כדי שאפשר יהיה להזין את הנתונים שלנו למודל, צריך להמיר אותו לפורמט המודל יכול להבין.
ראשית, דגימות הנתונים שאספנו עשויות להיות בסדר מסוים. אנחנו אני לא רוצה שמידע שקשור לסדר הדגימות ישפיע על הקשרים בין טקסטים ותוויות. לדוגמה, אם מערך נתונים ממוין לפי כיתה ואז מחולקות לקבוצות אימון/אימות, שמייצג את ההתפלגות הכוללת של הנתונים.
שיטה מומלצת פשוטה לוודא שהמודל לא מושפע מסדר הנתונים היא לערבב את הנתונים לפני ביצוע פעולה אחרת. אם הנתונים כבר מפוצלים לערכות אימון ואימות, ואל תשכחו לבצע טרנספורמציה של האימות את הנתונים באותו אופן שבו אתם משנים את נתוני האימון שלכם. אם עדיין לא עשיתם זאת בערכות נפרדות של אימון ואימות, אפשר לפצל את המדגם ההשמעה האקראית; בדרך כלל משתמשים ב-80% מהדגימות לאימון וב-20% אימות.
שנית, אלגוריתמים של למידת מכונה מקבלים מספרים כקלט. המשמעות היא שאנחנו יצטרכו להמיר את הטקסטים לווקטורים של מספרים. יש שני שלבים התהליך הזה:
אסימון: מאפשר לחלק את הטקסטים למילים או לטקסטי משנה קטנים יותר, לאפשר הכללה טובה של הקשר בין הטקסטים לתוויות. הדבר קובע את "אוצר המילים" של מערך הנתונים (קבוצה של אסימונים ייחודיים שקיימים ב ).
וקטורים: הגדרה של מדד מספרי טוב לאפיון הערכים האלה טקסטים.
בואו נראה איך לבצע את שני השלבים האלה בווקטורים של n-gram וגם לרצף האלה, וגם איך לבצע אופטימיזציה של ייצוגים בווקטורים באמצעות תכונה טכניקות בחירה ונירמול.
וקטורים של N-gram [אפשרות א]
בפסקאות הבאות נראה איך לבצע המרה לאסימונים הווקטורים של מודלים של n-gram. נסביר גם איך אפשר לבצע אופטימיזציה של של גרם באמצעות שיטות לבחירת תכונות ונירמול.
בווקטור n-gram, הטקסט מיוצג כאוסף של גרם ייחודי:
קבוצות של n אסימונים סמוכים (בדרך כלל מילים). חשוב לזכור את הטקסט The mouse ran
up the clock. כאן:
- המילה יוניגרמים (n = 1) היא
['the', 'mouse', 'ran', 'up', 'clock']. - המילה Bigrams (n = 2) היא
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - וכן הלאה.
יצירת אסימונים
גילינו שיצירת אסימונים לאסימונים דיוק של פחות זמן מחשוב.
וקטורים
אחרי שמפצלים את דוגמאות הטקסט ל-n-gram, אנחנו צריכים להמיר את ה-n-gram בווקטורים מספריים שהמודלים של למידת המכונה שלנו יכולים לעבד. הדוגמה בהמשך מוצגים המדדים שהוקצו ליוניגרמים ול-Bigram שנוצרו טקסטים.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
אחרי שמקצים אינדקסים ל-n-gram, אנחנו בדרך כלל יוצרים וקטורים באמצעות אחד אפשרויות הבאות.
קידוד חד-פעמי: כל טקסט לדוגמה מיוצג בווקטור שמציין נוכחות או היעדר אסימון בטקסט.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
ספירת הקידוד: כל טקסט לדוגמה מיוצג בווקטור שמציין את
מספר אסימונים בטקסט. שימו לב שהרכיב שתואם לרכיב
unigram 'the' מיוצג עכשיו בתור 2 כי המילה "the"
מופיעה פעמיים בטקסט.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
קידוד Tf-idf: הבעיה בשתי הגישות שלמעלה הוא שמילים נפוצות שמופיעות בתדירות גבוהה בכל המסמכים (כלומר, מילים שאינן ייחודיות במיוחד על דגימות הטקסט שבמערך הנתונים) לא יוטלו סנקציות. לדוגמה, מילים כמו "a" יתרחשו לעיתים קרובות מאוד בכל הטקסטים. לכן מספר האסימונים שלך גבוה יותר עבור 'the' למילים אחרות בעלות משמעות.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(ניתן לעיין במאמר Scikit-learn TfidfTransformer)
יש הרבה ייצוגים אחרים של וקטורים, אבל שלושתם הקודמים הם הכי נפוצים.
שמנו לב שקידוד tf-idf גבוה במידה שולית יותר מהשניים האחרים מונחים מדויקים (בממוצע: גבוה ב-0.25%-15%), ומומלץ להשתמש בשיטה הזו. ליצירת וקטורים של n-גרם. עם זאת, חשוב לזכור שהזיכרון הזה תופס יותר זיכרון (כמו משתמש בייצוג נקודה צפה (floating-point) ונדרש יותר זמן כדי לחשב, במיוחד עבור מערכי נתונים גדולים (במקרים מסוימים התהליך עשוי להימשך זמן רב פי שניים).
בחירת תכונה
כשממירים את כל הטקסטים במערך נתונים לאסימוני מילה Unicode+bigram, אנחנו עלולים לקבל עשרות אלפי אסימונים. לא כל התכונות או האסימונים האלה משפיעים על חיזוי התווית. כך אנחנו יכולים לוותר על אסימונים מסוימים, כאלה שמתרחשים לעיתים רחוקות מאוד במערך הנתונים. ניתן גם למדוד חשיבות התכונה (כמה כל אסימון תורם לחיזויים של תוויות), וגם לכלול רק את האסימונים האינפורמטיביים ביותר.
קיימות פונקציות סטטיסטיות רבות שמשתמשות בתכונות תוויות ופלט של ציון החשיבות של התכונה. שתי פונקציות נפוצות f_classif וגם chi2. שלנו הניסויים מראים ששתי הפונקציות האלה מניבות ביצועים טובים באותה מידה.
וחשוב יותר, ראינו שרמת הדיוק משיקה כ-20,000 תכונות עבור רבים מערכי נתונים (ראו איור 6). הוספת עוד תכונות מעבר לסף הזה מקדמת מעט מאוד ולפעמים אפילו מוביל התאמת יתר והביצועים שלהן ייפגעו.

איור 6: התכונות המובילות (K) לעומת דיוק. במערכי נתונים שונים, רמות דיוק כוללות כ-20,000 תכונות מובילות.
נירמול
נירמול ממיר את כל הערכים של התכונות/הדגימה לערכים קטנים ודומים. זה מפשט את ההתכנסות של ירידות הדרגתיות באלגוריתמים של הלמידה. ממה ראינו, נראה שהנירמול במהלך העיבוד מראש של הנתונים לא מוסיף הרבה ערך בבעיות סיווג טקסט; מומלץ לדלג על השלב הזה.
הקוד הבא מסכם את כל השלבים שלמעלה:
- יצירת אסימונים עם דוגמאות טקסט לאסימונים
- וקטורים באמצעות קידוד tf-idf,
- בוחרים רק את 20,000 התכונות המובילות מהווקטור של האסימונים על ידי מחיקה אסימונים שמופיעים פחות מפעמיים ומשתמשים ב-f_classif כדי לחשב את התכונה בחשיבותו.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
באמצעות ייצוג וקטורי n-gram, אנחנו מוחקים מידע רב על מילים הסדר והדקדוק (בטוב ביותר, נוכל לשמור על פרטי הזמנה חלקיים כאשר n > 1). השיטה הזו נקראת 'שקית מילים'. הייצוג הזה משמש בשילוב עם מודלים שלא מביאים בחשבון את סוג ההזמנה, כגון רגרסיה לוגיסטית, פרספקטורים רב-שכבתיים, מכונות להגדלת הדרגתיות, שתומכים במכונות וקטוריות.
וקטורים של רצף [אפשרות ב']
בפסקאות הבאות נראה איך לבצע המרה לאסימונים ווקטורים של מודלים של רצף. נסביר גם איך אפשר לבצע אופטימיזציה וייצוג של רצף באמצעות שיטות בחירת תכונות וטכניקות נירמול.
בחלק מהדוגמאות, סדר המילים הוא גורם קריטי למשמעות הטקסט. עבור למשל את המשפטים, "פעם שנאתי את הנסיעה היומית שלי. האופניים החדשים שלי שינו זאת לגמרי' יכולה להיות מובנת רק אם קוראים לפי הסדר. מודלים כמו רשתות CNN/RNN יכול להסיק משמעות מסדר המילים שבדגימה. עבור המודלים האלה, שמייצגים את הטקסט כרצף של אסימונים תוך שימור הסדר.
יצירת אסימונים
טקסט יכול להיות מיוצג כרצף של תווים, או כרצף של ולא של מילים בודדות, גילינו ששימוש בייצוג ברמת המילה מספק ביצועים טובים יותר מאשר אסימוני תווים. זו גם הנורמה הכללית ולאחר מכן התעשייה. הגיוני להשתמש באסימוני תווים רק אם לטקסטים יש הרבה של שגיאות הקלדה, שבדרך כלל זה לא המצב.
וקטורים
אחרי שהומרנו את דוגמאות הטקסט לרצפים של מילים, אנחנו צריכים להפוך את הרצפים האלה לווקטורים מספריים. בדוגמה הבאה מוצגים האינדקסים לאותיות יוניגרמים שנוצרו לשני טקסטים, ואז לרצף של האסימון אינדקסים שאליהם הטקסט הראשון מומר.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
האינדקס שהוקצה לכל אסימון:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
הערה: המילה "the" מתרחשת בתדירות הגבוהה ביותר, לכן ערך האינדקס של 1 הוא שהוקצו לו. ספריות מסוימות שומרות את האינדקס 0 לאסימונים לא ידועים, כמו במקרה הזה.
רצף של אינדקסים של אסימונים:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
יש שתי אפשרויות ליצור וקטורים של רצפי אסימונים:
קידוד חד-פעמי: רצפים מיוצגים באמצעות וקטורים של מילים ב- n- שטח ממדי שבו n = גודל אוצר המילים. הייצוג הזה עובד מצוין כשממירים אסימונים בתור תווים, ולכן אוצר המילים קטן. כשאנחנו ממירים אסימונים כמילים, אוצר המילים כולל בדרך כלל עשרות אלפי אסימונים, דבר שהופך את הווקטורים החד-פעמיים לדליים מאוד ולא יעילים. דוגמה:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
הטמעות מילים: למילים יש משמעות. לאור זאת, יכול לייצג אסימונים מילוליים במרחב וקטורי צפוף (כמאות מספרים ממשיים), המיקום והמרחק בין המילים מציינים את מידת הדמיון בין המילים סמנטית (ראו איור 7). הייצוג הזה נקרא הטמעות מילים.
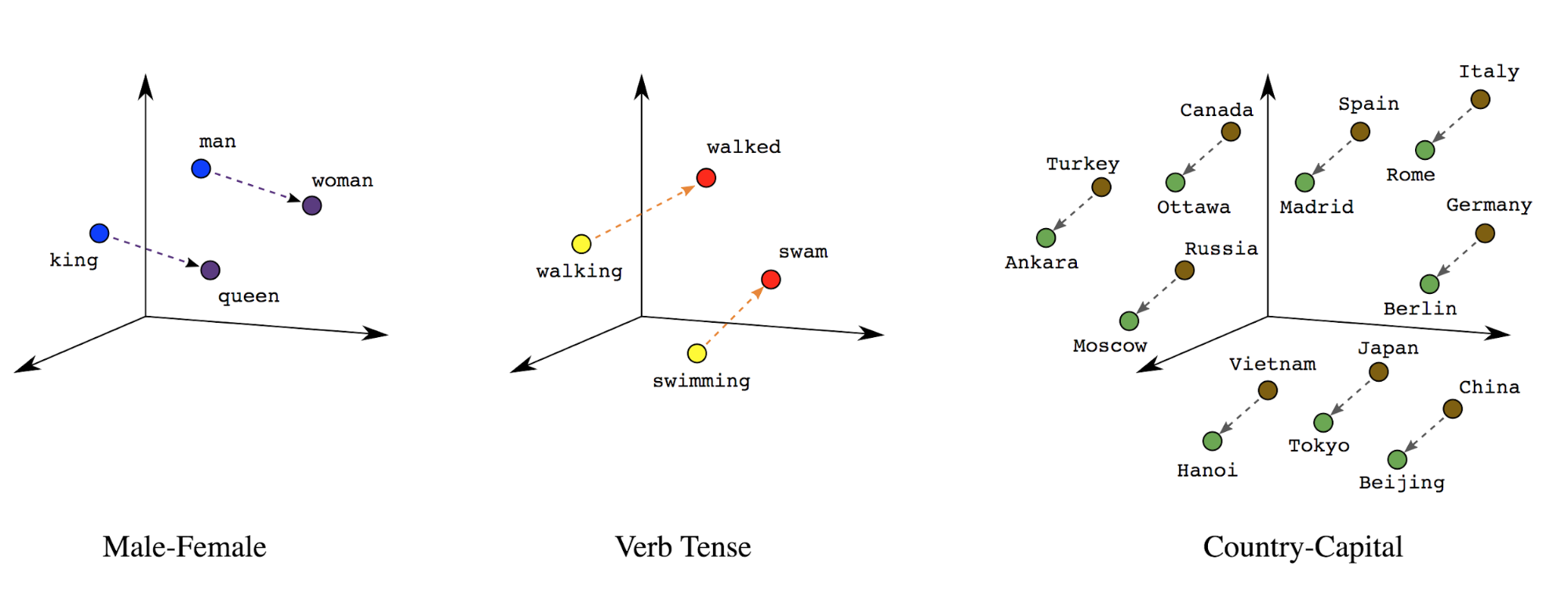
איור 7: הטמעות מילים
לרוב, במודלים של רצף יש שכבת הטמעה כמו השכבה הראשונה. הזה לומדת להפוך רצפים של אינדקס מילים לווקטורים של הטמעת מילים במהלך את תהליך האימון, כך שכל אינדקס מילים ממופה לווקטור דחוס ערכים ממשיים שמייצגים את המיקום של המילה ברווח סמנטי (ראו איור 8).
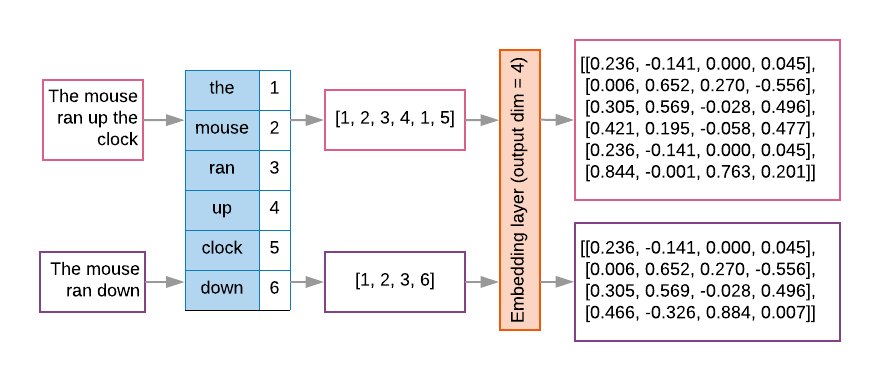
איור 8: שכבת ההטמעה
בחירת תכונה
לא כל המילים בנתונים שלנו תורמות לחיזויים של תוויות. אנחנו יכולים לבצע אופטימיזציה את תהליך הלמידה באמצעות מחיקת מילים נדירות או לא רלוונטיות מאוצר המילים שלנו. לחשבון למעשה, נוכל לראות שהשימוש ב-20,000 התכונות הכי נפוצות הוא בדרך כלל מספיק. הדבר נכון גם לגבי מודלים של n-gram (ראו איור 6).
נשלב את כל השלבים שלמעלה בווקטורים של רצף. הקוד הבא מבצע את המשימות האלה:
- המרת הטקסטים לאסימונים למילים
- יצירת אוצר מילים באמצעות 20,000 האסימונים המובילים
- ממירה את האסימונים לווקטורים של רצף
- התאמת הרצפים לאורך רצף קבוע
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
יצירת וקטורים של תוויות
ראינו איך להמיר נתוני טקסט לדוגמה לווקטורים מספריים. תהליך דומה
חייב להיות מיושם על התוויות. אנחנו יכולים פשוט להמיר תוויות לערכים בטווח
[0, num_classes - 1] לדוגמה, אם יש 3 כיתות שאנחנו יכולים פשוט להשתמש בהן
0, 1 ו-2 כדי לייצג אותם. באופן פנימי, הרשת תשתמש בתכונה אחת חמה
את הווקטורים שמייצגים את הערכים האלו (כדי להימנע מהסקת הקשר שגוי
בין תוויות). הייצוג הזה תלוי בפונקציית האובדן
את פונקציית הפעלת השכבות ברשת הנוירונים שלנו. נלמד על
בקטע הבא.