ก่อนที่จะส่งข้อมูลไปยังโมเดลได้ คุณจะต้องเปลี่ยนรูปแบบข้อมูลให้เป็นรูปแบบ โมเดลจะเข้าใจได้
อย่างแรก ตัวอย่างข้อมูลที่เรารวบรวมอาจเรียงลำดับตามที่ระบุ เราเอง ไม่ต้องการให้ข้อมูลที่เกี่ยวข้องกับการจัดลำดับตัวอย่างมีอิทธิพล ความสัมพันธ์ระหว่างข้อความและป้ายกำกับ เช่น หากจัดเรียงชุดข้อมูล ตามคลาส และจากนั้นจะถูกแบ่งออกเป็นชุดการฝึก/การตรวจสอบ ชุดเหล่านี้จะไม่ เพื่อการกระจายข้อมูลโดยรวม
แนวทางปฏิบัติแนะนำง่ายๆ ที่จะทำให้มั่นใจได้ว่าโมเดลจะไม่ได้รับผลกระทบจากลำดับข้อมูลคือการ จะสับเปลี่ยนข้อมูลทุกครั้งก่อนที่จะทำอย่างอื่น หากมีข้อมูลอยู่แล้ว แยกเป็นชุดการฝึกและการตรวจสอบ อย่าลืมเปลี่ยนการตรวจสอบความถูกต้อง ข้อมูลในลักษณะเดียวกับที่คุณแปลงข้อมูลการฝึก หากคุณยังไม่มี ชุดการฝึกและการตรวจสอบ แยกกันได้ คุณสามารถแยกกลุ่มตัวอย่าง การสุ่ม; โดยปกติแล้วจะใช้ 80% ของตัวอย่างสำหรับการฝึกและ 20% สำหรับ การตรวจสอบความถูกต้อง
ประการที่ 2 อัลกอริทึมแมชชีนเลิร์นนิงจะนำตัวเลขเป็นอินพุต ซึ่งหมายความว่าเรา จะต้องแปลงข้อความเป็นเวกเตอร์ตัวเลข มี 2 ขั้นตอนในการ ขั้นตอนนี้
การแปลงข้อมูลเป็นโทเค็น: แบ่งข้อความออกเป็นคำหรือข้อความย่อยที่จะ ทำให้เข้าใจความสัมพันธ์ที่ดีระหว่างข้อความและป้ายกำกับได้ ตัวแปรนี้จะเป็นตัวกำหนด "คำศัพท์" ของชุดข้อมูล (ชุดของโทเค็นที่ไม่ซ้ำกันที่อยู่ใน ข้อมูล)
เวกเตอร์: กำหนดการวัดเชิงตัวเลขที่ดีเพื่อระบุลักษณะของสิ่งเหล่านี้ ข้อความ
เรามาดูวิธีทำ 2 ขั้นตอนนี้สำหรับทั้งเวกเตอร์และลำดับ n-gram เวกเตอร์ รวมถึงวิธีเพิ่มประสิทธิภาพการแสดงเวกเตอร์โดยใช้คุณสมบัติ เทคนิคการเลือกและการปรับให้เป็นมาตรฐาน
เวกเตอร์ N-gram [Option A]
ในย่อหน้าต่อๆ ไป เราจะดูวิธีแปลงข้อมูลเป็นโทเค็นและ เวกเตอร์สำหรับโมเดล n-gram นอกจากนี้ เรายังจะกล่าวถึงวิธีการเพิ่มประสิทธิภาพของ การแสดงแกรมโดยใช้การเลือกฟีเจอร์และเทคนิคการปรับให้เป็นมาตรฐาน
ในเวกเตอร์ n-gram ข้อความจะแสดงเป็นชุดของ n-gram ที่ไม่ซ้ำ:
กลุ่มของโทเค็นที่อยู่ติดกัน n รายการ (โดยทั่วไปคือคำ) ลองใช้ข้อความ The mouse ran
up the clock ที่นี่
- คำว่ายูนิแกรม (n = 1) คือ
['the', 'mouse', 'ran', 'up', 'clock'] - คำว่า Bigrams (n = 2) คือ
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - เป็นต้น
การแปลงข้อมูลเป็นโทเค็น
เราพบว่าการแปลงข้อมูลเป็นโทเค็นให้อยู่ในรูปแบบ Word unigrams + Bigrams มีประโยชน์อย่างยิ่ง ความแม่นยำและใช้เวลาประมวลผลน้อยลง
เวกเตอร์
เมื่อเราได้แยกตัวอย่างข้อความออกเป็น n-กรัมแล้ว เราจะต้องเปลี่ยน n-กรัมเหล่านี้ เป็นเวกเตอร์เชิงตัวเลขที่โมเดลแมชชีนเลิร์นนิงของเราประมวลผลได้ ตัวอย่าง ด้านล่างแสดงดัชนีที่กำหนดให้กับยูนิแกรมและ Bigrams ที่สร้างขึ้นสำหรับ ข้อความ
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
เมื่อมีการกำหนดดัชนีให้กับ n-กรัม เรามักจะแปลงข้อมูลเป็นเวกเตอร์โดยใช้ ตัวเลือกต่อไปนี้
การเข้ารหัสแบบ One-hot: ข้อความตัวอย่างทุกข้อความแสดงเป็นเวกเตอร์ที่ระบุ การมีหรือไม่มีโทเค็นในข้อความ
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
การเข้ารหัสการนับ: ข้อความตัวอย่างทุกข้อความจะแสดงเป็นเวกเตอร์ที่ระบุค่า
จำนวนโทเค็นในข้อความ โปรดทราบว่าองค์ประกอบที่สอดคล้องกับ
Unigram "the" แสดงเป็น 2 เนื่องจากคำว่า "the"
ปรากฏขึ้น 2 ครั้งในข้อความ
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
การเข้ารหัส Tf-idf: ปัญหา จากวิธีการ 2 วิธีข้างต้น คือคำทั่วไปที่ปรากฏใน ความถี่ในเอกสารทั้งหมด (เช่น คำที่ไม่ได้เฉพาะเจาะจงกับ ตัวอย่างข้อความในชุดข้อมูล) จะไม่ถูกลงโทษ เช่น คำอย่าง "a" จะเกิดขึ้นบ่อยในข้อความทั้งหมด ดังนั้น จำนวนโทเค็นของ “the” สูงกว่า สำหรับคำที่มีความหมายมากกว่า ไม่ค่อยมีประโยชน์
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(ดู Scikit-learn TfidfTransformer)
มีการนำเสนอเวกเตอร์อื่นๆ อีกจำนวนมาก แต่สามแบบก่อนหน้านี้คือ ใช้กันโดยทั่วไป
เราสังเกตเห็นว่าการเข้ารหัส tf-idf ดีกว่าอีก 2 รหัสเพียงเล็กน้อย ความแม่นยำ (โดยเฉลี่ย: สูงกว่า 0.25-15%) และแนะนำให้ใช้วิธีการนี้ สำหรับเวกเตอร์ของ n-กรัม อย่างไรก็ตาม โปรดทราบว่า URL ดังกล่าวจะใช้หน่วยความจำมากกว่า (เช่น จะใช้การแสดงจุดลอยตัว) และใช้เวลาในการประมวลผลนานกว่า โดยเฉพาะชุดข้อมูลขนาดใหญ่ (อาจใช้เวลานานกว่า 2 เท่าในบางกรณี)
การเลือกฟีเจอร์
เมื่อเราแปลงข้อความทั้งหมดในชุดข้อมูลเป็นโทเค็นของคำว่า uni+bigram อาจมีโทเค็นเป็นหมื่นๆ โทเค็นได้ โทเค็น/ฟีเจอร์เหล่านี้บางรายการเท่านั้น ในการคาดการณ์ป้ายกำกับ เช่น เราจะทิ้งโทเค็นบางรายการได้ ซึ่งเกิดขึ้นน้อยมากในชุดข้อมูล เรายังสามารถวัด ความสำคัญของฟีเจอร์ (แต่ละโทเค็นมีส่วนในการคาดการณ์ป้ายกำกับมากน้อยเพียงใด) และ ใส่เฉพาะโทเค็นที่มีข้อมูลมากที่สุดเท่านั้น
มีฟังก์ชันทางสถิติหลายอย่างที่ใช้คุณสมบัติและฟังก์ชัน ป้ายกำกับ และแสดงคะแนนความสำคัญของฟีเจอร์ ฟังก์ชันที่ใช้กันโดยทั่วไป 2 รายการคือ f_classif และ chi2 จากการทดสอบทั้งหมด แสดงให้เห็นว่าฟังก์ชันทั้งสองนี้มีประสิทธิภาพเท่ากัน
ยิ่งไปกว่านั้น เรายังเห็นว่าความแม่นยำสูงถึง 20,000 จุดสำหรับหลายๆ คน (ดูรูปที่ 6) การเพิ่มฟีเจอร์มากกว่าเกณฑ์นี้นับ น้อยมากและบางครั้งอาจช่วยให้ เกินความเหมาะสม และทำให้ประสิทธิภาพการทำงานลดลง

รูปที่ 6: ฟีเจอร์ K ยอดนิยมเทียบกับความแม่นยำ ข้อมูลจากชุดข้อมูลต่างๆ จะหมายถึงที่ราบสูงความแม่นยำที่มีฟีเจอร์ยอดนิยมประมาณ 20, 000 แห่ง
การปรับให้สอดคล้องตามมาตรฐาน
การปรับให้เป็นมาตรฐานจะแปลงค่าฟีเจอร์/ตัวอย่างทั้งหมดเป็นค่าที่เล็กน้อยและคล้ายกัน ซึ่งจะช่วยลดความซับซ้อนของลู่เข้าที่การไล่ระดับสีลดลงในอัลกอริทึมการเรียนรู้ จากอะไร เราได้เห็นแล้วว่าการปรับให้เป็นมาตรฐานระหว่างการประมวลผลข้อมูลล่วงหน้าไม่ได้เพิ่มอะไรมากนัก ในโจทย์การจัดประเภทข้อความ เราขอแนะนำให้ข้ามขั้นตอนนี้
โค้ดต่อไปนี้จะรวมขั้นตอนด้านบนทั้งหมดไว้ด้วยกัน
- แปลงตัวอย่างข้อความให้เป็นโทเค็นของคำว่า uni+bigram
- เวกเตอร์โดยใช้การเข้ารหัส tf-idf
- เลือกเฉพาะฟีเจอร์ 20,000 อันดับแรกจากเวกเตอร์ของโทเค็นโดยทิ้ง โทเค็นที่ปรากฏน้อยกว่า 2 ครั้ง และใช้ f_classif ในการคำนวณคุณลักษณะ ความสำคัญ
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
เมื่อใช้การแสดงเวกเตอร์ n-gram เราจะทิ้งข้อมูลจำนวนมากเกี่ยวกับคำ ลำดับและไวยากรณ์ (อย่างดีที่สุด เราสามารถเก็บข้อมูลการจัดเรียงบางส่วนไว้ได้บางส่วน เมื่อ n > 1) วิธีนี้เรียกว่าวิธีการแบบถุงคำ ระบบใช้ตัวแทนนี้ ร่วมกับรูปแบบที่ไม่ได้คำนึงถึงการจัดลำดับ เช่น การถดถอยแบบโลจิสติกส์ การรับรู้หลายเลเยอร์ เครื่องเพิ่มระดับไล่ระดับสี สนับสนุนเครื่องเวกเตอร์
เวกเตอร์ของลำดับ [ตัวเลือก B]
ในย่อหน้าต่อๆ ไป เราจะดูวิธีแปลงข้อมูลเป็นโทเค็นและ เวกเตอร์สำหรับโมเดลลำดับ นอกจากนี้เราจะพูดถึงวิธีเพิ่มประสิทธิภาพ ตามลำดับการแสดงโดยใช้การเลือกฟีเจอร์และเทคนิคการปรับให้สอดคล้องตามมาตรฐาน
สำหรับตัวอย่างข้อความบางรายการ ลำดับคำมีความสำคัญอย่างยิ่งต่อความหมายของข้อความ สำหรับ เช่น ประโยคที่ว่า "ฉันเคยเกลียดการเดินทางของฉัน จักรยานคันใหม่เปลี่ยนการตั้งค่านั้น ทั้งหมด" จะเข้าใจได้ก็ต่อเมื่ออ่านตามลำดับ โมเดล เช่น CNN/RNN สามารถอนุมานความหมายจากลำดับของคำในตัวอย่างได้ สำหรับโมเดลเหล่านี้ เรา แสดงข้อความเป็นลำดับของโทเค็นโดยรักษาลำดับไว้
การแปลงข้อมูลเป็นโทเค็น
ข้อความสามารถแสดงเป็นลำดับอักขระ หรือลำดับของอักขระ คำ เราพบว่าการใช้การนำเสนอข้อมูลระดับคำจะให้ ประสิทธิภาพมากกว่าโทเค็นอักขระ นี่เป็นบรรทัดฐานทั่วไปที่ ตามด้วยอุตสาหกรรม การใช้โทเค็นอักขระจะเหมาะสมก็ต่อเมื่อข้อความมีจำนวนมาก คำผิด ซึ่งปกติแล้วไม่ได้เกิดขึ้น
เวกเตอร์
เมื่อเราแปลงตัวอย่างข้อความของเราเป็นลำดับคำแล้ว เราจะต้องเปลี่ยน ลำดับเหล่านี้เป็นเวกเตอร์ตัวเลข ตัวอย่างด้านล่างแสดงดัชนี ถูกกำหนดให้กับยูนิแกรมที่สร้างขึ้นสำหรับ 2 ข้อความ จากนั้นจะตามด้วยลำดับของโทเค็น ดัชนีที่ข้อความแรกถูกแปลง
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
ดัชนีที่กำหนดสำหรับทุกโทเค็น:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
หมายเหตุ: คำว่า "the" เกิดขึ้นบ่อยที่สุด ดังนั้นค่าดัชนี 1 คือ ที่มอบหมายให้ ไลบรารีบางแห่งจองดัชนีเป็น 0 สำหรับโทเค็นที่ไม่รู้จัก เช่นเดียวกับ ที่นี่
ลำดับดัชนีโทเค็น
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
มี 2 ตัวเลือกที่ใช้ในการกำหนดลำดับโทเค็นเป็นเวกเตอร์ ดังนี้
การเข้ารหัสแบบ One-hot: ลำดับจะแสดงโดยใช้เวกเตอร์ของคำในรูปแบบ n- พื้นที่มิติโดยที่ n = ขนาดของคำศัพท์ การนำเสนอนี้ได้ผลดี เมื่อเราแปลงข้อมูลเป็นตัวละคร คำศัพท์จึงน้อยมาก เมื่อเราเปลี่ยนคำศัพท์เป็นคำ คำศัพท์มักประกอบด้วยคำหลายสิบคำ หลายพันโทเค็น ทำให้เวกเตอร์ร้อนๆ ไม่ชัดเจนและไม่มีประสิทธิภาพ ตัวอย่าง
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
การฝังคำ: คำต่างๆ มีความหมายเชื่อมโยงอยู่ ด้วยเหตุนี้ เราจึง สามารถแสดงโทเค็นคำในพื้นที่เวกเตอร์ที่หนาแน่น (จำนวนจริงประมาณ 200-30) โดยที่ตำแหน่งและระยะห่างระหว่างคำต่างๆ แสดงให้เห็นว่าคำเหล่านั้นมีความคล้ายคลึงกันเพียงใด ตามความหมาย (ดูรูปที่ 7) การรับรองนี้เรียกว่า การฝังคำ
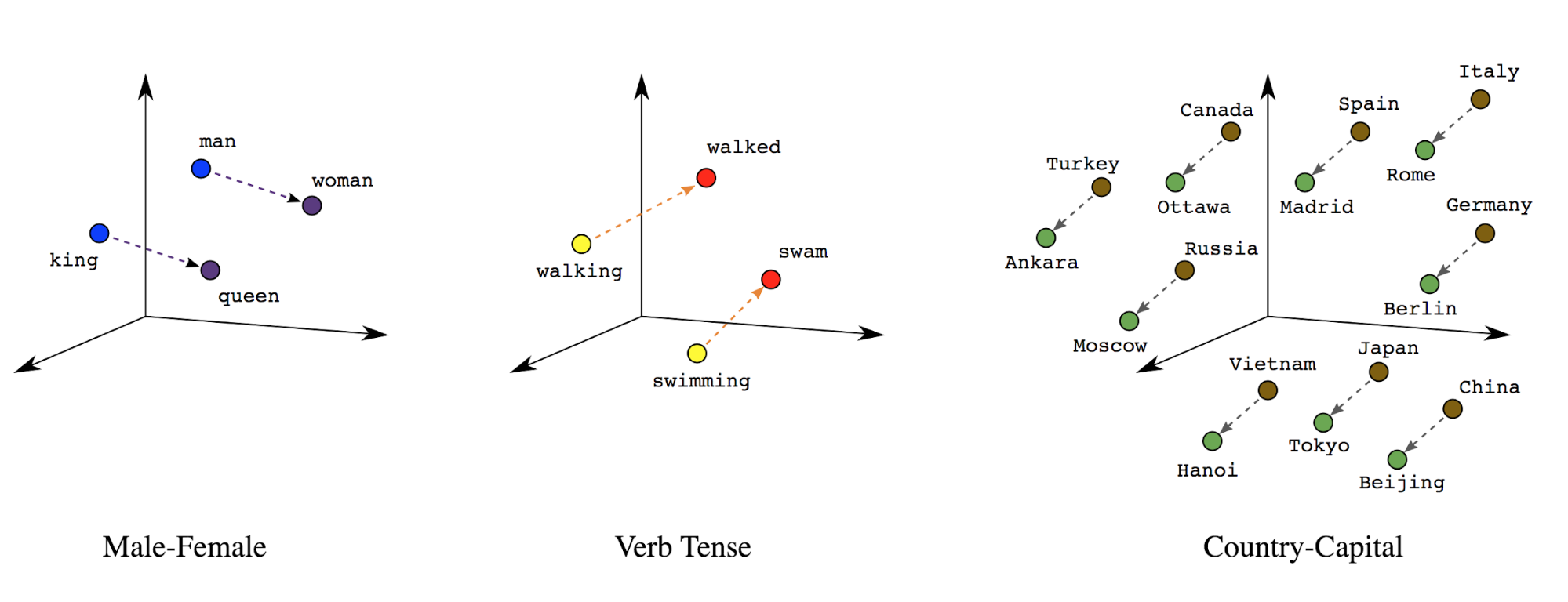
รูปที่ 7: การฝังคำ
โมเดลลำดับมักมีเลเยอร์ที่ฝังเป็นเลเยอร์แรก ช่วงเวลานี้ เรียนรู้ที่จะเปลี่ยนลำดับดัชนีคำเป็นเวกเตอร์การฝังคำระหว่าง ดัชนีคำแต่ละคำ ถูกจับคู่กับเวกเตอร์ที่หนาแน่นของ ค่าจริงที่แสดงตําแหน่งของคําในเชิงอรรถศาสตร์ (ดูรูปที่ 8)
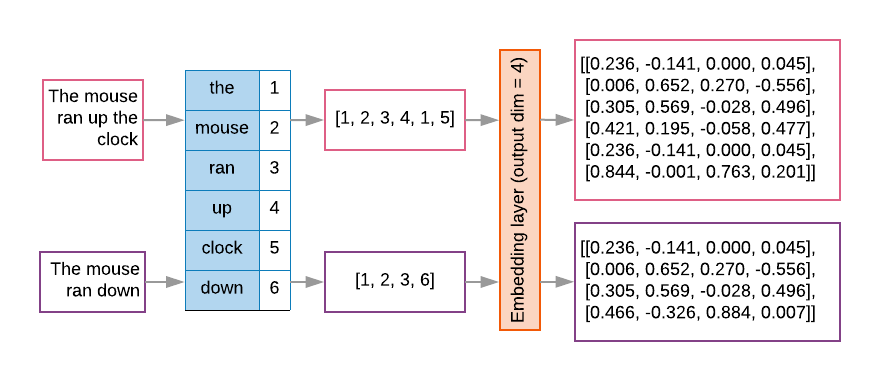
รูปที่ 8: การฝังเลเยอร์
การเลือกฟีเจอร์
คำบางคำในข้อมูลของเราไม่ได้มีผลต่อการคาดการณ์ป้ายกำกับ เราสามารถเพิ่มประสิทธิภาพ กระบวนการเรียนรู้โดยตัดคำที่หายากหรือไม่เกี่ยวข้องออกจากคำศัพท์ของเรา ใน เราสังเกตเห็นว่าการใช้คุณลักษณะ บ่อยที่สุด 20,000 รายการนั้น เพียงพอ กรณีนี้ก็ใช้ได้กับโมเดล n-gram ด้วยเช่นกัน (ดูรูปที่ 6)
มาลองพิจารณาขั้นตอนด้านบนทั้งหมดในการทำเวกเตอร์ตามลำดับกัน โค้ดต่อไปนี้ทำงานเหล่านี้:
- แปลงข้อความให้เป็นคำ
- สร้างคำศัพท์โดยใช้โทเค็น 20,000 อันดับแรก
- แปลงโทเค็นเป็นเวกเตอร์ตามลำดับ
- เลื่อนลำดับให้มีความยาวคงที่
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
เวกเตอร์ของป้ายกำกับ
เราได้ดูวิธีแปลงข้อมูลข้อความตัวอย่างเป็นเวกเตอร์ของตัวเลขแล้ว ขั้นตอนที่คล้ายกัน
ต้องนำไปใช้กับป้ายกำกับ เราสามารถแปลงป้ายกำกับเป็นค่าในช่วง
[0, num_classes - 1] เช่น หากมี 3 คลาสที่เราใช้
ค่า 0, 1 และ 2 เพื่อแสดงแทนค่าเหล่านั้น เครือข่ายจะใช้การเชื่อมต่อแบบ One-hot ภายใน
เวกเตอร์เพื่อแสดงค่าเหล่านี้ (เพื่อหลีกเลี่ยงการอนุมานความสัมพันธ์ที่ไม่ถูกต้อง)
ระหว่างป้ายกำกับ) การนำเสนอนี้จะขึ้นอยู่กับฟังก์ชันการสูญเสียข้อมูลและฟังก์ชันสุดท้าย
ฟังก์ชันการเปิดใช้งานเลเยอร์ที่เราใช้ในโครงข่ายระบบประสาทเทียม เราจะเรียนรู้เพิ่มเติมเกี่ยวกับ
เหล่านี้ในหัวข้อถัดไป