本節將致力於建構、訓練及評估
模型在步驟 3 中,我們
然後透過 S/W 比例,選擇使用 n 元語法模型或序列模型。
接著,請編寫並訓練分類演算法。我們會使用
TensorFlow
tf.keras
。
使用 Keras 建構機器學習模型的重點在於一起合作 和資料處理建構模塊一樣 積木這些層能讓我們指定所需的轉換序列 所扮演的角色我們的學習演算法需要以 且輸出單一分類,我們可以建立圖層的線性堆疊 方法是使用 依序模型 也能使用 Google Cloud CLI 或 Compute Engine API
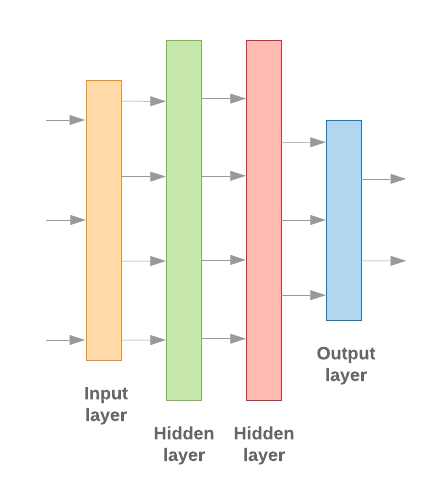
圖 9:圖層的線性堆疊
輸入層和中繼層的建構方式不同 決定要採用哪一種模型但 無論模型類型為何,指定問題的最後一個圖層會相同。
建構最後一層
當我們只有 2 個類別 (二元分類) 時,模型應輸出
單機率分數例如,針對特定輸入樣本輸出 0.2
代表「此樣本有 20% 的信心落在第一類 (類別 1),80%
就在第二類 (類別 0) 中。」為了輸出這種機率分數
活化函數
最後一層應該是
S 函數
和
損失函式
應該用於訓練模型
二進位交叉熵。
(請見左側的圖 10)。
當類別超過 2 個 (多元分類) 時,我們的模型
應該為每個類別輸出一個機率分數這些分數的總和
1.例如,輸出 {0: 0.2, 1: 0.7, 2: 0.1} 表示「20% 的信心
屬於類別 0、70% 為類別 1,10% 則為
2。」為了輸出這些分數,最後一層的活化函數
應為 softmax,而用來訓練模型的損失函式應為
類別交叉熵(請參閱圖 10)。
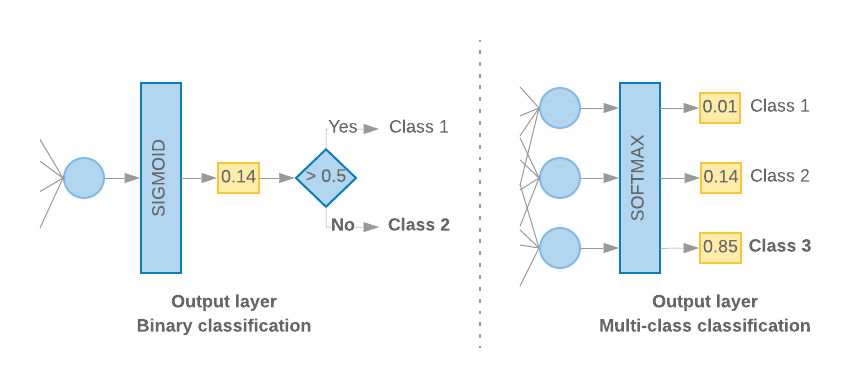
圖 10:最後一層
以下程式碼定義了將類別數量做為輸入內容的函式。 然後輸出適當的圖層單位數量 (1 個二進位單位為 1 單位) 分類;否則每個課程只能有 1 單位) 及適當的啟動動作 函式:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
以下兩節將逐步說明如何建立其餘模型 為 n-gram 模型和序列模型建立層
如果 S/W 的比率偏低,我們發現 n 元語法模型的成效較佳
而非序列模型建議數量較多的序列模型
進行分類這是因為嵌入關係
稠密空間,與許多樣本相比,這種做法效果最佳。
建構 n 元語法模型 [選項 A]
我們指的是獨立處理符記的模型 (未 視為 n-gram 模型。簡單的多層式感知器 (包括 邏輯迴歸 梯度提升機器 和支援向量機模式) 都屬於這個類別他們就無法使用 文字順序
我們比較了上述某些 n 元語法模型的成效, 我們發現,多層感知 (MLP) 的表現通常優於 或設定其他選項多語言模型 (MLP) 很容易定義及瞭解 準確無誤 而且運算較少
以下程式碼在 tf.keras 中定義雙層 MLP 模型,並新增幾個 用於正規化的丟棄層 避免 過度配適 訓練樣本
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
建構序列模型 [選項 B]
我們將模型從符記的相鄰程度學習做為序列 我們來看評估分類模型成效時 的喚回度和精確度指標這包括模型的 CNN 和 RNN 類別。資料預先處理的方式為 這些模型的序列向量
序列模型通常需要學習的參數數量較多。第一個 這類模型為嵌入層 對應至密集向量空間的字詞學習文字關係的運作方式 比較適合用於多個樣本
指定資料集內的字詞不太可能專屬於該資料集。我們可以 使用其他資料集,學習資料集內字詞之間的關係。 如要這麼做,我們可以將從其他資料集學到的嵌入 嵌入層這些嵌入稱為「預先訓練」 嵌入若使用預先訓練的嵌入,可讓模型在 學習程序。
我們使用大型語言模型訓練完預先訓練的嵌入 corpora,例如 GloVe。GloVe 有 訓練完好幾件語料庫 (主要為維基百科)我們測試了 使用 GloVe 嵌入版本的序列模型 凍結預先訓練嵌入的權重 則模型效能不佳這可能是因為 訓練好的嵌入層可能與上下文不同 同時保持有序
使用 Wikipedia 資料訓練的 GloVe 嵌入,可能會與 偵測出 IMDb 資料集的模式推論過程中,您可能需要 更新,也就是說,嵌入權重可能需要調整內容。做法是 階段
第一次執行時,嵌入層權重凍結,剩下的 要在網路中學習在此執行作業結束時,模型會加權達到一個狀態 比起未初始化的值好多了第二次執行時 讓嵌入層也可以學習 並微調所有權重 網路。我們將這個過程稱為使用經過微調的嵌入。
經過微調的嵌入可提高準確度。不過,這是 因此訓練網路所需的運算能力增加費用。假設 及學習嵌入 我們觀察到
S/W > 15K,有效從零開始 因此產生的準確率與微調嵌入相同。
我們比較了 CNN、sepCNN、 RNN (LSTM 和 GRU)、CNN-RNN 和堆疊的 RNN 不同 模型架構我們發現 sepCNNs 是卷積網路變體 通常資料效率更高且運算效率卓越 其他模型
下列程式碼建構了一個四層 sepCNN 模型:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
訓練模型
現在,我們已建構好模型架構,接著需要訓練模型, 訓練是指根據模型目前的狀態進行預測 計算預測結果的準確度,並更新權重或 以盡量減少此錯誤,並讓模型預測 我們重複這個流程,直到模型收斂,直到模型完成收斂為止 想要瞭解機器學習的詞彙 首先須瞭解類神經網路如何學習為此程序選擇了三個重要參數 (請參閱表格 2)。
- 指標:如何使用 指標。我們使用準確率 做為實驗指標
- 減掉函式:用來計算損失值的函式 接著,訓練程序會透過微調 以及網路權重如果是分類問題,跨熵損失的效果相當不錯。
- 最佳化器:決定網路權重方式的函式 模型會根據損失函式的輸出結果更新。我們還使用了 Adam 透過實驗進行最佳化。
在 Keras 中,我們可以使用 編譯 方法。
表 2:學習參數
| 學習參數 | 值 |
|---|---|
| 指標 | 精確度 |
| 損失函式 - 二元分類 | binary_crossentropy |
| 損失函式 - 多類別分類 | sparse_categorical_crossentropy |
| 效率達人 | Adam |
實際的訓練是透過
fit 方法。
視您的大小而定
資料集時,大部分運算週期都會花用這個方法。在
訓練疊代,訓練資料中的 batch_size 樣本數為
,系統會根據這個值更新一次權重。
模型看到整個 epoch 後,訓練程序就會完成
訓練資料集在每個訓練週期結束時,我們會使用驗證資料集
用於評估模型的學習成效我們用資料集
預先決定的訓練週期數我們可能會提早停止
驗證準確率在連續週期之間穩定時,顯示
就不必再訓練模型
| 訓練超參數 | 值 |
|---|---|
| 學習率 | 1e-3 |
| 訓練週期 | 1000 |
| 批量 | 512 |
| 提早中止訓練 | 參數:val_loss、可用性:1 |
表 3:訓練超參數
下列 Keras 程式碼使用 參數實作訓練程序 已選定的表格 2 和有 3 個以上:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
請前往這裡查看訓練序列模型的程式碼範例。