قبل إدخال بياناتنا في أحد النماذج، يجب تحويلها إلى تنسيق يمكن للنموذج فهمها.
أولاً، قد تكون عينات البيانات التي جمعناها بترتيب معين. نحن نفعل ذلك لا ترغب في أن تؤثر أي معلومات مرتبطة بترتيب العينات العلاقة بين النصوص والتسميات. على سبيل المثال، إذا تم فرز مجموعة بيانات حسب الفئة ثم تقسيمها إلى مجموعات تدريب/التحقق، فلن يتم يمثل التوزيع العام للبيانات.
ومن أفضل الممارسات البسيطة للتأكد من عدم تأثر النموذج بترتيب البيانات تبديل البيانات دائمًا قبل القيام بأي شيء آخر. إذا كانت بياناتك بالفعل قسمة التحقق إلى مجموعات تدريب وعملية تحقق، فاحرص على تحويل التحقق من الصحة البيانات بالطريقة نفسها التي تحول بها بيانات التدريب. إذا لم يكن لديك بالفعل مجموعات تطبيق وعملية تحقق منفصلة، يمكنك قسمة العينات بعد الترتيب العشوائي من المعتاد استخدام 80٪ من العينات للتدريب و20٪ التحقق من الصحة.
ثانيها، تأخذ خوارزميات التعلم الآلي الأرقام كمدخلات. هذا يعني أننا سوف نحول النصوص إلى متجهات عددية. هناك خطوتان لهذه العملية:
الترميز: لتقسيم النصوص إلى كلمات أو نصوص فرعية أصغر، تتيح تعميمًا جيدًا للعلاقة بين النصوص والتسميات. ويحدد هذا "مفردات" مجموعة البيانات (مجموعة من الرموز المميزة الفريدة الموجودة في البيانات).
الاتجاه: تحديد مقياس رقمي جيد لوصف هذه القيم النصوص.
لنرَ طريقة تنفيذ هاتين الخطوتين لكلٍ من الخطوتَين المتجهة ومتتابعة الغرام المتجهات، وكذلك كيفية تحسين تمثيلات المتجه باستخدام ميزة تقنيات الاختيار والتسوية.
متجهات N-gram [الخيار A]
وفي الفقرات اللاحقة، سنتعرّف على كيفية إنشاء رموز مميّزة الخط المتجه لنماذج ن غرام. كما سنتناول كيف يمكننا تحسين التمثيل الغرامي باستخدام أساليب اختيار الخصائص والتسوية.
في متجه n جرام، يتم تمثيل النص كمجموعة من n جرامات فريدة:
المجموعات المكونة من عدد n من الرموز المميزة المتجاورة (عادةً الكلمات). ضع في الاعتبار النص The mouse ran
up the clock. يمكنك هنا:
- كلمة unigrams (n = 1) هي
['the', 'mouse', 'ran', 'up', 'clock']. - كلمة bigrams (n = 2) هي
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - وما إلى ذلك.
إنشاء رمز مميّز
وقد وجدنا أن إنشاء الرموز المميزة إلى أحادي الألفاظ + كرات كبيرة الحجم يقدم الدقة مع تقليل وقت الحوسبة.
المتّجهات
وبمجرد تقسيم عيناتنا النصية إلى ن جرام، نحتاج إلى تحويل ن جرام إلى متجهات عددية يمكن لنماذج التعلم الآلي معالجتها. المثال الفهارس الخاصة بـ يونيغرام و بيجرامات تم إنشاؤها لاثنين من النصوص.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
بمجرد تعيين الفهارس لمخططات n، نتجه عادةً باستخدام أحد الخيارات التالية.
ترميز واحد فعال: يتم تمثيل كل نموذج نص كمتّجه يشير إلى وجود أو عدم وجود رمز في النص.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
ترميز العد: يتم تمثيل كل نموذج نص كمتّجه يشير إلى
عدد الرمز المميز في النص. لاحظ أن العنصر المتجاوب مع
حرف يونيغرام "الـ" يتم تمثيلها الآن كـ 2 لأن كلمة "الـ"
تظهر مرتين في النص.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
ترميز Tf-idf: المشكلة باستخدام النهجين المذكورين أعلاه هو أن الكلمات الشائعة التي تحدث في عدد مرات الظهور في جميع المستندات (أي الكلمات التي ليست فريدة العينات النصية في مجموعة البيانات). على سبيل المثال، يمكن استخدام كلمات مثل "a". سيحدث بشكل متكرر جدًا في جميع النصوص. وبالتالي، يكون عدد الرموز المميزة لـ "الـ" أعلى من لكلمات أخرى أكثر وضوحًا ليس مفيدًا للغاية.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(راجع مكتبة ساي كيت ليرن TفيدfTransformer)
هناك العديد من تمثيلات المتجه الأخرى، لكن الثلاثة السابقة هي الأكثر استخدامًا.
لاحظنا أن ترميز tf-idf أفضل هامشيًا من الترميزين الآخرين في من حيث الدقة (في المتوسط: أعلى بنسبة من 0.25 إلى 15%)، وننصحك باستخدام هذه الطريقة لتوجيه الـ n جرامات. ومع ذلك، ضع في اعتبارك أنها تشغل مساحة أكبر في الذاكرة (لأن وتستخدم تمثيل النقطة العائمة) وتستغرق وقتًا أطول لحساب خاصة بالنسبة لمجموعات البيانات الكبيرة (يمكن أن يستغرق ضعف المدة في بعض الحالات).
اختيار الميزات
عندما نحول جميع النصوص في مجموعة البيانات إلى رموز أحادية + ثنائية، بعشرات الآلاف من الرموز المميزة. ليس كل هذه الرموز/الميزات في التنبؤ بالتصنيف. حتى نتمكن من إسقاط بعض الرموز المميزة، على سبيل المثال وتلك التي تحدث نادرًا جدًا عبر مجموعة البيانات. يمكننا أيضًا قياس أهمية الميزة (مدى مساهمة كل رمز مميز في تنبؤات التسمية) لا تتضمن سوى الرموز الأكثر إفادة.
هناك العديد من الدوال الإحصائية التي تتخذ ميزات ووظائف وقم بإخراج درجة أهمية الميزة. هناك دالتان شائعتان الاستخدام f_classif و chi2. إنّ التجارب أن كلتا الدالتين تؤديان أداءً جيدًا بنفس القدر.
والأهم من ذلك، رأينا أن الدقة تصل إلى ذروتها عند حوالي 20,000 ميزة للعديد من مجموعات البيانات (راجع الشكل 6). تساهم إضافة المزيد من الميزات التي تتجاوز هذا الحدّ قليلة جدًا وأحيانًا تؤدي إلى فرط التخصيص ويضعف الأداء.

الشكل 6: أهم خصائص التصنيف مقابل الدقة في مجموعات البيانات، لا يتراجع مستوى الدقة عند أكثر من 20 ألف ميزة.
التسوية
تعمل التسوية على تحويل جميع قيم الميزة/العينة إلى قيم صغيرة ومتشابهة. يعمل هذا على تبسيط تقارب انحدار التدرج في خوارزميات التعلم. من أي كما رأينا، لا يبدو أن التسوية أثناء المعالجة المسبقة للبيانات لا تضيف القيمة في مشكلات تصنيف النص؛ فننصحك بتخطي هذه الخطوة
تضع التعليمة البرمجية التالية كل الخطوات المذكورة أعلاه معًا:
- إنشاء رموز مميّزة لعينات النص في كلمات uni+bigram
- أيهما يتجه باستخدام ترميز tf-idf،
- تحديد أهم 20,000 ميزة فقط من متجه الرموز المميزة عن طريق تجاهل الرموز المميزة التي تظهر أقل من مرتين وتستخدم f_classif لحساب الميزة الأهمية.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
باستخدام تمثيل الخط المتجه بنمط n، نتجاهل الكثير من المعلومات عن كلمة والقواعد والقواعد النحوية (في أفضل الأحوال، يمكننا الاحتفاظ ببعض معلومات الطلب الجزئية عندما n > 1. وهذا ما يسمى نهج حزمة الكلمات. يتم استخدام هذا التمثيل إلى جانب النماذج التي لا تراعي الطلب، مثل والانحدار اللوجستي والمصورات متعددة الطبقات وآلات تعزيز التدرج آلات متجه الدعم.
متّجهات التسلسل [الخيار ب]
وفي الفقرات اللاحقة، سنتعرّف على كيفية إنشاء رموز مميّزة الخط المتجه لنماذج التسلسل. كما سنتناول كيف يمكننا تحسين التمثيل المتسلسل باستخدام تقنيات اختيار الخصائص والتسوية.
بالنسبة لبعض نماذج النصوص، يُعد ترتيب الكلمات أمرًا بالغ الأهمية لمعنى النص. بالنسبة مثل الجمل التالية: "كنت أكره رحلتي. غيّرت دراجتي الجديدة تلك بالكامل" عند قراءتها بالترتيب. طُرز مثل CNN/RNN استنتاج المعنى من خلال ترتيب الكلمات في العينة. بالنسبة لهذه النماذج، لتمثيل النص كسلسلة من الرموز المميزة، مع الحفاظ على الترتيب.
إنشاء رمز مميّز
يمكن تمثيل النص إما كتسلسل من الحروف، أو كتسلسل الكلمات. لقد وجدنا أن استخدام التمثيل على مستوى الكلمات يوفر الأداء من الرموز المميزة للأحرف. هذا أيضًا هو المعيار العام الذي يليها المجال. استخدام الرموز المميزة للأحرف لا معنى إلا إذا كانت النصوص تحتوي على الكثير من الأخطاء الإملائية، وهو ما لا يحدث عادةً.
المتّجهات
بمجرد أن نقوم بتحويل عينات النصوص إلى تسلسلات من الكلمات، نحتاج إلى تحويلها هذه التسلسلات إلى متجهات عددية. يوضح المثال أدناه المؤشرات محددة لأحرف يونيغرام التي تم إنشاؤها لنصين، ثم تسلسل الرمز المميز الفهارس التي يتم تحويل النص الأول إليها.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
تم تخصيص فهرس لكل رمز مميّز:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
ملاحظة: يمكن استخدام كلمة "the" هذه تحدث بشكل متكرر، ولذلك فإن قيمة الفهرس 1 هي الذي تم تكليفهم به. وتحتفظ بعض المكتبات بالفهرس 0 للرموز المميزة غير المعروفة، كما الحالة هنا.
تسلسل فهارس الرموز المميّزة:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
هناك خياران متاحان لتوجيه تسلسلات الرموز المميّزة:
ترميز واحد فعال: يتم تمثيل التسلسلات باستخدام متجهات الكلمات في مساحة الأبعاد حيث يكون n = حجم المفردات. هذا التمثيل يعمل بشكل رائع عندما ننشئ رموزًا مميّزة كأحرف، وبالتالي تكون المفردات صغيرة فعندما نعمل على ترميز الكلمات، سيكون لدى المفردات عادةً عشرات الآلاف من الرموز، مما يجعل المتجهات الأحادية قليلة الانتشار وغير فعالة للغاية. مثال:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
تضمين الكلمات: للكلمات التي تحمل معانٍ مرتبطة بها. نتيجة لذلك، أن تمثل رموزًا مميّزة للكلمات في مساحة متجهة كثيفة (حوالي مئات الأرقام الحقيقية)، حيث يشير الموقع والمسافة بين الكلمات إلى مدى التشابه دلاليًا (انظر الشكل 7). يسمى هذا التمثيل تضمين الكلمات.
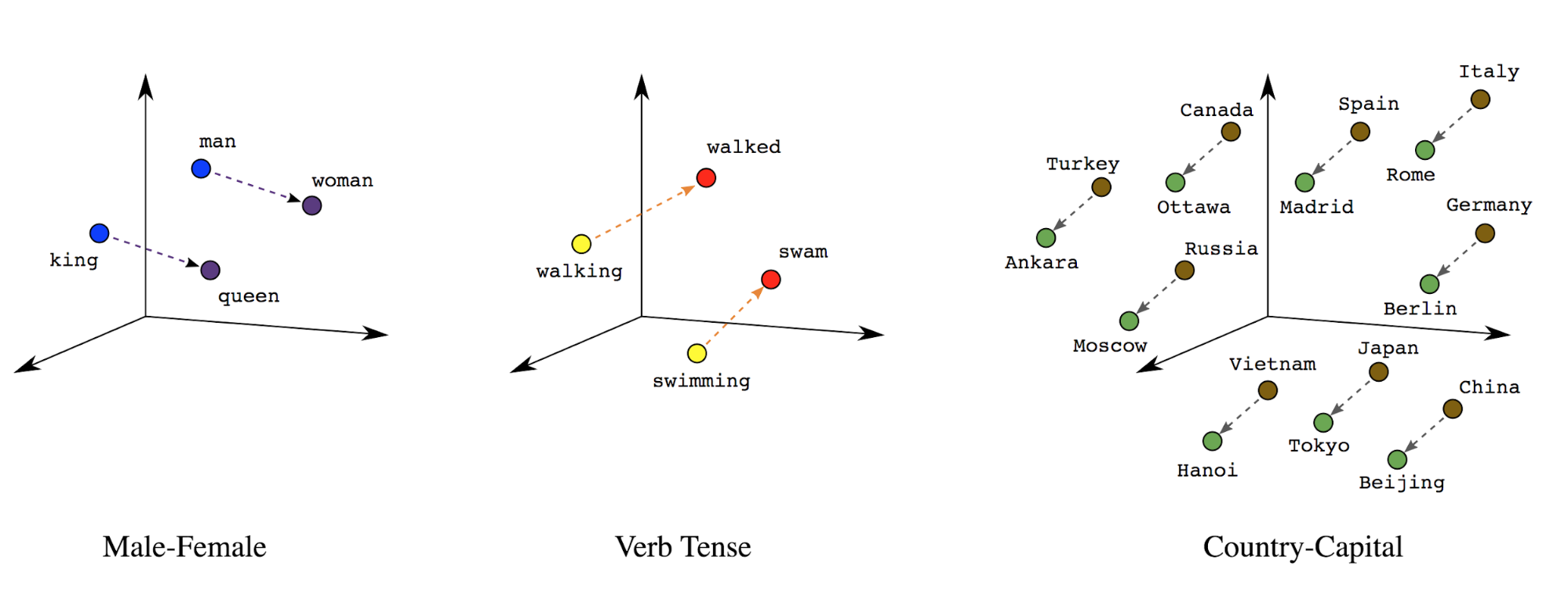
الشكل 7: تضمين الكلمات
غالبًا ما تحتوي نماذج التسلسل على طبقة تضمين كطبقة أولى. هذا النمط تتعلم طبقة تحويل تسلسلات فهرس الكلمات إلى متجهات تضمين الكلمات أثناء عملية التطبيق، بحيث يتم تعيين كل فهرس كلمات إلى متجه كثيف قيمًا حقيقية تمثّل موقع تلك الكلمة في المساحة الدلالية (راجِع الشكل 8).
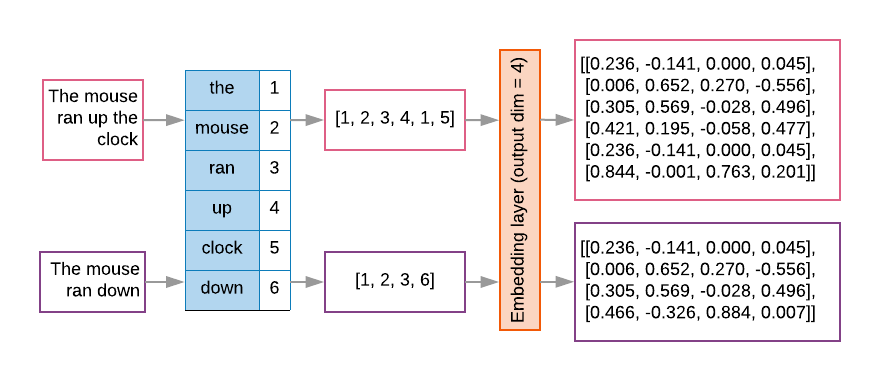
الشكل 8: طبقة التضمين
اختيار الميزات
لا تساهم كل الكلمات الواردة في بياناتنا في التنبؤ بالتصنيفات. يمكننا تحسين عملية التعلم عن طريق التخلص من الكلمات النادرة أو غير ذات الصلة من المفردات. ضِمن والحقيقة، نلاحظ أن استخدام أكثر 20,000 ميزة بشكل عام كافية. وينطبق ذلك على نماذج الغرام أيضًا (راجع الشكل 6).
لنضع كل الخطوات المذكورة أعلاه في متجه التسلسل معًا. تشير رسالة الأشكال البيانية تؤدي التعليمة البرمجية التالية هذه المهام:
- تحويل النص إلى رموز مميّزة
- يتعلّم المفردات باستخدام أفضل 20,000 رمز مميّز
- تحويل الرموز المميزة إلى متجهات متتابعة
- توزيع التسلسلات على طول تسلسل ثابت
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
اتجاه التصنيف
تناولنا كيفية تحويل عينة من البيانات النصية إلى متجهات رقمية. عملية مماثلة
على التصنيفات. يمكننا ببساطة تحويل التصنيفات إلى قيم في النطاق
[0, num_classes - 1] على سبيل المثال، إذا كانت هناك 3 فئات يمكننا استخدامها فقط
0 و1 و2 لتمثيلهم. داخليًا، ستستخدم الشبكة نقطة اتصال واحدة
المتجهات التي تمثل هذه القيم (لتجنب استنتاج علاقة غير صحيحة
بين التسميات). ويعتمد هذا التمثيل على دالة الخسارة
وظيفة تنشيط الطبقة التي نستخدمها في الشبكة العصبية. سنتعلم المزيد حول
هذه في القسم التالي.