In diesem Abschnitt beschäftigen wir uns mit der Erstellung, Schulung und Bewertung
modellieren. In Schritt 3
haben sich entweder für ein N-Gramm-Modell oder ein Sequenzmodell mit unserem Verhältnis S/W entschieden.
Jetzt ist es an der Zeit, unseren Klassifizierungsalgorithmus zu schreiben und zu trainieren. Wir verwenden
TensorFlow mit dem
tf.keras
API dafür verwenden.
Beim Erstellen von Modellen für maschinelles Lernen mit Keras geht es darum, Schichten, Datenverarbeitungsbausteine, ähnlich wie wir bei Lego-Bausteinen Bausteine. Mithilfe dieser Schichten können wir die Reihenfolge der gewünschten Transformationen angeben. auf unseren Input leisten können. Da unser Lernalgorithmus eine einzelne Texteingabe und eine einzelne Klassifizierung ausgibt, können wir einen linearen Layer-Stapel erstellen. mithilfe der Sequenzielles Modell der API erstellen.
Abbildung 9: Linearer Ebenenstapel
Die Eingabe- und die Zwischenschicht sind unterschiedlich aufgebaut. je nachdem, ob wir ein N-Gramm- oder ein Sequenzmodell erstellen. Aber Unabhängig vom Modelltyp bleibt die letzte Ebene bei einem bestimmten Problem gleich.
Letzte Ebene konstruieren
Wenn wir nur zwei Klassen haben (binäre Klassifizierung), sollte unser Modell eine
den einzelnen Wahrscheinlichkeitswert. Beispielsweise wird 0.2 für ein bestimmtes Eingabebeispiel ausgegeben.
bedeutet: „20% Wahrscheinlichkeit, dass diese Stichprobe in der ersten Klasse (Klasse 1) ist, und 80% davon
sie ist in der zweiten Klasse (Klasse 0).“ Für die Ausgabe eines solchen Wahrscheinlichkeitswerts
Aktivierungsfunktion
der letzten Ebene sollte ein
Sigmoidfunktion,
und die
Verlustfunktion
die zum Trainieren des Modells verwendet wird,
binäre Kreuzentropie.
(siehe Abbildung 10, links).
Wenn es mehr als zwei Klassen gibt (Klassifizierung mit mehreren Klassen), stellt unser Modell
einen Wahrscheinlichkeitswert pro Klasse ausgeben sollte. Die Summe dieser Bewertungen sollte
1. Die Ausgabe von {0: 0.2, 1: 0.7, 2: 0.1} bedeutet beispielsweise „20% Wahrscheinlichkeit, dass
diese Stichprobe ist in Klasse 0, 70% in Klasse 1 und 10% in Klasse 1.
Klasse 2.“ Für die Ausgabe dieser Werte muss die Aktivierungsfunktion der letzten Schicht
sollte „Softmax“ sein und die zum Trainieren des Modells verwendete Verlustfunktion
kategoriale Kreuzentropie. (siehe Abbildung 10, rechts).
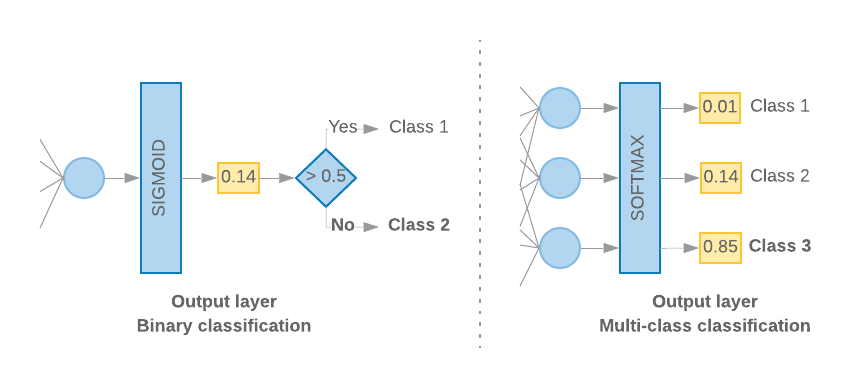
Abbildung 10: Letzte Ebene
Der folgende Code definiert eine Funktion, die die Anzahl der Klassen als Eingabe verwendet, und gibt die entsprechende Anzahl von Layer-Einheiten aus (1 Einheit bei Binärprogrammen). Klassifizierung; andernfalls 1 Einheit für jede Klasse) und die entsprechende Aktivierung :
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
In den folgenden beiden Abschnitten wird die Erstellung des verbleibenden Modells beschrieben. Schichten für N-Gramm-Modelle und Sequenzmodelle.
Wenn das S/W-Verhältnis klein ist, haben wir festgestellt, dass N-Gramm-Modelle besser abschneiden
als Sequenzmodelle. Sequenzmodelle sind besser, wenn es eine große Anzahl von
kleinen, dichten Vektoren. Das liegt daran, dass Beziehungen eingebetteter Inhalte
und das geschieht am besten bei
vielen Proben.
N-Gramm-Modell erstellen [Option A]
Wir beziehen uns dabei auf Modelle, die die Tokens unabhängig verarbeiten und keine Wortreihenfolge des Kontos) als N-Gramm-Modelle. Einfache mehrschichtige Perceptrons (einschließlich logistische Regression Gradient-Boosting-Maschinen, und Vektormaschinenmodelle unterstützen) alle in diese Kategorie fallen: können sie keine Informationen Textsortierung.
Wir haben die Leistung einiger der oben genannten N-Gramm-Modelle verglichen und festgestellt, dass Multi-Layer-Perceptrons (MLPs) in der Regel eine bessere Leistung erzielen als weitere Optionen. MLPs sind einfach zu definieren und zu verstehen, und erfordern relativ wenig Rechenleistung.
Der folgende Code definiert ein zweischichtiges MLP-Modell in tf.keras. Dabei werden Dropout-Ebenen für Regularisierung um zu verhindern, Überanpassung bis hin zu Trainingsbeispielen.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Sequenzmodell erstellen [Option B]
Wir bezeichnen Modelle, die aus der Nähe von Tokens als Sequenz lernen können. Modelle. Dazu gehören auch CNN- und RNN-Modellklassen. Die Daten werden vorverarbeitet als Sequenzvektoren für diese Modelle.
Sequenzmodelle haben in der Regel eine größere Anzahl von Parametern, die erlernt werden müssen. Die erste in diesen Modellen eine Einbettungsschicht, die die Beziehung zwischen zwischen den Wörtern in einem dichten Vektorraum. Das Erlernen von Wortbeziehungen funktioniert bei vielen Samples am besten ist.
Wörter in einem bestimmten Dataset sind höchstwahrscheinlich nicht eindeutig für dieses Dataset. Wir können also die Beziehung zwischen den Wörtern in unserem Dataset mithilfe anderer Datasets ermitteln. Dazu können wir eine aus einem anderen Dataset erlernte Einbettung in unser Einbettungsebene. Diese Einbettungen werden als vortrainierte Einbettungen bezeichnet. Einbettungen. Mit einer vortrainierten Einbettung erhält das Modell einen Vorsprung Lernprozess.
Es sind vortrainierte Einbettungen verfügbar, die mit großen Korpora, z. B. GloVe. GloVe hat wurde in mehreren Korpora (hauptsächlich Wikipedia) geschult. Wir haben die Schulung Sequenzmodelle mit einer Version von GloVe-Einbettungen. Wir haben beobachtet, dass wir, wenn wir die Gewichte der vortrainierten Einbettungen eingefroren und nur der Rest der funktionierten die Modelle nicht gut. Das könnte daran liegen, dass der Kontext bei dem die Einbettungsebene trainiert wurde, in dem wir sie verwendet haben.
GloVe-Einbettungen, die mit Wikipedia-Daten trainiert wurden, stimmen möglicherweise nicht mit der Sprache überein Mustern in unserem IMDb-Dataset. Die abgeleiteten Beziehungen benötigen Aktualisierung – d.h., die Einbettungsgewichtungen erfordern möglicherweise eine kontextabhängige Feinabstimmung. Wir machen das in zwei Phasen:
Beim ersten Durchlauf wurden die Gewichtungen der Einbettungsschicht eingefroren und der Rest wird zugelassen. des Netzwerks lernen. Am Ende dieser Ausführung erreichen die Modellgewichtungen einen Zustand viel besser als ihre nicht initialisierten Werte. Beim zweiten Durchlauf Ermöglicht es der Einbettungsebene, ebenfalls zu lernen und Feinabstimmungen an allen Gewichtungen vorzunehmen im Netzwerk. Wir bezeichnen diesen Prozess als eine abgestimmte Einbettung.
Detaillierte Einbettungen erzielen eine höhere Genauigkeit. Dies betrifft jedoch Kosten für mehr Rechenleistung, die zum Trainieren des Netzwerks erforderlich ist. Bei genügend Stichproben zu erhalten, könnten wir auch eine Einbettung lernen, von Grund auf neu erstellen. Wir haben festgestellt, dass für
S/W > 15Keffektiv bei null anzufangen liefert ungefähr die gleiche Genauigkeit wie eine abgestimmte Einbettung.
Wir haben verschiedene Sequenzmodelle wie CNN, sepCNN und RNN (LSTM &GRU), CNN-RNN und gestapeltes RNN, wobei die Modellarchitekturen. Wir fanden heraus, dass sepCNNs, eine Convolutional Network-Variante, sind häufig daten- und recheneffizienter und erzielen eine bessere Leistung als die andere Modelle.
<ph type="x-smartling-placeholder">Mit dem folgenden Code wird ein sepCNN-Modell mit vier Schichten erstellt:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Modell trainieren
Nachdem Sie die Modellarchitektur erstellt haben, müssen Sie das Modell trainieren. Beim Training wird eine Vorhersage auf Basis des aktuellen Modellstatus getroffen. Berechnung, wie falsch die Vorhersage ist, und aktualisieren die Gewichtungen oder Parameter des Netzwerks zur Minimierung dieses Fehlers besser machen. Wir wiederholen diesen Vorgang, bis unser Modell konvergiert ist und nicht mehr lernen. Für diesen Prozess müssen drei wichtige Parameter ausgewählt werden (siehe Tabelle 2.
- Messwert: Wie Sie die Leistung unseres Modells mithilfe eines metric. Wir haben Genauigkeit verwendet, als Messwert in unseren Tests.
- Verlustfunktion: Eine Funktion, mit der ein Verlustwert berechnet wird. dass der Trainingsprozess dann versucht, durch Abstimmung der Netzwerk-Gewichtungen. Für Klassifizierungsprobleme eignet sich der Kreuzentropieverlust gut.
- Optimierungstool: Eine Funktion, die bestimmt, wie die Netzwerkgewichtung bestimmt wird basierend auf der Ausgabe der Verlustfunktion aktualisiert. Wir haben die beliebten Adam-Optimierungstool verwenden.
In Keras können wir diese Lernparameter mithilfe der zusammenstellen .
Tabelle 2: Lernparameter
| Lernparameter | Wert |
|---|---|
| Messwert | Genauigkeit |
| Verlustfunktion – binäre Klassifizierung | binary_crossentropy |
| Verlustfunktion – Klassifizierung mit mehreren Klassifizierungen | sparse_categorical_crossentropy |
| Optimierung | Adam |
Das eigentliche Training erfolgt mithilfe der
fit-Methode.
Je nach Größe der
Dataset ist dies die Methode, mit der die meisten Rechenzyklen genutzt werden. In jeder
Trainingsdurchlauf, batch_size Stichproben aus Ihren Trainingsdaten sind
zur Berechnung des Verlusts verwendet, und die Gewichtungen werden einmal auf der Grundlage dieses Werts aktualisiert.
Der Trainingsprozess führt einen epoch durch, sobald das Modell die gesamte
Trainings-Dataset. Am Ende jeder Epoche werden
mithilfe des Validierungs-Datasets
wie gut das Modell lernt. Wir wiederholen das Training
mit dem Dataset,
für eine vorgegebene Anzahl von Epochen. Wir können dies optimieren, indem wir die Anzeige frühzeitig beenden,
wenn sich die Validierungsgenauigkeit
zwischen aufeinanderfolgenden Epochen stabilisiert, was zeigt,
wird das Modell nicht mehr trainiert.
| Trainings-Hyperparameter | Wert |
|---|---|
| Lernrate | 1e–3 |
| Epochen | 1000 |
| Batchgröße | 512 |
| Vorzeitiges Beenden | Parameter: val_loss, Geduld: 1 |
Tabelle 3: Hyperparameter trainieren
Mit dem folgenden Keras-Code wird der Trainingsprozess mithilfe der Parameter implementiert in den Tabellen 2 und 3 oben:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Codebeispiele zum Trainieren des Sequenzmodells finden Sie hier.