Antes de ingresar nuestros datos a un modelo, se deben transformar a un formato que el modelo puede comprender.
Primero, las muestras de datos que recopilamos pueden estar en un orden específico. Nosotros no queremos que ninguna información asociada con el orden de las muestras influya la relación entre los textos y las etiquetas. Por ejemplo, si un conjunto de datos está ordenado por clase y luego se divide en conjuntos de entrenamiento/validación, estos conjuntos representativos de la distribución general de los datos.
Una práctica recomendada simple para garantizar que el modelo no se vea afectado por el orden de los datos es redistribuye los datos antes de hacer cualquier otra cosa. Si tus datos ya están en conjuntos de entrenamiento y validación, asegúrate de transformar tu configuración de la misma forma en que transformas los datos de entrenamiento. Si aún no tienes conjuntos separados de entrenamiento y validación, puedes dividir las muestras Shuffle; se suele usar el 80% de las muestras para entrenamiento y el 20% validación.
En segundo lugar, los algoritmos de aprendizaje automático toman números como entradas. Esto significa que deberá convertir los textos en vectores numéricos. Hay dos pasos para este proceso:
Asignación de token: Divide los textos en palabras o subtextos más pequeños, lo que permiten una buena generalización de la relación entre los textos y las etiquetas. Esto determina el “vocabulario” del conjunto de datos (conjunto de tokens únicos presentes en los datos).
Vectorización: Define una buena medida numérica para caracterizarlas los textos.
Veamos cómo realizar estos dos pasos tanto para los vectores de n-grama como para las secuencias y cómo optimizar las representaciones vectoriales usando atributos de selección y normalización.
Vectores n-grama [Opción A]
En los párrafos siguientes, veremos cómo realizar la asignación de token y vectorización para modelos n-grama. También veremos cómo optimizar la n- de gramo con técnicas de normalización y selección de atributos.
En un vector de n-grama, el texto se representa como una colección de n-gramas únicos:
grupos de tokens n adyacentes (por lo general, palabras). Considera el texto The mouse ran
up the clock. Aquí:
- La palabra unigramas (n = 1) es
['the', 'mouse', 'ran', 'up', 'clock']. - La palabra bigramas (n = 2) son
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - Y así sucesivamente.
Asignación de token
Hemos descubierto que la asignación de token en unigramas + bigramas proporciona la exactitud, con menos tiempo de procesamiento.
Vectorización
Una vez que dividimos las muestras de texto en n-gramas, debemos convertir esos n-gramas en vectores numéricos que nuestros modelos de aprendizaje automático pueden procesar. El ejemplo a continuación, se muestran los índices asignados a los unigramas y bigramas generados para dos los textos.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Una vez que se asignan los índices a los n-gramas, generalmente vectorizamos usando uno de las siguientes opciones.
Codificación one-hot: Cada texto de ejemplo se representa como un vector que indica la presencia o ausencia de un token en el texto.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Codificación de recuento: Cada texto de muestra se representa como un vector que indica la
recuento de un token en el texto. Ten en cuenta que el elemento que corresponde al
unigram “el” ahora se representa como 2 porque la palabra "the"
aparezca dos veces en el texto.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Codificación tf-idf: el problema con los dos enfoques anteriores es que las palabras comunes que ocurren en situaciones frecuencias en todos los documentos (es decir, palabras que no son particularmente exclusivas de las muestras de texto del conjunto de datos) no se penalizan. Por ejemplo, palabras como “a” ocurrirá con mucha frecuencia en todos los textos. Por lo tanto, un recuento de tokens más alto para “el” que para otras palabras más significativas no es muy útil.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Consulta TfidfTransformer de scikit-learn).
Existen muchas otras representaciones vectoriales, pero las tres anteriores son las de uso general.
Observamos que la codificación tf-idf es apenas mejor que las otras dos en términos de precisión (en promedio: entre un 0.25% y un 15% más) y recomendamos usar este método para vectorizar n-gramas. Sin embargo, ten en cuenta que ocupa más memoria (ya que usa la representación de punto flotante) y tarda más tiempo en procesarse, especialmente para conjuntos de datos grandes (en algunos casos, puede tardar el doble).
Selección de los atributos
Cuando convertimos todos los textos de un conjunto de datos en tokens de uni+bigram de palabras, pueden terminar con decenas de miles de tokens. No todos estos tokens o atributos para la predicción de etiquetas. Podemos descartar ciertos tokens, por ejemplo aquellas que ocurren muy rara vez en el conjunto de datos. También podemos medir la importancia de los atributos (cuánto contribuye cada token a las predicciones de etiquetas) solo incluyen los tokens más informativos.
Hay muchas funciones estadísticas que toman atributos y el valor correspondiente las etiquetas y muestra la puntuación de importancia de los atributos. Dos funciones de uso general son f_classif y chi2. Nuestro experimentos muestran que ambas funciones tienen el mismo rendimiento.
Más importante aún, vimos que la precisión alcanza un máximo de 20,000 atributos en muchos de Google Cloud (consulta la Figura 6). Agregar más atributos que superen este umbral contribuye muy poco y, a veces, incluso lleva a sobreajuste y degrada el rendimiento.

Figura 6: Funciones de Top K frente a la exactitud. En todos los conjuntos de datos, la exactitud se estanca en los 20,000 atributos principales.
Normalización
La normalización convierte todos los valores de atributos o muestras en valores pequeños y similares. Esto simplifica la convergencia del descenso de gradientes en los algoritmos de aprendizaje. De qué vimos que la normalización durante el procesamiento previo de los datos no parece aportar mucho el valor en los problemas de clasificación de textos; te recomendamos que omitas este paso.
El siguiente código reúne todos los pasos anteriores:
- Asignar tokens a muestras de texto en uni+bigramas de palabras
- Vectorizar con la codificación tf-idf
- Descartando los 20,000 atributos principales del vector de tokens para seleccionar únicamente tokens que aparecen menos de 2 veces y usan f_classif para calcular el atributo importancia.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
Con la representación del vector n-grama, descartamos mucha información sobre la palabra orden y gramática (en el mejor de los casos, podemos mantener información parcial sobre el orden cuando n > 1). Esto se denomina enfoque de bolsa de palabras. Esta representación se usa junto con modelos que no tienen en cuenta el orden, como regresión logística, perceptrones multicapa, máquinas de boosting de gradientes, máquinas de vectores de soporte.
Vectores de secuencia [opción B]
En los párrafos siguientes, veremos cómo realizar la asignación de token y vectorización para modelos de secuencia. También veremos cómo podemos optimizar el de secuencias con técnicas de normalización y selección de atributos.
En algunas muestras de texto, el orden de las palabras es fundamental para el significado del texto. Para ejemplo, las oraciones "Solía odiar mi viaje diario. Mi nueva bicicleta cambió eso completamente” se puede entender solo cuando se lee en orden. Modelos como CNN o RNN deducir el significado del orden de las palabras en una muestra. Para estos modelos, representar el texto como una secuencia de tokens, preservando el orden.
Asignación de token
El texto puede representarse como una secuencia de caracteres o una secuencia de palabras. Descubrimos que usar la representación a nivel de palabra proporciona una mejor rendimiento que los tokens de caracteres. Esta es también la norma general seguido del sector. El uso de tokens de caracteres tiene sentido solo si los textos tienen muchos de errores tipográficos, que no suele ser el caso.
Vectorización
Una vez que hayamos convertido las muestras de texto en secuencias de palabras, debemos convertir estas secuencias en vectores numéricos. En el siguiente ejemplo, se muestran los índices se asignan a los unigramas generados para dos textos y, luego, la secuencia de tokens los índices a los que se convierte el primer texto.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Índice asignado para cada token:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
NOTA: La palabra “el” se produce con mayor frecuencia, por lo que el valor de índice de 1 es que se le asignaron. Algunas bibliotecas reservan el índice 0 para tokens desconocidos, como este caso.
Secuencia de índices de tokens:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Hay dos opciones disponibles para vectorizar las secuencias de token:
Codificación one-hot: las secuencias se representan con vectores de palabras en n- espacio dimensional, donde n = tamaño del vocabulario. Esta representación funciona muy bien cuando asignamos tokens como caracteres y, por lo tanto, el vocabulario es pequeño. Cuando asignamos tokens como palabras, el vocabulario suele tener decenas de miles de tokens, lo que hace que los vectores one-hot sean muy dispersos e ineficientes. Ejemplo:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Incorporaciones de palabras: Las palabras tienen significados asociados. Como resultado, puede representar tokens de palabras en un espacio vectorial denso (aproximadamente unos pocos cientos de números reales), donde la ubicación y la distancia entre las palabras indica qué tan similares son semánticamente (consulta la figura 7). Esta representación se denomina incorporaciones de palabras.
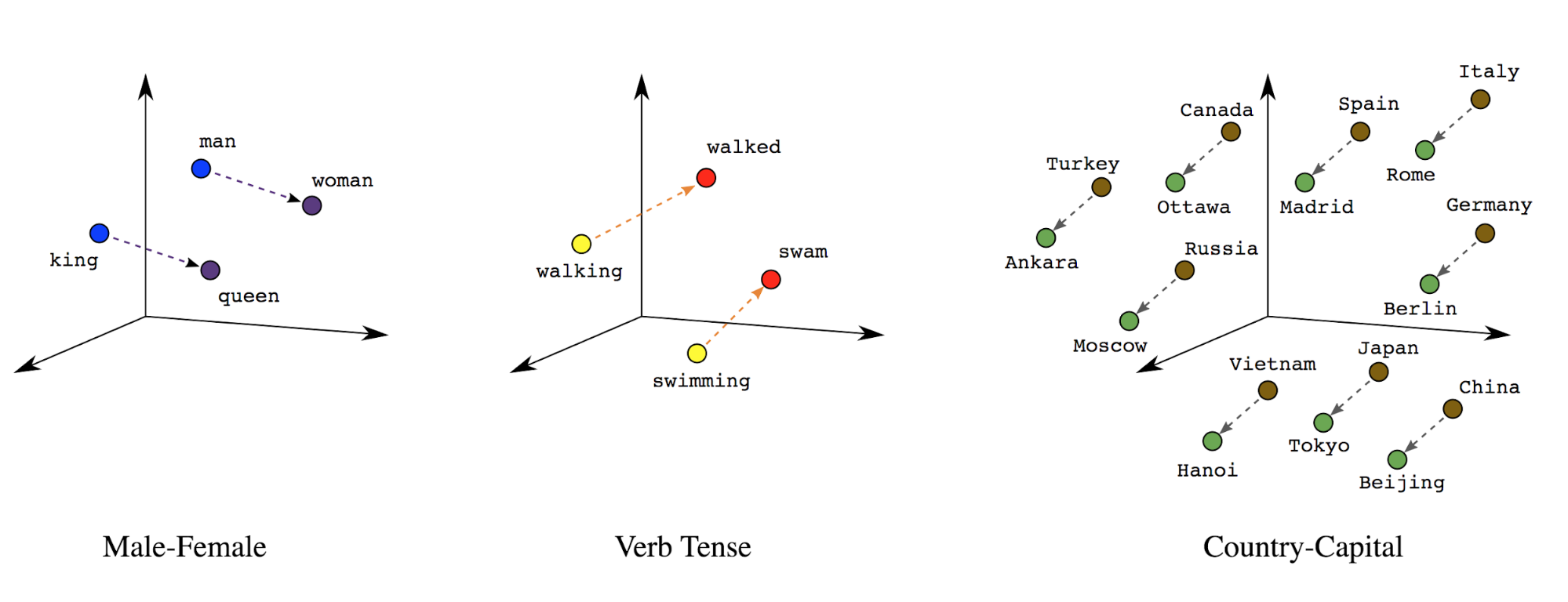
Figura 7: Incorporaciones de palabras
Los modelos de secuencias suelen tener una capa de incorporación de este tipo como primera capa. Esta aprende a convertir secuencias de índices de palabras en vectores de incorporación de palabras durante la de entrenamiento, de modo que cada índice de palabra se asigne a un vector denso de valores reales que representen la ubicación de esa palabra en el espacio semántico (consulta la figura 8).
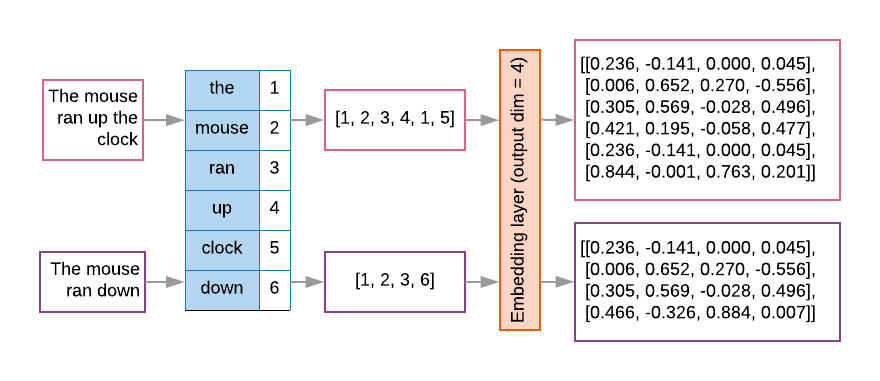
Figura 8: Capa de incorporación
Selección de los atributos
No todas las palabras de nuestros datos contribuyen a las predicciones de etiquetas. Podemos optimizar nuestro descartando palabras raras o irrelevantes de nuestro vocabulario. En Observamos que usar los 20,000 atributos más frecuentes suele ser suficientes. Esto también se aplica a los modelos n-grama (consulta la figura 6).
Juntemos todos los pasos anteriores en la vectorización de secuencias. El siguiente código realiza estas tareas:
- Convierte los textos en tokens de palabras
- Crea un vocabulario con los 20,000 tokens principales
- Convierte los tokens en vectores de secuencia
- Rellena las secuencias a una longitud de secuencia fija.
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Vectorización de etiquetas
Vimos cómo convertir datos de texto de muestra en vectores numéricos. Un proceso similar
debe aplicarse a las etiquetas. Simplemente podemos convertir las etiquetas en valores dentro del rango
[0, num_classes - 1] Por ejemplo, si hay 3 clases, podemos usar
con los valores 0, 1 y 2 para representarlos. A nivel interno, la red usará one-hot
vectores para representar estos valores (para evitar inferir una relación incorrecta
entre etiquetas). Esta representación depende de la función de pérdida y de la
función de activación de capas que usamos en nuestra red neuronal. Aprenderemos más sobre
estas opciones en la siguiente sección.