Zanim nasze dane pojawią się w modelu, trzeba je przekształcić do formatu zrozumiały dla modelu.
Po pierwsze, zebrane przez nas próbki danych mogą być podane w określonej kolejności. Nasza firma nie chcą, aby żadne informacje związane z kolejnością próbek miały wpływ na to, relacji między tekstami a etykietami. Jeśli na przykład zbiór danych jest posortowany według klas, a następnie zostaną podzielone na zbiory do trenowania i walidacji. Nie zostaną reprezentująca ogólny rozkład danych.
Prostym sposobem na zagwarantowanie, że kolejność danych nie będzie wpływać na model, jest zawsze tasować dane przed wykonaniem innych czynności. Jeśli Twoje dane są już podzielić na zbiory do trenowania i walidacji, pamiętaj, aby w taki sam sposób, w jaki przekształcasz dane treningowe. Jeśli jeszcze nie masz do trenowania i walidacji, możesz podzielić próbki po odtwarzanie losowe; zwykle do trenowania używa się 80% próbek, a 20% do trenowania weryfikacji danych.
Po drugie, algorytmy systemów uczących się traktują liczby jako dane wejściowe. Oznacza to, że na przekształcenie tekstów w wektory liczbowe. Do wykonania są 2 kroki ten proces:
Tokenizacja: podziel tekst na słowa lub mniejsze podteksty. pozwalają dobrze uogólnić zależności między tekstami a etykietami. Określa „słownik” zbioru danych (zbiór unikalnych tokenów znajdujących się w dane).
Wektoryzacja: określ dobry wskaźnik liczbowy, aby scharakteryzować te wartości. wiadomości.
Zobaczmy, jak wykonać te 2 kroki dla wektorów n-gramów i sekwencji oraz jak zoptymalizować reprezentację wektorów za pomocą funkcji oraz technik selekcji i normalizacji.
Wektory n-gram [opcja A]
W kolejnych akapitach dowiemy się, jak przeprowadzać tokenizację wektoryzacji dla modeli n-gramów. Omówimy też sposoby optymalizacji przy użyciu technik wyboru cech i normalizacji.
W wektorze n-gram tekst jest przedstawiony jako zbiór unikalnych n-gramów:
grupy n przyległych tokenów (zwykle słów). Zastanów się nad tekstem The mouse ran
up the clock. Tutaj:
- Słowo unigramy (n = 1) to:
['the', 'mouse', 'ran', 'up', 'clock']. - Słowo bigrams (n = 2) to:
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - I tak dalej.
Tokenizacja
Okazuje się, że tokenizacja do słownych unigramów + bigramów dokładności przy krótszym czasie obliczeń.
Wektoryzacja
Po podzieleniu próbek tekstowych na n-gramów musimy zamienić te na wektory liczbowe, które nasze modele mogą przetwarzać. Przykład poniżej pokazuje indeksy przypisane do unigramów i bigramów wygenerowanych dla dwóch wiadomości.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Po przypisaniu indeksów do n-gramów zwykle wektoryzujemy wektory przy użyciu jednej z tych metod: tych opcji.
Kodowanie jedno- gorące: każdy przykładowy tekst jest reprezentowany jako wektor wskazujący obecność lub brak tokena w tekście.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Kodowanie zliczania: każdy przykładowy tekst jest reprezentowany jako wektor wskazujący
token w tekście. Zwróć uwagę, że element odpowiadający argumentowi
unigram „the” jest teraz reprezentowane jako 2, ponieważ słowo „the”
pojawia się dwukrotnie w tekście.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Kodowanie Tf-idf: problem w przypadku obu powyższych metod polega na tym, że często występujące słowa występują w podobny sposób we wszystkich dokumentach (słowa, które nie są szczególnie przykłady tekstu w zbiorze danych) nie są karane. na przykład „a”; będą się pojawiać bardzo często w każdym tekście. Większa liczba tokenów dla „the” nie jest zbyt przydatna, by wymyślić inne słowa.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Patrz: Scikit-learn TfidfTransformer).
Istnieje wiele innych reprezentacji wektorowych, ale trzy ostatnie to wartości są najczęściej używane.
Zauważyliśmy, że kodowanie tf-IDf jest nieco lepsze niż pozostałe dokładności (średnio: 0,25-15%) i zaleca się użycie tej metody do wektoryzacji n-gramów. Pamiętaj jednak, że zajmuje więcej pamięci (ponieważ wykorzystuje reprezentację zmiennoprzecinkową) i jego obliczenia wymagają więcej czasu, zwłaszcza w przypadku dużych zbiorów danych (w niektórych przypadkach może to potrwać 2 razy dłużej).
Wybór funkcji
Gdy konwertujemy wszystkie teksty w zbiorze danych na tokeny uni+bigram, mogą otrzymać dziesiątki tysięcy tokenów. Nie wszystkie tokeny/funkcje mają udział w prognozowaniu etykiet. Możemy więc odrzucić określone tokeny, na przykład które występują bardzo rzadko w danym zbiorze danych. Możemy też mierzyć znaczenie cech (w jakim stopniu każdy token przyczynia się do prognoz dotyczących etykiet), oraz uwzględniaj tylko tokeny informacyjne.
Istnieje wiele funkcji statystycznych, które przyjmują cechy i odpowiadające im etykiety i wyświetlać wynik ważności cech. Dwie często używane funkcje to f_classif oraz chi2. Nasze eksperymenty pokazują, że obie funkcje mają taką samą skuteczność.
Co ważniejsze, zaobserwowaliśmy,że dokładność osiąga najwyższą się przy ok. 20 tys. cechach dla wielu z nich. i zbiory danych (zobacz Rys. 6). Dodanie większej liczby cech powyżej tego progu przyczynia się bardzo niewiele, a czasem nawet prowadzi nadmierne dopasowanie i pogarsza wydajność.

Rysunek 6. Najważniejsze funkcje K a dokładność We wszystkich zbiorach danych płaskowyże dokładności wynoszą około 20 tys. najlepszych obiektów.
Normalizacja
Normalizacja konwertuje wszystkie wartości cech/próbek na małe i podobne wartości. Upraszcza to zbieżność opadania gradientu w algorytmach uczenia się. Od czego ale normalizacja podczas wstępnego przetwarzania danych nie wnosi zbyt wiele wartości w problemach z klasyfikacją tekstu; zalecamy pominięcie tego kroku.
Poniższy kod łączy wszystkie powyższe kroki:
- tokenizację fragmentów tekstu w kodach uni+bigram,
- Wektoryzuj za pomocą kodowania tf-idf,
- Wybierz tylko 20 000 najważniejszych funkcji z wektora tokenów przez odrzucenie. tokeny pojawiające się mniej niż 2 razy i korzystające z klasy f_classif do obliczania funkcji znaczenie.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
W przypadku reprezentacji wektorowej n-gramów odrzucamy wiele informacji na temat słowa kolejność i gramatykę (najlepiej możemy zachować częściowe informacje na temat kolejności kiedy n > 1) Jest to tzw. szeptana strategia. Ta reprezentacja jest używana w połączeniu z modelami, które nie uwzględniają kolejności, np. regresja logistyczna, wielowarstwowe perceptrony, maszyny wzmacniające gradient do obsługi maszyn wektorowych.
Wektory sekwencji [opcja B]
W kolejnych akapitach dowiemy się, jak przeprowadzać tokenizację wektoryzacji dla modeli sekwencji. Omówimy też sposoby optymalizacji reprezentowanie sekwencji przy użyciu technik wyboru cech i normalizacji.
W niektórych przykładach tekstu kolejność słów ma znaczenie dla znaczenia tekstu. Dla: np. „kiedyś nie znoszę dojazdów do pracy. W moim nowym rowerze to się zmieniło w całości” można interpretować tylko w przypadku czytania w odpowiedniej kolejności. Modele, np. CNN/RNN, może wywnioskować znaczenie na podstawie kolejności słów w próbce. W przypadku tych modeli przedstawiają tekst jako sekwencję tokenów z zachowaniem kolejności.
Tokenizacja
Tekst może być ciągiem znaków albo ciągu słowa kluczowe. Zauważyliśmy, że reprezentacja na poziomie słowa zapewnia niż tokeny postaci. Jest to również ogólna norma, a następnie branża. Używanie tokenów postaci ma sens tylko wtedy, gdy tekst zawiera dużo literówek, co zwykle nie jest konieczne.
Wektoryzacja
Po przekonwertowaniu próbek tekstu na sekwencje słów trzeba użyć funkcji do postaci wektorów liczbowych. Przykład poniżej pokazuje indeksy przypisane do unigramów wygenerowanych dla dwóch tekstów, indeksów, do których jest konwertowany pierwszy tekst.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Indeks przypisany do każdego tokena:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
UWAGA: słowo „the” ma miejsce najczęściej, więc wartość indeksu 1 jest który jest mu przypisany. Niektóre biblioteki rezerwują indeks 0 dla nieznanych tokenów, tak jak tę sprawę.
Kolejność indeksów tokenów:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Dostępne są 2 opcje wektoryzacji sekwencji tokenów:
Kodowanie jedno- gorące: sekwencje są przedstawiane za pomocą wektorów słów w zapisie n- przestrzeń wymiarowa, gdzie n = rozmiar słownika. Ta reprezentacja sprawdza się tokenizowana jako znaki, więc mamy do czynienia z małą ilością słownictwa. Podczas tokenizacji jako słów słownictwo zwykle zawiera dziesiątki tysiące tokenów, co czyni je bardzo rozproszonymi i niewydajnymi. Przykład:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Wektory dystrybucyjne słów: słowa mają powiązane z nimi znaczenie. W rezultacie może reprezentować tokeny słów w gęstej przestrzeni wektorowej (ok. kilkuset liczb rzeczywistych), gdzie lokalizacja i odległość między słowami wskazują na ich podobieństwa. semantycznie (zobacz Rys. 7). Ta reprezentacja jest nazywana wektorów dystrybucyjnych słów.
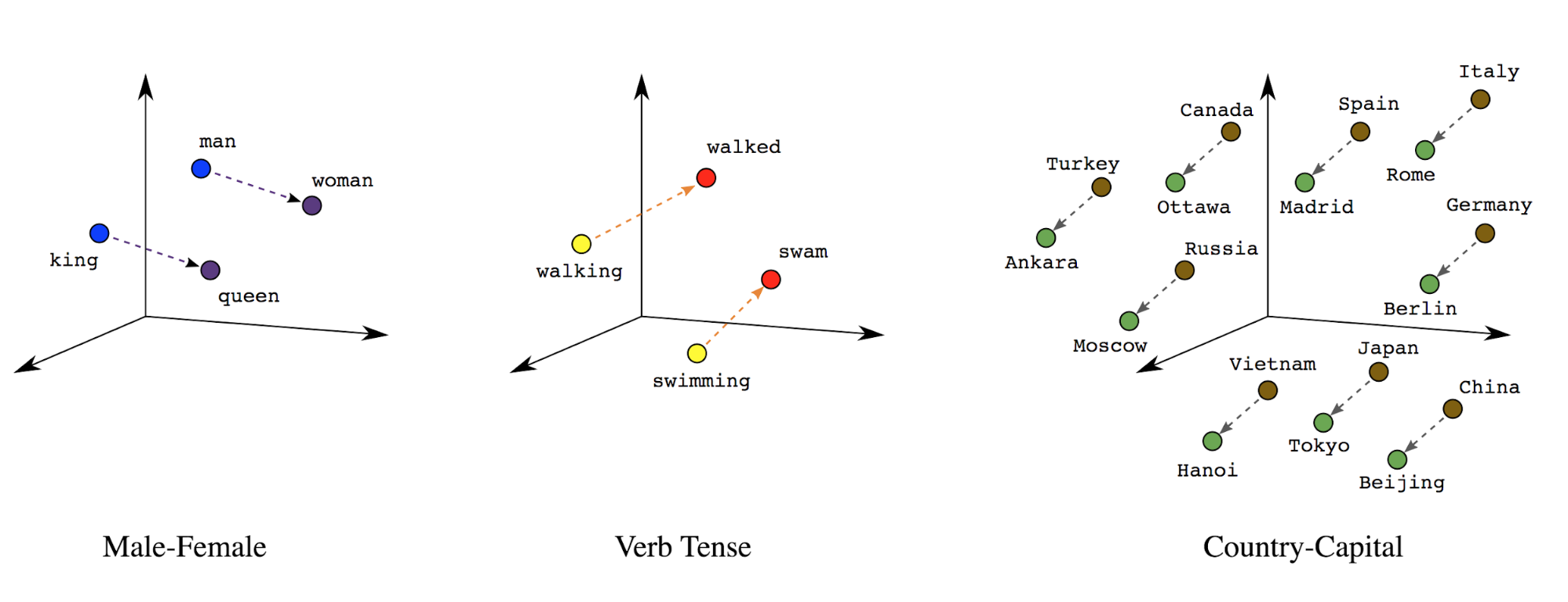
Rysunek 7. Wektory dystrybucyjne słów
Modele sekwencji często mają taką warstwę wektorową jako pierwszą warstwę. Ten warstwa uczy się przekształcać sekwencje indeksu słów w wektory dystrybucyjne słów podczas procesu trenowania, tak aby każdy indeks słów został mapowany na gęsty wektor rzeczywiste wartości reprezentujące lokalizację słowa w przestrzeni semantycznej (patrz Rysunek 8).
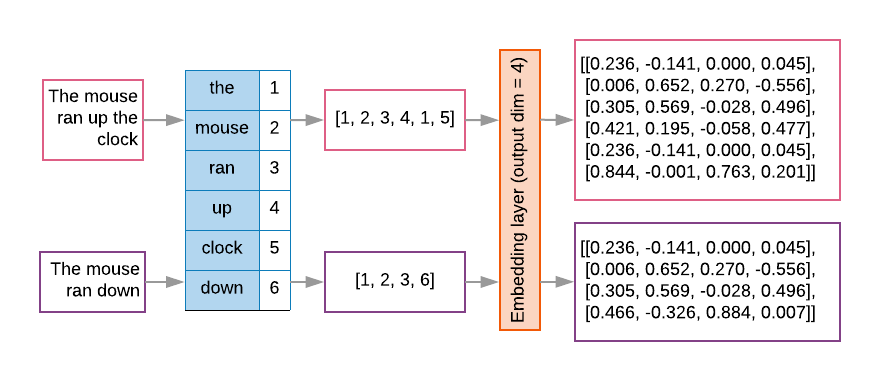
Rysunek 8. Warstwa osadzania
Wybór funkcji
Nie wszystkie słowa z naszych danych są uwzględniane w prognozach dotyczących etykiet. Możemy zoptymalizować nasze uczenia się przez odrzucanie rzadkich lub nieistotnych słów z naszego słownika. W Zauważamy, że przy najczęściej używanych 20 000 funkcji wystarczająca. Odnosi się to również do modeli n-gramów (zobacz Rys. 6).
Podsumujmy wszystkie powyższe kroki w ramach wektoryzacji sekwencyjnej. ten kod wykonuje te zadania:
- Tokenizacja tekstów w słowa
- Tworzy słownictwo za pomocą 20 tys. najpopularniejszych tokenów
- Konwertuje tokeny na wektory sekwencji
- Pasuje sekwencje do stałej długości sekwencji
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Wektoryzacja etykiet
Omówiliśmy sposób konwertowania przykładowych danych tekstowych na wektory liczbowe. Podobny proces
musi zostać zastosowany do etykiet. Możemy po prostu konwertować etykiety na wartości w zakresie
[0, num_classes - 1] Jeśli na przykład są 3 zajęcia, których możemy użyć
reprezentujące je wartości 0, 1 i 2. Wewnętrznie sieć będzie korzystać z trybów „jedno-gorących”
wektory reprezentujące te wartości (aby uniknąć wnioskowania nieprawidłowej zależności,
między etykietami). Ta reprezentacja zależy od funkcji utraty i ostatniego argumentu
funkcję aktywacji warstwy, używaną w naszej sieci neuronowej. Dowiesz się więcej o
w następnej sekcji.