Avant de pouvoir transmettre nos données à un modèle, nous devons les transformer dans un format que le modèle peut comprendre.
Tout d'abord, les échantillons de données que nous avons collectés peuvent être dans un ordre spécifique. Nous qu'aucune information associée à l'ordre des échantillons ne doit influencer la relation entre les textes et les étiquettes. Par exemple, si un jeu de données est trié par classe, puis sont divisés en ensembles d'entraînement/de validation, ceux-ci ne sont pas représentatif de la distribution globale des données.
Pour s'assurer que le modèle n'est pas affecté par l'ordre des données, une bonne pratique simple consiste à brassent toujours les données avant toute autre action. Si vos données sont déjà divisé en ensembles d'entraînement et de validation, assurez-vous de transformer votre modèle de validation de la même manière que vous transformez vos données d'entraînement. Si ce n'est pas déjà fait, des ensembles distincts d'entraînement et de validation, vous pouvez diviser les échantillons lecture aléatoire on utilise en général 80% des échantillons pour l'entraînement et 20 % la validation.
Deuxièmement, les algorithmes de machine learning utilisent les nombres en tant qu'entrées. Cela signifie que nous devra convertir les textes en vecteurs numériques. Il y a deux étapes pour ce processus:
Tokenisation: divisez les textes en mots ou en sous-texte plus petits, permettent une bonne généralisation de la relation entre les textes et les étiquettes. Cela détermine le "vocabulaire" de l'ensemble de données (ensemble de jetons uniques présents dans les données).
Vectorisation: définissez une mesure numérique appropriée pour caractériser ces SMS.
Voyons comment effectuer ces deux étapes pour les vecteurs de n-grammes et la séquence vecteurs, et comment optimiser les représentations vectorielles à l'aide des caractéristiques de sélection et de normalisation.
Vecteurs de N-grammes [Option A]
Dans les paragraphes suivants, nous verrons comment procéder à la tokenisation et pour les modèles de N-grammes. Nous verrons également comment optimiser les n- à l'aide de techniques de sélection et de normalisation de caractéristiques.
Dans un vecteur de n-grammes, le texte est représenté sous la forme d'une collection de n-grammes uniques:
groupes de n jetons adjacents (généralement des mots). Prenons l'exemple du texte The mouse ran
up the clock. Ici:
- Les unigrammes de mots (n = 1) sont
['the', 'mouse', 'ran', 'up', 'clock']. - Les bigrammes (n = 2) sont
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - Et ainsi de suite.
Tokenisation
Nous avons constaté que la tokenisation en unigrammes et en bigrammes donne de bons résultats. tout en réduisant le temps de calcul.
Vectorisation
Une fois que nous avons divisé nos échantillons de texte en n-grammes, nous devons les transformer en vecteurs numériques que nos modèles de machine learning peuvent traiter. Exemple ci-dessous présente les index attribués aux unigrammes et aux bigrammes générés pour deux SMS.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Une fois les index attribués aux n-grammes, nous vectorisons généralement à l'aide de l'un des les options suivantes.
Encodage one-hot: chaque échantillon de texte est représenté sous forme de vecteur indiquant la présence ou l'absence d'un jeton dans le texte.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Encodage de nombres: chaque échantillon de texte est représenté sous forme de vecteur indiquant le
le nombre de jetons dans le texte. Notez que l'élément correspondant à
unigramme "the" est désormais représenté par 2, car le mot "le"
apparaît deux fois dans le texte.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Encodage Tf-idf: le problème. avec les deux approches ci-dessus est que les mots courants qui se produisent de manière similaire de fréquences dans tous les documents (mots qui ne sont pas particulièrement propres les échantillons de texte de l'ensemble de données) ne sont pas pénalisés. Par exemple, des mots comme "un" se produit très fréquemment dans tous les textes. Ainsi, un nombre de jetons plus élevé pour "the" pour d'autres mots plus significatifs n'est pas très utile.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Voir Scikit-learn TfidfTransformer)
Il existe de nombreuses autres représentations vectorielles, mais les trois précédentes sont le plus couramment utilisé.
Nous avons observé que l'encodage tf-idf est légèrement meilleur que les deux autres de précision (supérieure de 0,25 à 15% en moyenne), et nous vous recommandons d'utiliser cette méthode permettant de vectoriser des n-grammes. Cependant, n'oubliez pas qu'elle occupe plus de mémoire (comme elle utilise la représentation à virgule flottante) et prend plus de temps à calculer. en particulier pour les grands ensembles de données (cela peut prendre deux fois plus de temps dans certains cas).
Sélection des caractéristiques.
Lorsque nous convertissons tous les textes d'un jeu de données en jetons uni+bigrammes de mots, nous peut se retrouver avec des dizaines de milliers de jetons. Certains de ces jetons/caractéristiques contribuent à la prédiction d'étiquettes. Nous pouvons déposer certains jetons, par exemple ceux qui apparaissent extrêmement rarement dans l'ensemble de données. Nous pouvons aussi mesurer l'importance des caractéristiques (dans quelle mesure chaque jeton contribue aux prédictions d'étiquette) ; n'incluent que les jetons les plus informatifs.
De nombreuses fonctions statistiques utilisent des caractéristiques et les valeurs des étiquettes et génère le score d'importance des caractéristiques. Deux fonctions couramment utilisées sont f_classif et chi2. Notre les tests montrent que ces deux fonctions fonctionnent de la même manière.
Plus important encore, nous avons constaté que la précision atteint un pic avec environ 20 000 caractéristiques ensembles de données (voir Figure 6). L'ajout de caractéristiques au-delà de ce seuil contribue très peu et conduit parfois à surapprentissage et dégrade les performances.
<ph type="x-smartling-placeholder">
Figure 6: Caractéristiques des Top K et précision Pour tous les ensembles de données, la justesse s'approche des 20 000 premières caractéristiques.
Normalization
La normalisation convertit toutes les valeurs de caractéristiques/échantillons en valeurs petites et similaires. Cela simplifie la convergence de la descente de gradient dans les algorithmes d'apprentissage. D'après quoi comme nous l'avons vu, la normalisation lors du prétraitement des données ne semble pas apporter grand-chose la valeur dans les problèmes de classification de texte ; nous vous recommandons d'ignorer cette étape.
Le code suivant rassemble toutes les étapes ci-dessus:
- Tokeniser des échantillons de texte en uni+bigrammes de mots
- Vectoriser à l'aide de l'encodage tf-idf
- Ne sélectionner que les 20 000 premières caractéristiques du vecteur de jetons en les supprimant jetons qui apparaissent moins de deux fois et utilisant f_classif pour calculer la caractéristique l'importance.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
Avec la représentation vectorielle des n-grammes, nous supprimons de nombreuses informations relatives au mot l'ordre et la grammaire (au mieux, nous pouvons conserver certaines informations de tri partielles lorsque n > 1). C'est ce qu'on appelle une approche sac de mots. Cette représentation est utilisée conjointement avec des modèles qui ne tiennent pas compte de l'ordre, régression logistique, perceptrons à plusieurs couches, machines de boosting de gradient, sont compatibles avec les machines vectorielles.
Vecteurs de séquence [Option B]
Dans les paragraphes suivants, nous verrons comment procéder à la tokenisation et pour les modèles de séquence. Nous verrons aussi comment optimiser la représentation séquentielle à l'aide de techniques de sélection et de normalisation de caractéristiques.
Pour certains échantillons de texte, l'ordre des mots est essentiel à la signification du texte. Pour par exemple, les phrases : « Avant, je détestais mon trajet domicile-travail. Mon nouveau vélo a changé ça ne peuvent être interprétés que lorsqu'ils sont lus dans l'ordre. Modèles tels que des CNN/RNN peut déduire le sens de l'ordre des mots dans un échantillon. Pour ces modèles, nous représenter le texte sous la forme d'une séquence de jetons, ce qui préserve l'ordre.
Tokenisation
Le texte peut être représenté soit par une séquence de caractères, soit par une séquence de mots. Nous avons constaté que l'utilisation de la représentation au niveau du mot permet de mieux que les jetons de caractère. Il s'agit également de la norme générale puis le secteur. L'utilisation de jetons de caractère n'a de sens que si les textes ont beaucoup de fautes de frappe, ce qui n'est pas généralement le cas.
Vectorisation
Après avoir converti nos échantillons de texte en séquences de mots, nous devons transformer ces séquences en vecteurs numériques. L'exemple ci-dessous montre les index aux unigrammes générés pour deux textes, puis à la séquence de jetons index vers lesquels le premier texte est converti.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Index attribué à chaque jeton:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
REMARQUE: Le mot "le" se produit le plus fréquemment. La valeur d'indice de 1 est donc qui lui est attribuée. Certaines bibliothèques réservent l'index 0 aux jetons inconnus, comme l' le cas ici.
Séquence d'index de jetons:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Deux options s'offrent à vous pour vectoriser les séquences de jetons:
Encodage one-hot: les séquences sont représentées à l'aide de vecteurs de mots dans n- espace dimensionnel où n = taille du vocabulaire. Cette représentation fonctionne très bien lors de la tokenisation sous forme de caractères, ce qui réduit le vocabulaire employé. Lorsque nous sommes tokenisés sous forme de mots, le vocabulaire contient généralement des dizaines de des milliers de jetons, ce qui rend les vecteurs one-hot très creux et inefficaces. Exemple :
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Représentations vectorielles continues de mots: les mots ont une ou plusieurs significations. Par conséquent, nous peut représenter des jetons de mot dans un espace vectoriel dense (environ quelques centaines de nombres réels) ; L'emplacement et la distance entre les mots indiquent à quel point ils sont similaires sémantiquement (voir la Figure 7). Cette représentation s'appelle représentations vectorielles continues de mots.
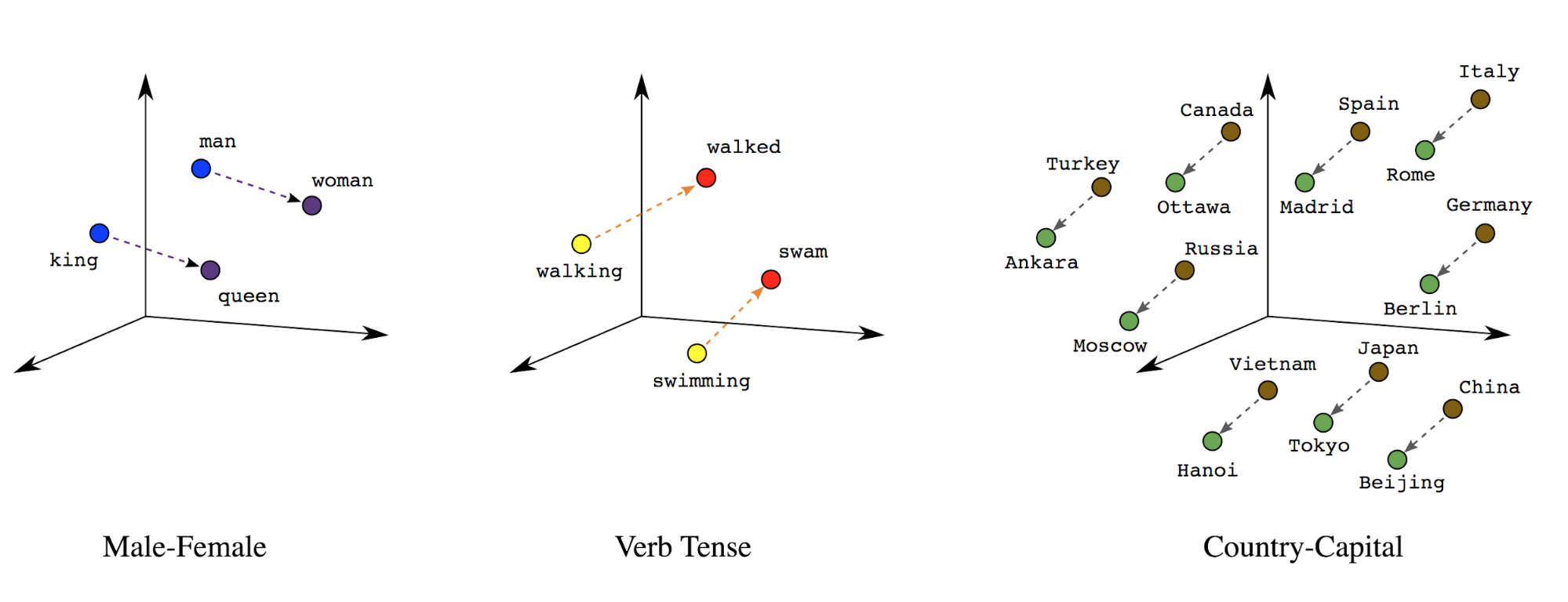
Figure 7: Représentations vectorielles continues de mots
Les modèles de séquence comportent souvent une couche de représentation vectorielle continue en tant que première couche. Ce apprend à transformer les séquences d'index de mots en vecteurs de représentation vectorielle continue de mots pendant la processus d'entraînement, de sorte que chaque index de mots soit mappé à un vecteur dense de des valeurs réelles représentant l'emplacement de ce mot dans l'espace sémantique (voir la Figure 8).
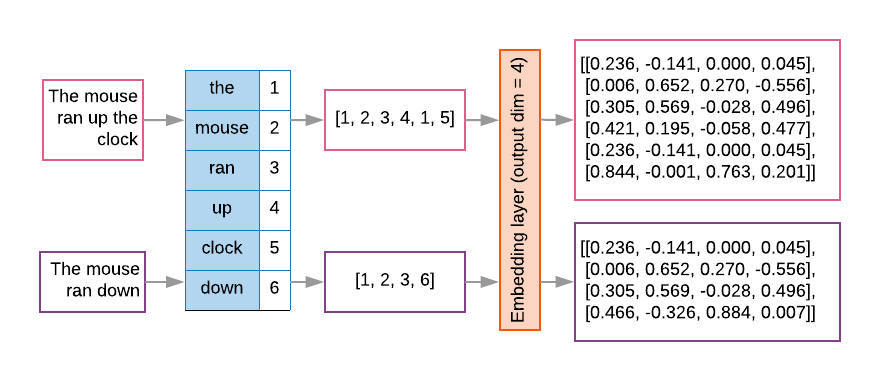
Figure 8: Couche de représentation vectorielle continue
Sélection des caractéristiques.
Tous les mots de nos données ne contribuent pas aux prédictions d'étiquettes. Nous pouvons optimiser d'apprentissage en éliminant les mots rares ou non pertinents de notre vocabulaire. Dans nous observons que l'utilisation des 20 000 caractéristiques les plus fréquentes suffisant. Ce principe s'applique également aux modèles de n-grammes (voir la Figure 6).
Réunissons toutes les étapes ci-dessus de la vectorisation de séquence. La le code suivant effectue ces tâches:
- Tokenisation des textes en mots
- Crée un vocabulaire à partir des 20 000 meilleurs jetons
- Convertit les jetons en vecteurs de séquence
- Remplit les séquences selon une longueur de séquence fixe
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Vectorisation des étiquettes
Nous avons vu comment convertir des échantillons de données textuelles en vecteurs numériques. Une procédure similaire
doit être appliqué aux étiquettes. Nous pouvons simplement convertir
les étiquettes en valeurs dans la plage
[0, num_classes - 1] Par exemple, s'il y a trois classes,
nous pouvons simplement utiliser
les valeurs 0, 1 et 2 pour les représenter. En interne, le réseau utilise
pour représenter ces valeurs (pour éviter d'inférer une relation incorrecte)
entre les étiquettes). Cette représentation dépend de la fonction de perte et
d'activation de couche que nous utilisons dans notre réseau de neurones. Nous en apprendrons plus
dans la section suivante.