hanya jika teks memiliki banyak {i>typo<i}, yang biasanya tidak terjadi.
Vektorisasi
Setelah mengonversi contoh teks menjadi rangkaian kata, kita perlu mengubah urutan ini menjadi vektor numerik. Contoh di bawah ini menunjukkan indeks ke unigram yang dihasilkan untuk dua teks, dan kemudian urutan token indeks tempat teks pertama dikonversi.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Indeks yang ditetapkan untuk setiap token:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
CATATAN: Kata "the" paling sering terjadi, sehingga nilai indeks 1 adalah yang ditetapkan untuknya. Beberapa library mencadangkan indeks 0 untuk token yang tidak diketahui, sebagaimana adanya yang terjadi di sini.
Urutan indeks token:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Ada dua opsi yang tersedia untuk memvektorkan urutan token:
Encoding one-hot: Urutan direpresentasikan menggunakan vektor kata dalam format n- ruang dimensi di mana n = ukuran kosakata. Representasi ini berfungsi dengan baik ketika kita melakukan tokenisasi sebagai karakter, dan kosakatanya kecil. Ketika kita menggunakan token sebagai kata, kosakata biasanya akan memiliki puluhan ribuan token, sehingga vektor {i>one-hot<i} menjadi sangat jarang dan tidak efisien. Contoh:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Penyematan kata: Kata memiliki makna yang terkait dengannya. Hasilnya, kami dapat mewakili token kata di ruang vektor padat (~ beberapa ratus angka real), di mana lokasi dan jarak antarkata menunjukkan seberapa mirip kata tersebut secara semantik (Lihat Gambar 7). Representasi ini disebut penyematan kata.
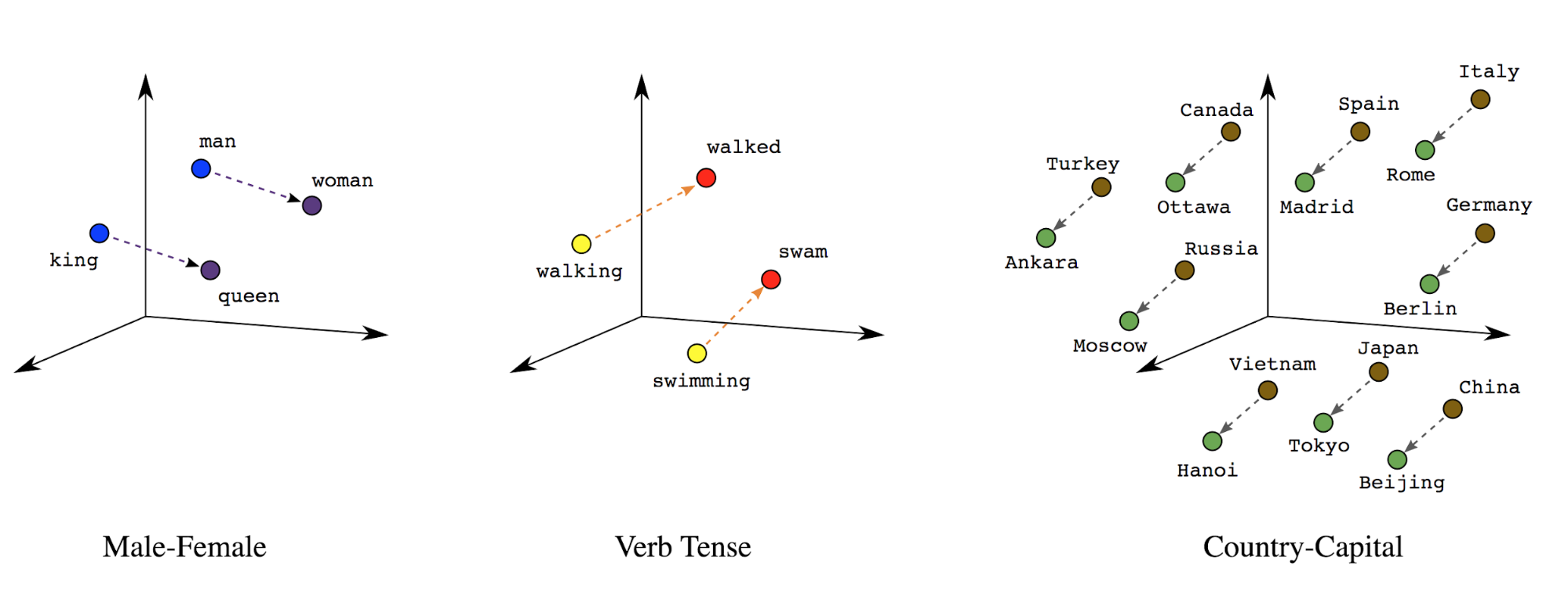
Gambar 7: Penyematan kata
Model urutan sering kali memiliki lapisan embedding sebagai lapisan pertamanya. Ini mengubah urutan indeks kata menjadi vektor embedding kata selama proses pelatihan, sehingga setiap indeks kata dipetakan ke vektor padat nilai sebenarnya yang mewakili lokasi kata tersebut dalam ruang semantik (Lihat Gambar 8).
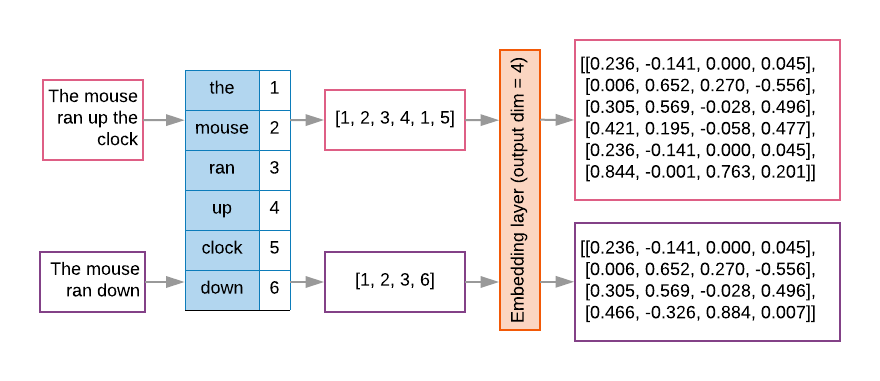
Gambar 8: Lapisan embedding
Pilihan fitur
Tidak semua kata dalam data kita berkontribusi pada prediksi label. Kita dapat mengoptimalkan pembelajaran dengan membuang kata-kata yang langka atau tidak relevan dari kosakata kita. Di beberapa faktanya, kami mengamati bahwa menggunakan 20.000 fitur yang paling sering memadai. Hal ini juga berlaku untuk model n-gram (Lihat Gambar 6).
Mari kita menempatkan semua langkah di atas dalam vektorisasi urutan bersama-sama. Tujuan kode berikut akan menjalankan tugas ini:
- Membuat token teks menjadi kata
- Membuat kosakata menggunakan 20.000 token teratas
- Mengonversi token menjadi vektor urutan
- Membubuhkan urutan ke panjang urutan tetap
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Vektorisasi label
Kita melihat cara mengonversi data teks sampel menjadi vektor numerik. Proses yang serupa
harus diterapkan pada label. Kita cukup mengonversi label
menjadi nilai dalam rentang
[0, num_classes - 1]. Sebagai contoh, jika ada 3 class
yang bisa kita gunakan
nilai 0, 1 dan 2 yang mewakili mereka. Secara internal, jaringan akan
menggunakan metode one-hot
vektor untuk merepresentasikan nilai-nilai ini (untuk menghindari menginferensikan hubungan yang tidak tepat
antarlabel). Representasi ini tergantung pada {i>
loss <i}dan {i>string<i}
lapisan aktivasi yang kita gunakan di jaringan neural kita. Kita akan belajar
lebih lanjut tentang
menjelaskan hal tersebut di bagian selanjutnya.