Bevor Daten in ein Modell eingespeist werden können, müssen sie in ein Format umgewandelt werden. das Modell verstehen kann.
Zum einen können die von uns erfassten Stichproben in einer bestimmten Reihenfolge angeordnet sein. Wir tun dies: Sie möchten nicht, dass Informationen im Zusammenhang mit der Sortierung von Stichproben Einfluss darauf nehmen, die Beziehung zwischen Texten und Beschriftungen. Wenn ein Dataset zum Beispiel und dann in Trainings-/Validierungs-Datasets aufgeteilt werden, für die Gesamtverteilung der Daten.
Eine einfache Best Practice, um sicherzustellen, dass das Modell nicht von der Datenreihenfolge beeinflusst wird, besteht darin, mischen Sie die Daten immer um, bevor Sie etwas anderes tun. Wenn Ihre Daten bereits in Trainings- und Validierungs-Datasets aufgeteilt sind, müssen Sie Ihre Validierung wie Sie Ihre Trainingsdaten transformieren. Wenn Sie noch keine separate Trainings- und Validierungs-Datasets, können Sie die Beispiele später aufteilen, Zufallsmix; sind es üblich, 80% der Beispiele für das Training und 20% für Validierung.
Zweitens nehmen Algorithmen für maschinelles Lernen Zahlen als Eingaben. Das bedeutet, dass wir müssen die Texte in numerische Vektoren umwandeln. Es sind zwei Schritte erforderlich, diesen Prozess:
Tokenisierung: Teilen Sie die Texte in Wörter oder kleinere Untertexte auf. Dadurch werden eine gute Generalisierung der Beziehung zwischen Texten und Beschriftungen ermöglichen. Dadurch wird das „Vokabular“ des Datasets (Satz eindeutiger Tokens in die Daten).
Vektorisierung: Definieren Sie ein gutes numerisches Maß, um diese zu charakterisieren. Textnachrichten.
Sehen wir uns nun an, wie wir diese beiden Schritte für N-Gramm-Vektoren und Sequenzen Vektoren zu erkennen und die Vektordarstellungen mithilfe von Feature Auswahl- und Normalisierungstechniken.
N-Gramm-Vektoren [Option A]
In den folgenden Abschnitten erfahren Sie, wie Sie Vektorisierung für N-Gramm-Modelle. Wir werden auch besprechen, wie wir die n- Grammdarstellung mithilfe von Featureauswahl- und Normalisierungstechniken.
In einem N-Gramm-Vektor wird Text als eine Sammlung eindeutiger N-Gramme dargestellt:
Gruppen von n benachbarten Tokens (in der Regel Wörter). Betrachten Sie den Text The mouse ran
up the clock. Hier:
- Das Wort Unigramme (n = 1) ist
['the', 'mouse', 'ran', 'up', 'clock']. - Das Wort "Bigrams" (n = 2) ist
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - Dies sind nur einige Beispiele für die Bedeutung von Data Governance.
Tokenisierung
Wir haben festgestellt, dass die Tokenisierung in Wortunigramme und Bigramme gute bei geringerer Rechenzeit.
Vektorisierung
Nachdem wir unsere Textproben in N-Gramme aufgeteilt haben, müssen wir diese N-Gramme in numerische Vektoren umgewandelt, die unsere ML-Modelle verarbeiten können. Das Beispiel unten sehen Sie die Indexe, die den Unigrammen und Bigrammen, die für zwei Textnachrichten.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Sobald den N-Grammen Indexe zugewiesen wurden, vektorisieren wir in der Regel mit einer der folgenden Methoden: die folgenden Optionen.
One-Hot-Codierung: Jeder Beispieltext wird als Vektor dargestellt, der angibt, das Vorhandensein oder Fehlen eines Tokens im Text.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Zählungscodierung: Jeder Beispieltext wird als Vektor dargestellt, der den
Anzahl eines Tokens im Text. Beachten Sie, dass das Element, das der
Unigramm "the" wird jetzt als 2 dargestellt, weil das Wort „the“
zweimal im Text erscheint.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf-Codierung: Das Problem zwei Lösungsansätze besteht darin, dass gängige Wörter in ähnlichen Häufigkeit in allen Dokumenten (d.h. Wörter, die nicht eindeutig auf der Textbeispiele im Dataset) werden nicht bestraft. Zum Beispiel Wörter wie „a“ kommt sehr häufig in allen Texten vor. Eine höhere Tokenanzahl für „the“ als nach anderen aussagekräftigeren Wörtern nicht.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Siehe Scikit-learn TfidfTransformer)
Es gibt viele weitere Vektordarstellungen, aber die drei vorhergehenden sind die am häufigsten verwendet werden.
Wir haben festgestellt, dass die tf-idf-Codierung in (im Schnitt 0,25 bis 15% höher) und empfehlen, diese Methode zu verwenden, zur Vektorisierung von N-Grammen. Denken Sie jedoch daran, dass sie mehr Arbeitsspeicher (als Gleitkommadarstellung verwendet) und die Berechnung mehr Zeit in Anspruch nimmt, insbesondere bei großen Datasets (kann in einigen Fällen doppelt so lange dauern).
Auswahl von Merkmalen
Wenn wir alle Texte in einem Dataset in Wort-Uni+Bigram-Tokens konvertieren, mitunter Zehntausende von Tokens. Nicht alle diese Tokens/Funktionen zur Labelvorhersage beitragen. Wir können z. B. bestimmte Tokens die nur sehr selten im Dataset vorkommen. Wir können auch Merkmalwichtigkeit (wie viel jedes Token zu Labelvorhersagen beiträgt) und nur die informativsten Tokens enthalten.
Es gibt viele statistische Funktionen, die Merkmale und die entsprechenden und geben den Wert für die Featurewichtigkeit aus. Zwei häufig verwendete Funktionen sind f_classif und chi2. Unsere Tests zeigen, dass beide Funktionen gleich gut funktionieren.
Noch wichtiger ist, dass die Genauigkeit bei vielen Datasets (siehe Abbildung 6). Wenn du mehr Funktionen hinzufügst, kannst du deine Umsätze steigern sehr wenig und führt manchmal sogar zu Überanpassung und beeinträchtigt die Leistung.
<ph type="x-smartling-placeholder">
Abbildung 6: Top-K-Funktionen im Vergleich zur Genauigkeit Über die Datasets hinweg steigt die Genauigkeit bei den oberen 20.000 Features.
Normalisierung
Bei der Normalisierung werden alle Feature-/Stichprobenwerte in kleine und ähnliche Werte umgewandelt. Dies vereinfacht die Konvergenz des Gradientenabstiegs in Lernalgorithmen. Von was wie wir gesehen haben, bringt die Normalisierung während der Datenvorverarbeitung nicht viel -Wert in Textklassifizierungsproblemen; empfehlen wir, diesen Schritt zu überspringen.
Mit dem folgenden Code werden alle oben genannten Schritte zusammengefasst:
- Tokenisieren Sie Textproben in Wort-Uni+Bigramme,
- Vektorisieren Sie mit der tf-idf-Codierung,
- Sie können nur die 20.000 wichtigsten Merkmale aus dem Tokenvektor auswählen,indem Sie sie verwerfen Tokens, die weniger als zweimal vorkommen und mit f_classif zur Berechnung des Features verwendet werden Bedeutung.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
Bei der N-Gramm-Vektordarstellung verwerfen wir viele Informationen über ein Wort Reihenfolge und Grammatik (bestens können wir einige Teilbestellungsinformationen pflegen, wenn n > 1). Dies wird als „Bag of Words“-Ansatz bezeichnet. Diese Darstellung wird verwendet, in Verbindung mit Modellen, bei denen die Reihenfolge nicht berücksichtigt wird, wie z. B. logistische Regression, mehrschichtige Perceptrons, Gradientenverstärkungsmaschinen Vektormaschinen zu.
Sequenzvektoren [Option B]
In den folgenden Abschnitten erfahren Sie, wie Sie Vektorisierung von Sequenzmodellen. Wir werden auch besprechen, wie wir die Sequenzdarstellung mithilfe von Funktionen zur Auswahl und Normalisierung.
Bei einigen Textbeispielen ist die Wortreihenfolge für die Bedeutung des Textes entscheidend. Für zum Beispiel die Sätze: „Früher habe ich meinen Arbeitsweg gehasst. Das hat mein neues Fahrrad verändert. vollständig“ verstehen können, wenn sie in der richtigen Reihenfolge gelesen werden. Modelle wie CNNs/RNNs die Bedeutung aus der Reihenfolge der Wörter in einem Sample ableiten kann. Für diese Modelle stellen den Text als Sequenz von Tokens unter Beibehaltung der Reihenfolge dar.
Tokenisierung
Text kann als Folge von Zeichen oder als Folge von Wörter. Wir haben festgestellt, dass die Darstellung auf Wortebene als Zeichentokens. Das ist auch die allgemeine Norm, gefolgt von der Branche. Die Verwendung von Zeichentokens ist nur sinnvoll, Tippfehler, was normalerweise nicht der Fall ist.
Vektorisierung
Nachdem wir unsere Beispieltexte in Wortfolgen umgewandelt haben, müssen wir diese Sequenzen in numerische Vektoren umwandeln. Das folgende Beispiel zeigt die Indexe die den Unigrammen zugewiesen sind, die für zwei Texte generiert wurden, und dann die Indexe, in die der erste Text konvertiert wird.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Index, der jedem Token zugewiesen ist:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
HINWEIS: Das Wort „the“ tritt am häufigsten auf, sodass der Indexwert 1 gleich die ihr zugewiesen sind. Einige Bibliotheken reservieren Index 0 für unbekannte Tokens, hier den Fall.
Reihenfolge der Tokenindexe:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Es gibt zwei Möglichkeiten, die Tokensequenzen zu vektorisieren:
One-Hot-Codierung: Sequenzen werden mithilfe von Wortvektoren in n- einen räumlichen Bereich, wobei n = Größe des Vokabulars ist. Diese Darstellung funktioniert sehr gut wenn wir als Zeichen tokenisieren, und das Vokabular ist daher klein. Bei der Tokenisierung als Wörter umfasst das Vokabular Tausende Tokens, wodurch die One-Hot-Vektoren sehr dünnbesetzt und ineffizient werden. Beispiel:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Worteinbettungen: Wörter haben eine oder mehrere Bedeutungen. Daher Worttokens in einem dichten Vektorraum (~wenige hundert reelle Zahlen) darstellen wobei die Position und der Abstand zwischen Wörtern angeben, wie ähnlich sie sind semantisch (siehe Abbildung 7). Diese Darstellung wird als Worteinbettungen.
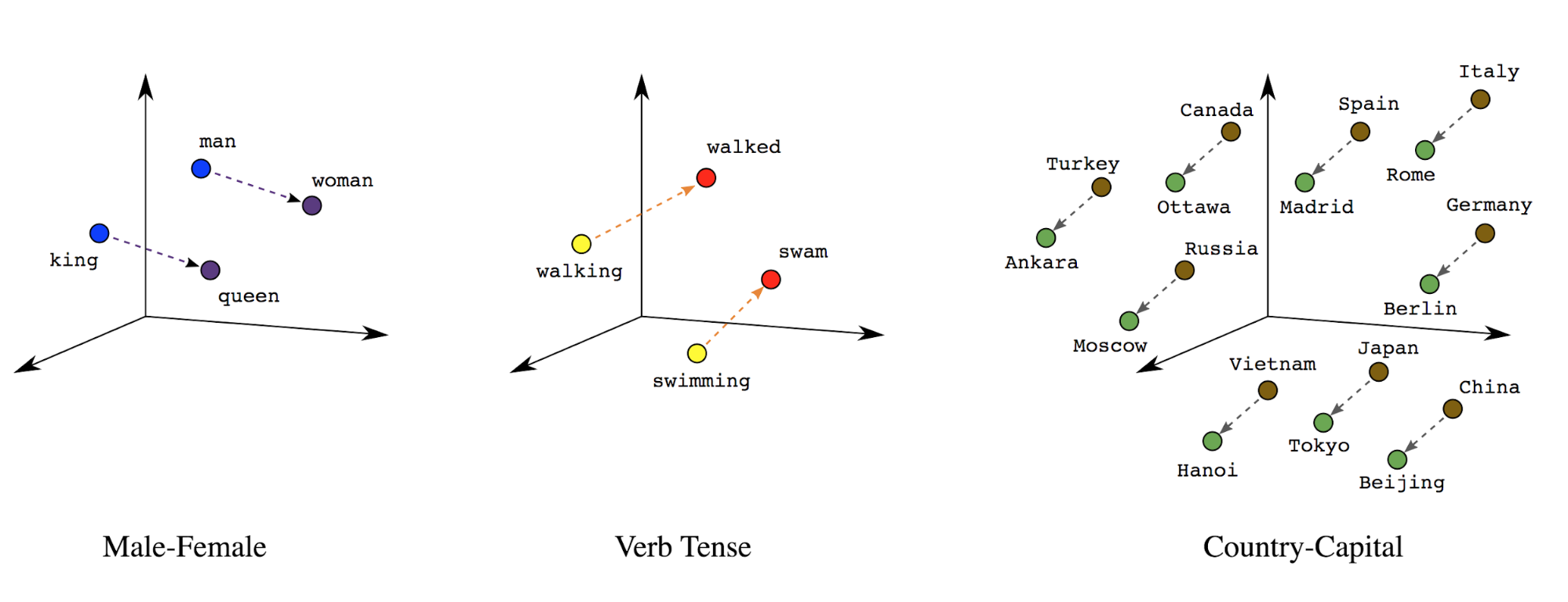
Abbildung 7: Worteinbettungen
Sequenzmodelle haben oft eine solche Einbettungsschicht als erste Schicht. Dieses lernt, während der Schicht Wortindexsequenzen in Worteinbettungsvektoren Trainingsprozess, bei dem jeder Wortindex einem dichten Vektor reelle Werte, die die Position dieses Wortes im semantischen Raum darstellen (siehe Abbildung 8).
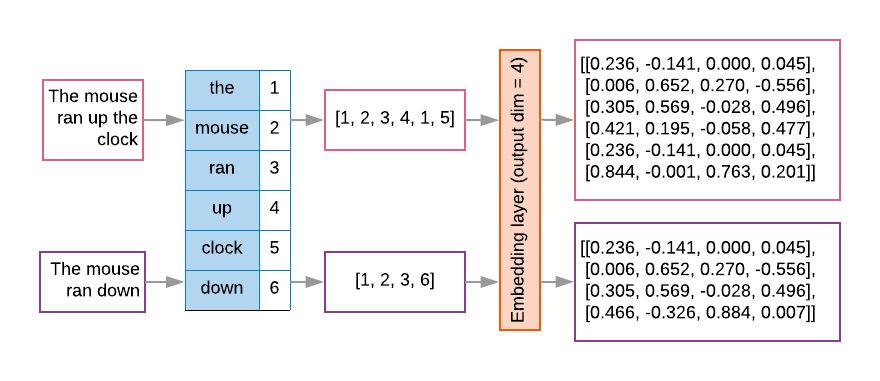
Abbildung 8: Einbettungsebene
Auswahl von Merkmalen
Nicht alle Wörter in unseren Daten tragen zu Labelvorhersagen bei. Wir können unsere indem sie seltene oder irrelevante Wörter aus unserem Vokabular aussortiert. In dass die Verwendung der häufigsten 20.000 Funktionen im Allgemeinen ausreichend. Dies gilt auch für N-Gramm-Modelle (siehe Abbildung 6).
Fassen wir nun alle oben genannten Schritte in einer Sequenzvektorisierung zusammen. Die mit dem folgenden Code werden diese Aufgaben ausgeführt:
- Tokenisiert die Texte in Wörter
- Erstellt ein Vokabular aus den Top-20.000-Tokens
- Wandelt die Tokens in Sequenzvektoren um
- Pads für die Sequenzen auf eine feste Sequenzlänge auf
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Labelvektorisierung
Wir haben gesehen, wie Beispieltextdaten in numerische Vektoren umgewandelt werden. Ein ähnlicher Prozess
auf die Labels angewendet werden muss. Wir können Labels einfach in Werte im Bereich
[0, num_classes - 1] Wenn es z. B. drei Klassen gibt, die wir einfach
0, 1 und 2 dar. Intern verwendet das Netzwerk One-Hot
Vektoren zur Darstellung dieser Werte (um zu vermeiden, dass eine falsche Beziehung abgeleitet wird)
zwischen Labels). Diese Darstellung hängt von der Verlustfunktion und der letzten
die wir in unserem neuronalen Netzwerk verwenden. Im weiteren Verlauf dieses Kurses
im nächsten Abschnitt.