데이터를 모델에 공급하려면 먼저 데이터를 형식으로 변환해야 합니다. 알 수 있습니다.
첫째, 수집한 데이터 샘플이 특정 순서로 되어 있을 수 있습니다. 저희가 진행합니다. 샘플 순서에 관련된 어떠한 정보도 이해하는 것이 중요합니다. 예를 들어 데이터 세트가 학습/검증 세트로 분할하면 이러한 세트는 전체 데이터 분포를 나타냅니다.
모델이 데이터 순서의 영향을 받지 않도록 하는 간단한 권장사항은 다른 작업을 하기 전에 항상 데이터를 셔플합니다. 데이터가 이미 학습 세트와 검증 세트로 나누는 경우, 검증을 학습 데이터를 변환하는 것과 동일한 방식으로 데이터를 사용할 수 있습니다 아직 학습 세트와 검증 세트를 별도로 마련한 다음 셔플 사용 샘플의 80% 는 학습에, 20% 는 학습에 사용하는 것이 일반적입니다. 있습니다.
둘째, 머신러닝 알고리즘이 숫자를 입력으로 취합니다. 즉, 텍스트를 숫자 벡터로 변환해야 합니다. 두 단계를 통해 이 프로세스는
토큰화: 텍스트를 단어 또는 더 작은 하위 텍스트로 나눕니다. 텍스트와 라벨 간의 관계를 정상적으로 일반화할 수 있습니다. 이것은 데이터 세트의 '어휘'( 참조)
벡터화: 다음을 특성화하기 위한 적절한 수치 측정값을 정의합니다. 텍스트
N-그램 벡터와 시퀀스에서 모두 이 두 단계를 수행하는 방법을 알아보겠습니다. 특성 추출을 사용하여 벡터 표현을 선택 및 정규화 기법에 대해 배웠습니다.
N-그램 벡터[옵션 A]
다음 단락에서는 토큰화를 수행하고 벡터화에 사용할 수 있습니다. 또한 n-1을 그램 표현을 사용한 학습 모델입니다.
N-그램 벡터에서 텍스트는 고유한 N-그램 모음으로 표현됩니다.
n개의 인접한 토큰 그룹 (일반적으로 단어) The mouse ran
up the clock 텍스트를 살펴보겠습니다. 여기에서
- 유니그램 (n = 1)이라는 단어는
['the', 'mouse', 'ran', 'up', 'clock']입니다. - 'bigrams'(n = 2)라는 단어는
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock']입니다. - 그 밖에도 많은 사례가 있습니다.
토큰화
단어 유니그램과 바이그램으로 토큰화하는 것이 컴퓨팅 시간도 단축할 수 있으며 정확성은 향상됩니다.
벡터화
텍스트 샘플을 N-그램으로 분할한 후에는 이 N-그램을 숫자 벡터로 변환합니다. 예시 아래는 두 입력 문장에 대해 생성된 유니그램과 바이그램에 할당된 텍스트
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
색인이 N-그램에 할당되면 일반적으로 사용할 수 있습니다.
원-핫 인코딩: 모든 샘플 텍스트는 텍스트의 토큰 유무
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
카운트 인코딩: 모든 샘플 텍스트는
토큰의 개수를 나타냅니다. 참고:
유니그램 'the' 이제 2로 표시됩니다. 'the'라는 단어가
텍스트가 두 번 표시됩니다.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf 인코딩: 문제 한 가지 공통점이 있는데요, 모든 문서의 게재빈도 (예: 데이터 세트의 텍스트 샘플)에는 불이익을 받지 않습니다. 예를 들어 'a'와 같은 단어는 모든 텍스트에서 매우 자주 등장합니다. 따라서 'the'에 대한 토큰 수가 그다지 유용하지 않습니다
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(scikit-learn TfidfTransformer 참조)
다른 많은 벡터 표현이 있지만 앞의 세 가지는 가장 많이 사용됩니다.
tf-idf 인코딩이 tf-idf 인코딩이 (평균: 0.25~15% 더 높음), 이 방법을 사용할 것을 권장합니다. 임베딩 레이어입니다. 그러나 더 많은 메모리를 차지합니다( 부동 소수점 표현을 사용) 계산에 더 많은 시간이 걸립니다. 특히 대규모 데이터 세트의 경우에 적합합니다 (경우에 따라 두 배 더 오래 걸릴 수 있음).
특성 선택
데이터 세트의 모든 텍스트를 단어 유니+비그램 토큰으로 변환할 때 수만 개의 토큰이 될 수 있습니다. 일부 토큰/기능은 아님 라벨 예측에 기여할 수 있습니다. 예를 들어 특정 토큰을 드롭할 수 있습니다. 극히 드물게 발생하는 경우에 가장 적합합니다 또한 인코더-디코더 아키텍처를 특성 중요도 (각 토큰이 라벨 예측에 기여하는 정도) 가장 유용한 토큰만 포함합니다
특성을 취하는 여러 통계 함수가 있으며 특성 중요도 점수를 출력합니다. 일반적으로 사용되는 두 가지 함수는 f_classif 및 chi2. Google의 실험에 따르면 두 함수 모두 동일한 성능을 발휘합니다.
무엇보다도 여러 모델의 정확성이 약 20,000개에서 (그림 6 참고) 이 임곗값을 초과하는 특성을 추가하면 기여도가 높아집니다. 경우에 따라서는 과적합 성능이 저하됩니다
<ph type="x-smartling-placeholder">
그림 6: Top K 특성과 정확성 비교 데이터 세트 전반에서 정확성은 상위 20, 000개 가량에 정체되어 있습니다.
정규화
정규화는 모든 특성/표본 값을 작고 유사한 값으로 변환합니다. 이를 통해 학습 알고리즘의 경사하강법 수렴이 간소화됩니다. 대상 데이터 전처리 도중 정규화는 데이터 처리에 텍스트 분류 문제의 값 이 단계는 건너뛰는 것이 좋습니다.
다음 코드는 위의 모든 단계를 하나로 모은 것입니다.
- 텍스트 샘플을 단어 유니+비그램으로 토큰화
- tf-idf 인코딩을 사용하여 벡터화
- 토큰을 삭제하여 토큰 벡터에서 상위 20,000개의 특성만 선택하세요. 2회 미만으로 나타나는 토큰과 f_classif를 사용하여 특성을 계산 중요도가 높습니다.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
N-그램 벡터 표현을 사용하면 단어에 대한 많은 정보를 순서와 문법에 맞추어 부분적인 순서 정보를 유지하는 것이 좋습니다. n >일 때 1) 이를 단어 집합 접근 방식이라고 합니다. 이러한 표현은 정렬을 고려하지 않는 모델과 함께 사용하는 경우(예: 로지스틱 회귀, 다층 퍼셉트론, 경사 부스팅 머신 벡터 머신을 지원합니다.
시퀀스 벡터[옵션 B]
다음 단락에서는 토큰화를 수행하고 벡터화에 사용할 수 있습니다. 또한 광고 투자수익을 최적화하여 특성 선택 및 정규화 기법을 사용하여 시퀀스 표현을 사용하는 것을 배웠습니다
일부 텍스트 샘플의 경우 단어 순서가 텍스트의 의미에 매우 중요합니다. 대상 예를 들어 '출퇴근하는 시간이 정말 싫었어요. 새 자전거가 그것을 바꿨습니다 순서대로 읽을 때만 이해할 수 있습니다. CNN/RNN 등의 모델 표본의 단어 순서에서 의미를 추론할 수 있습니다. 이러한 모델의 경우 순서를 유지하는 토큰 시퀀스로 텍스트를 나타냅니다.
토큰화
텍스트는 일련의 문자 또는 학습합니다. 단어 수준의 표현을 사용하는 것이 성능을 발휘할 수 있습니다 이것은 또한 인코더-디코더 아키텍처를 산업이 뒤를 이었습니다 문자 토큰 사용은 오타가 발생할 수 있습니다.
벡터화
텍스트 샘플을 단어 시퀀스로 변환했으면 숫자 벡터로 변환합니다. 아래 예는 두 텍스트에 대해 생성된 유니그램에 할당된 다음 첫 번째 텍스트가 변환되는 색인입니다.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
모든 토큰에 할당된 색인:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
참고: 'the'라는 단어는 발생하므로 인덱스 값 1은 할 수 있습니다. 일부 라이브러리는 다음과 같이 알 수 없는 토큰에 대해 색인 0을 예약합니다. 살펴보겠습니다
토큰 색인 시퀀스:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
토큰 시퀀스를 벡터화하는 데 사용할 수 있는 옵션은 두 가지입니다.
원-핫 인코딩: n-1 형식의 단어 벡터를 사용하여 시퀀스를 표현합니다. n은 어휘의 크기입니다. 이 표현은 따라서 어휘가 작기 때문입니다. 단어로 토큰화할 때, 어휘는 일반적으로 수십 개의 원-핫 벡터가 매우 희소하고 비효율적이 됩니다. 예:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
단어 임베딩: 단어에는 연관된 의미가 있습니다. 그 결과 밀집 벡터 공간 (약 수백 개의 실수)에서 단어 토큰을 표현할 수 있습니다. 단어 간 위치와 거리는 단어 간의 유사 정도를 나타냄 의미론적으로 (그림 7 참고) 이러한 표현을 단어 임베딩입니다.
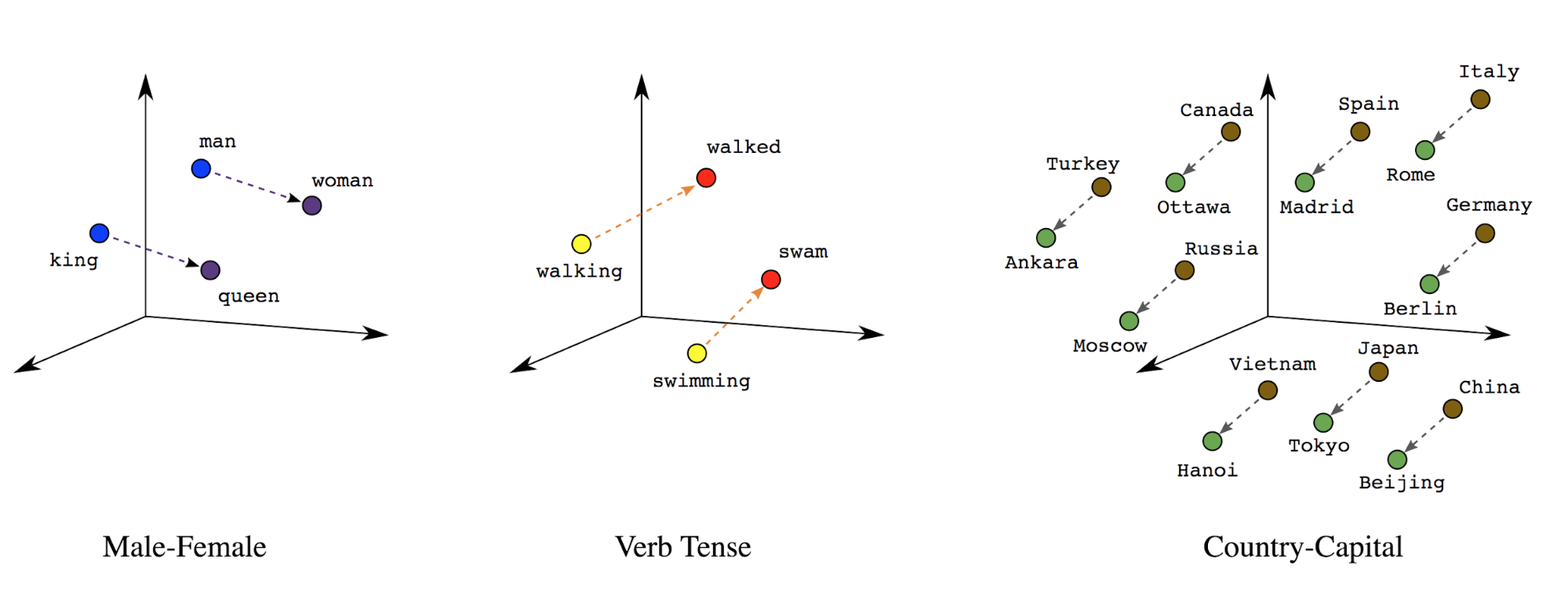
그림 7: 단어 임베딩
시퀀스 모델에는 이러한 임베딩 레이어가 첫 번째 레이어로 있는 경우가 많습니다. 이 단어 임베딩 벡터로 변환하는 방법을 학습하는 각 단어 색인이 실제 값을 사용하여 단어의 위치를 나타내는 실제 값을 나타냅니다 (그림 8 참고).
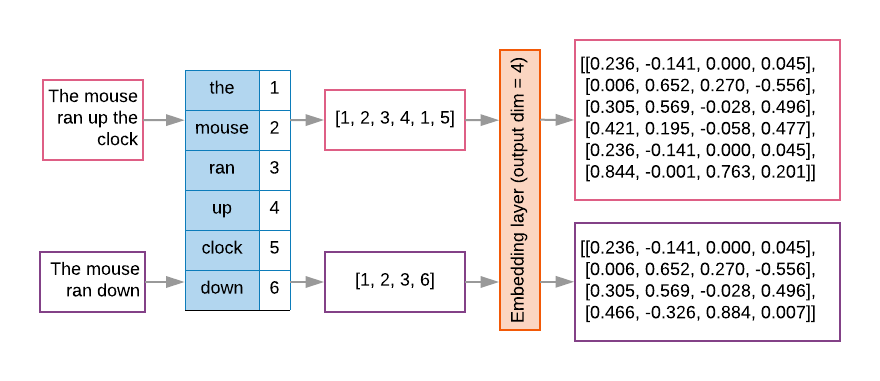
그림 8: 임베딩 레이어
특성 선택
데이터의 모든 단어가 라벨 예측에 기여하는 것은 아닙니다. 이를 통해 학습 프로세스를 향상시킵니다. 포함 20,000개의 특성을 가장 자주 사용하는 것이 충분합니다 이는 N-그램 모델에서도 마찬가지입니다 (그림 6 참고).
위의 모든 단계를 시퀀스 벡터화에 종합해 보겠습니다. 이 다음 코드가 이러한 작업을 수행합니다.
- 텍스트를 단어로 토큰화
- 상위 20,000개의 토큰을 사용해 어휘를 만듭니다.
- 토큰을 시퀀스 벡터로 변환
- 고정된 시퀀스 길이로 시퀀스 패딩
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
라벨 벡터화
샘플 텍스트 데이터를 숫자 벡터로 변환하는 방법을 살펴보았습니다. 유사한 프로세스
라벨에 적용되어야 합니다. 라벨을 범위 내의 값으로 변환하기만 하면 됩니다.
[0, num_classes - 1] 예를 들어 클래스가 3개 있는 경우
값을 0, 1, 2로 사용하여 이를 나타냅니다. 내부적으로 네트워크는 원-핫
잘못된 관계를 추론하는 것을 방지하기 위해
있습니다. 이 표현은 손실 함수와 마지막--
신경망에서 사용하는 레이어 활성화 함수입니다. 이 모듈의 뒷부분에서
다음 섹션에서 살펴보겠습니다