在将数据馈送给模型之前,需要先将数据转换为 模型可以理解的内容。
首先,我们收集的数据样本可能会按特定顺序排列。我们负责 不希望与样本顺序相关的任何信息影响 文本和标签之间的关系。例如,如果某个数据集已排序, 然后拆分为训练集/验证集, 代表数据的整体分布情况。
要确保模型不受数据顺序影响,一个简单的最佳实践是 务必在执行任何其他操作之前重排数据。如果您的数据已经 拆分为训练集和验证集,请务必将验证 与转换训练数据一样。如果您还没有 将训练集和验证集分开, 随机播放;通常需要将 80% 的样本用于训练,而将 20% 用于训练 验证。
其次,机器学习算法接受数字作为输入。这意味着 需要将文本转换为数值向量。有两个步骤 此流程:
词元化:将文本拆分为单词或更小的辅助文本, 能够很好地概括文本与标签之间的关系。 这决定了数据集的“词汇表”( 数据)。
矢量化:定义一个很好的数值度量来描述这些元素的特征 文本。
我们来看看如何针对 N 元语法向量和序列执行这两个步骤 以及如何使用特征值优化向量表示 选择和归一化方法。
N 元语法向量 [选项 A]
在后续段落中,我们将了解如何进行标记化, 用于 N 元语法模型的矢量化。我们还会介绍如何优化 使用特征选择和归一化技术的图表表示法。
在 N 元语法矢量中,文本表示为唯一 n 元语法的集合:
一组 n 个相邻词元(通常为单词)。请考虑文本 The mouse ran
up the clock。在这里:
- 一元语法 (n = 1) 是
['the', 'mouse', 'ran', 'up', 'clock']。 - 二元语法 (n = 2) 是
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - 等等。
标记化
我们发现,将词元化为一元语法 + 二元语法 同时减少计算时间。
矢量化
将文本样本拆分为 N 元语法后,我们需要将这些 n 元语法转换为 转换为可供我们的机器学习模型处理的数值向量。示例 下面显示了为二元语法生成的一元语法和二元语法的指定索引, 文本。
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
将索引分配给 N 元语法后,我们通常会使用 以下选项
独热编码:每个样本文本表示为一个向量,表示 文本中是否存在词法单元。
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
计数编码:每个样本文本都表示为一个向量,指示
词元数量。请注意,与
一元语法“the”现在表示为 2,因为单词“the”
在文本中出现两次。
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf 编码:问题 与上述两种方法相比, 出现频率(即,对某些语言没有特别独特的字词) 数据集中的文本样本)。例如,“a” 会非常频繁地出现在所有文本中。因此,“the”的词元数量 对其他更有意义的字词进行搜索并不是很有用。
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(请参阅 Scikit-learn TfidfTransformer)
还有许多其他向量表示,但前三种表示 最常用的类别
我们发现,在 tf-idf 编码中, (平均提高 0.25-15%),建议使用此方法 用于向量化 N 元语法。不过请注意,它占用的内存更多 使用浮点表示法),并且需要更多时间进行计算, 尤其是对于大型数据集(在某些情况下可能需要花费两倍的时间)。
特征选择
当我们将数据集中的所有文本转换为单词“Uni+bigram”词元时, 最终可能会有成千上万个词元。并非所有这些令牌/功能 有助于标签预测。我们可以丢弃某些词元, 那些在数据集中极少出现的概率。我们还可以测量 特征重要性(每个词元对标签预测的影响程度),以及 仅包含信息最丰富的词元。
有许多统计函数接受特征, 并输出特征重要性得分。两个常用函数是 f_classif 和 chi2。我们的 实验表明,这两个函数的效果一样好。
更重要的是,我们看到许多模型准确率在 20,000 左右达到 数据集(参见图 6)。在超过此阈值的情况下添加更多特征有助于 有时甚至会导致 过拟合 并降低性能
<ph type="x-smartling-placeholder">
图 6:Top K 特征与准确率。在所有数据集中,准确率达到前 2 万名左右。
规范化
归一化会将所有特征/样本值转换为较小的相似值。 这简化了学习算法中的梯度下降法收敛。来源 数据预处理期间的归一化似乎并不会 值;建议您跳过此步骤
以下代码整合了上述所有步骤:
- 将文本样本词元化为单词 uni+bigrams,
- 使用 tf-idf 编码向量化,
- 舍弃词元矢量,仅选择前 20,000 个特征 出现少于 2 次的词元,并使用 f_classif 计算特征 重要性
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
使用 N 元语法向量表示时,我们会舍弃关于字词的大量信息, 语法和语法(我们最多只能保留一些部分排序信息) 当 n >1)。这称为词袋方法。该表示法用于 与不考虑排序因素的模型结合使用,例如 逻辑回归、多层感知机、梯度提升机 支持向量机。
序列向量 [选项 B]
在后续段落中,我们将了解如何进行标记化, 向量化序列模型。我们还会介绍如何优化 序列表示方法。
对于某些文本样本,字词顺序对于文本的含义至关重要。对于 例如,“我曾经讨厌通勤。我的新自行车改变了这一点 只有按顺序阅读才能理解。CNN/RNN 等模型 可以根据样本中字词的顺序推断出含义。对于这些模型, 将文本表示为一个词元序列,并保持顺序。
标记化
文本可以表示为一个字符序列, 字词。我们发现,如果使用字词级表示法, 性能优于字符词元。这也是需要改进的 然后是行业仅当文本很多时,使用字符标记才有意义 通常不会出现这种情况
矢量化
将文本样本转换为字词序列后,我们需要 将这些序列转化为数值向量。以下示例展示了 然后向两个文本生成的 1-gram 分别分配词元, 第一个文本要转换后的索引。
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
为每个词元分配的索引:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
请注意:字词“the”出现频率最高,因此索引值 1 为 资源。有些库会为未知令牌预留索引 0, 这里就是这种情况。
词元索引序列:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
有两种方法可用于对词元序列进行矢量化:
独热编码:序列使用 n- 其中 n = 词汇量。这种呈现效果很好 因此词汇量很小。 当我们将词元化为单词时,词汇表通常会包含数十个 词元,这使得独热矢量非常稀疏且效率低下。 示例:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
字词嵌入:字词具有关联的含义。因此, 可以表示密集向量空间(约几百个实数)中的字词词元, 其中,字词之间的位置和距离表示字词之间的相似度 (参见图 7)。这种表示法称为 词嵌入。
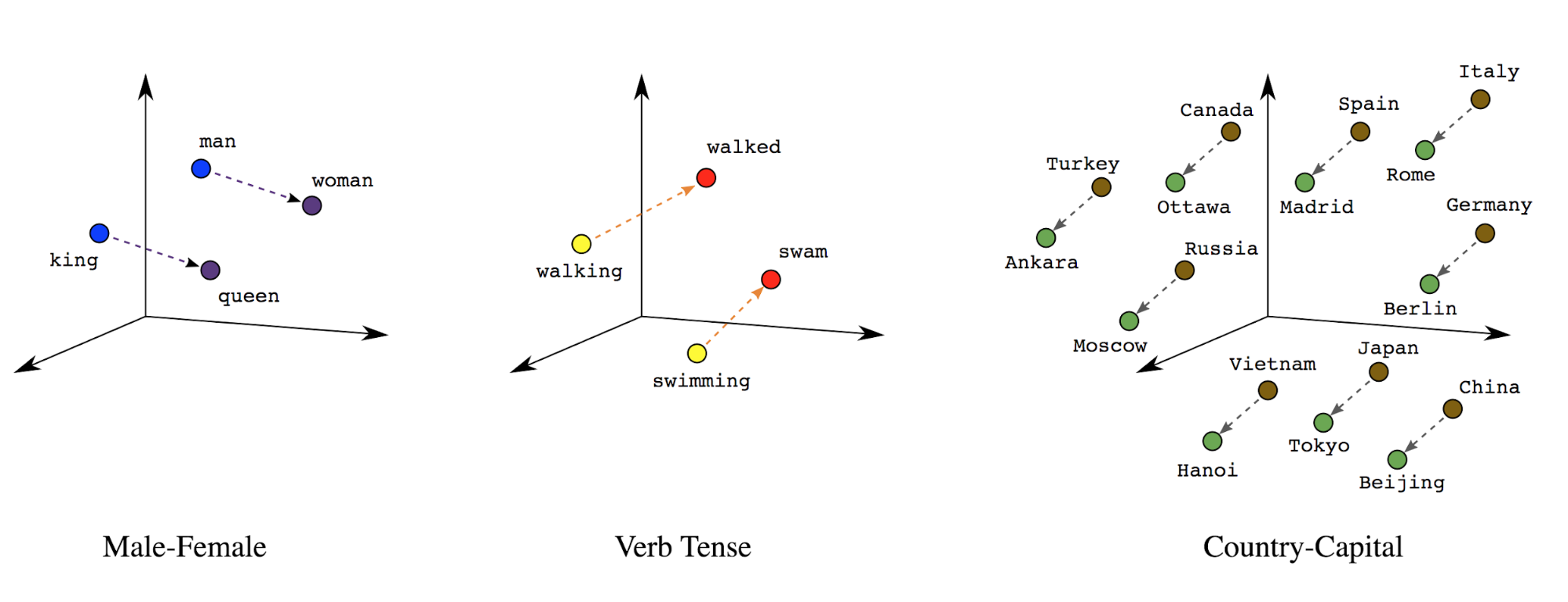
图 7:字词嵌入
序列模型通常将这种嵌入层用作其第一层。这个 层会学习将字词索引序列转换为字词嵌入向量, 将每个字词索引映射到一个密集向量, 表示字词在语义空间中的位置的实值(参见图 8)。
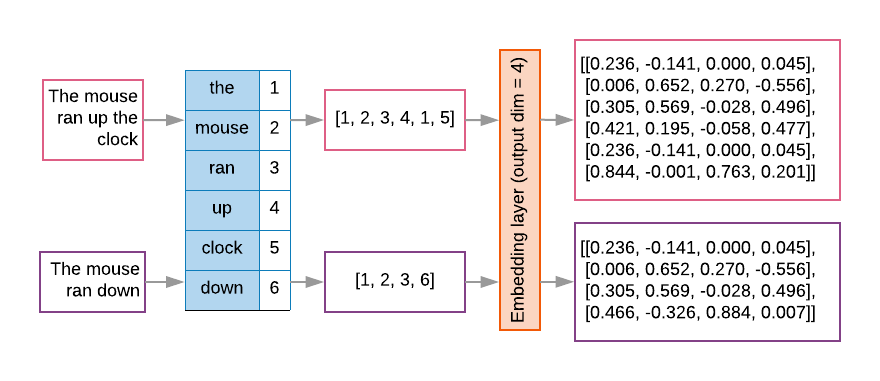
图 8:嵌入层
特征选择
并非数据中的所有字词都参与标签预测。我们可以优化 从词汇中剔除罕见或不相关的关键字。在 但我们发现,使用频率最高的 20,000 个特征 。这也适用于 N 元语法模型(参见图 6)。
我们把上述所有步骤放在序列矢量化上。通过 以下代码会执行这些任务:
- 将文本标记化为字词
- 使用前 20,000 个词元创建词汇
- 将词元转换为序列向量
- 将序列填充为固定的序列长度
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
标签矢量化
我们了解了如何将样本文本数据转换为数值向量。类似的流程
必须应用到标签。我们可以直接将标签转换为范围内的值
[0, num_classes - 1]。例如,如果有 3 个类,我们只需使用
值 0、1 和 2 来表示它们。在内部,网络将使用独热
用来表示这些值的向量(以避免推断出不正确的关系)
)。这种表示法取决于损失函数和最后一个
层激活函数。在本专精课程的稍后部分
我们将在下一节介绍这些内容