ในส่วนนี้ เราจะมุ่งมั่นสร้าง ฝึกอบรม และประเมินผล
โมเดล ในขั้นตอนที่ 3 เราจะ
เลือกใช้โมเดล n-gram หรือโมเดลลำดับ โดยใช้อัตราส่วน S/W ของเรา
ตอนนี้ก็ถึงเวลาเขียนอัลกอริทึมการจัดประเภทและฝึกอัลกอริทึมแล้ว เราจะใช้
TensorFlow พร้อม
tf.keras
API สำหรับเรื่องนี้
การสร้างโมเดลแมชชีนเลิร์นนิงด้วย Keras เป็นเรื่องของการประกอบเข้าด้วยกัน เลเยอร์ องค์ประกอบที่ใช้ประมวลผลข้อมูล เหมือนกับที่เราประกอบตัวต่อเลโก้ อิฐ เลเยอร์เหล่านี้ช่วยให้เราสามารถระบุลำดับของการแปลงที่เราต้องการ ดำเนินการกับอินพุตของเราไหม เมื่ออัลกอริทึมการเรียนรู้ของเราใช้การป้อนข้อความครั้งเดียว และแสดงผลเป็นการแยกประเภทเดียว เราจึงสามารถสร้าง กลุ่มเลเยอร์เชิงเส้น โดยใช้ รูปแบบตามลำดับ API
รูปที่ 9: กลุ่มเลเยอร์เชิงเส้น
เลเยอร์อินพุตและเลเยอร์กลางจะสร้างขึ้นแตกต่างกัน ขึ้นอยู่กับว่าเรากำลังสร้างรูปแบบ n-gram หรือลำดับต่อเนื่อง แต่ ไม่ว่าโมเดลจะเป็นประเภทใด เลเยอร์สุดท้ายจะเหมือนกันสำหรับปัญหาที่ระบุ
การสร้างเลเยอร์สุดท้าย
เมื่อมีเพียง 2 คลาส (การจัดประเภทแบบไบนารี) โมเดลของเราควรแสดง
ของความน่าจะเป็นเดี่ยว ตัวอย่างเช่น เอาต์พุต 0.2 สำหรับตัวอย่างอินพุตที่ระบุ
หมายถึง "ความมั่นใจ 20% ว่าตัวอย่างนี้อยู่ในกลุ่มแรก (ระดับ 1) ส่วน 80% นั้น
ก็อยู่ชั้นที่สอง (คลาส 0)" ในการแสดงคะแนนความน่าจะเป็น ค่า
ฟังก์ชันการเปิดใช้งาน
ของเลเยอร์สุดท้ายควรเป็น
ฟังก์ชัน sigmoid
และ
ฟังก์ชันหายไป
ที่ใช้เพื่อฝึกโมเดล
ครอสเอนโทรปีไบนารี
(ดูรูปที่ 10 ทางด้านซ้าย)
เมื่อมีมากกว่า 2 คลาส (การจัดประเภทแบบหลายคลาส) โมเดลของเรา
ควรแสดงคะแนนความน่าจะเป็น 1 คะแนนต่อคลาส ผลรวมของคะแนนเหล่านี้ควรเป็น
1. ตัวอย่างเช่น เอาต์พุต {0: 0.2, 1: 0.7, 2: 0.1} หมายถึง "ความเชื่อมั่น 20% ที่
ตัวอย่างนี้อยู่ในคลาส 0, 70% ที่อยู่ในกลุ่ม 1 และ 10% ที่อยู่ในกลุ่ม
ชั้นเรียน 2" เพื่อแสดงผลคะแนนเหล่านี้ ฟังก์ชันการเปิดใช้งานของเลเยอร์สุดท้าย
ควรเป็น Softmax และฟังก์ชัน Loss ที่ใช้ในการฝึกโมเดลควรจะเป็น
การครอสเอนโทรปีเชิงหมวดหมู่ (ดูรูปที่ 10 ด้านขวา)
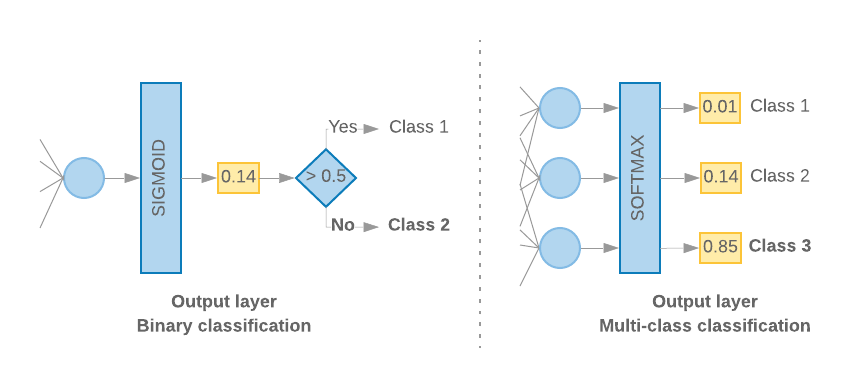
รูปที่ 10: เลเยอร์สุดท้าย
โค้ดต่อไปนี้จะกำหนดฟังก์ชันที่จะนำจำนวนคลาสเป็นอินพุต และแสดงผลจำนวนหน่วยเลเยอร์ที่เหมาะสม (1 หน่วยสำหรับไบนารี การจำแนกประเภท หรือ 1 หน่วยสำหรับแต่ละชั้นเรียน) และการเปิดใช้งานที่เหมาะสม ฟังก์ชัน:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
สองส่วนต่อไปนี้จะอธิบายการสร้างแบบจำลองที่เหลือ สำหรับโมเดล n-gram และโมเดลลำดับ
เมื่ออัตราส่วน S/W มีน้อย เราพบว่าโมเดล n-gram ทำงานได้ดีกว่า
โมเดลลำดับ โมเดลลำดับจะดียิ่งขึ้นเมื่อมีจำนวนมาก
เวกเตอร์ขนาดเล็กที่หนาแน่น เนื่องจากมีการเรียนรู้ความสัมพันธ์แบบฝังใน
พื้นที่ที่หนาแน่นซึ่งจะได้ผลดีที่สุดสำหรับตัวอย่างหลายๆ ตัวอย่าง
สร้างโมเดล n-gram [ตัวเลือก A]
เราหมายถึงโมเดลที่ประมวลผลโทเค็นแยกต่างหาก (โดยไม่พิจารณา ลำดับคำของบัญชี) เป็นโมเดล n-gram เปอร์เซปรอนหลายชั้นอย่างง่าย (รวมถึง การถดถอยแบบโลจิสติกส์ เครื่องเพิ่มพลังการไล่ระดับสี และรองรับโมเดลเครื่องเวกเตอร์) ทั้งหมดจัดอยู่ในหมวดหมู่นี้ แต่จะไม่สามารถใช้ข้อมูลใดๆ เกี่ยวกับ การเรียงลำดับข้อความ
เราได้เปรียบเทียบประสิทธิภาพของโมเดล n-gram บางโมเดลที่กล่าวถึงข้างต้นและ สังเกตเห็นว่าโดยทั่วไปแล้ว Perceptrons แบบหลายชั้น (MLP) จะทำงานได้ดีกว่า ตัวเลือกอื่นๆ MLP นั้นกำหนดและทำความเข้าใจได้ง่าย และให้ความถูกต้องที่ดี และต้องอาศัยการประมวลผลที่ค่อนข้างน้อย
โค้ดต่อไปนี้กำหนดโมเดล MLP แบบ 2 เลเยอร์ใน tf.keras โดยมีการเพิ่ม เลเยอร์แบบเลื่อนลงสำหรับการกำหนดมาตรฐาน เพื่อป้องกัน เกินความเหมาะสม ลงในตัวอย่างการฝึก
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
สร้างโมเดลลำดับ [ตัวเลือก B]
เราใช้โมเดลที่สามารถเรียนรู้จากความต่อเนื่องของโทเค็นตามลำดับ ซึ่งรวมถึงคลาสของโมเดล CNN และ RNN ข้อมูลจะได้รับการประมวลผลล่วงหน้าเป็น เวกเตอร์ลำดับสำหรับโมเดลเหล่านี้
โดยทั่วไปโมเดลลำดับจะมีพารามิเตอร์ที่ต้องเรียนรู้มากกว่า องค์ประกอบ เลเยอร์ในโมเดลเหล่านี้เป็น เลเยอร์ที่ฝัง ซึ่งจะเรียนรู้ความสัมพันธ์ ระหว่างคำในพื้นที่เวกเตอร์ที่หนาแน่น การเรียนรู้เกี่ยวกับความสัมพันธ์ ตัวอย่างที่ดีที่สุดเมื่อเทียบกับตัวอย่างจำนวนมาก
คำในชุดข้อมูลหนึ่งๆ มักจะไม่ซ้ำกับคำในชุดข้อมูลนั้น เราจึงสามารถ เรียนรู้ความสัมพันธ์ระหว่างคำในชุดข้อมูลของเราโดยใช้ชุดข้อมูลอื่นๆ ในการดำเนินการดังกล่าว เราสามารถโอนการฝังที่เรียนรู้จากชุดข้อมูลอื่นไปยัง เลเยอร์ที่ฝัง การฝังเหล่านี้เรียกว่าการฝึกล่วงหน้า การฝัง การใช้การฝังก่อนการฝึกจะช่วยให้โมเดลเริ่มต้นใน ในกระบวนการเรียนรู้
มีการฝังก่อนการฝึกที่ได้รับการฝึกโดยใช้ Corpora เช่น GloVe GloVe มี ได้รับการฝึกอบรมในหลากหลายคลัง (ส่วนใหญ่คือ Wikipedia) เราได้ทดสอบการฝึก โมเดลลำดับโดยใช้การฝัง GloVe เวอร์ชันหนึ่ง และสังเกตเห็นว่าหากเรา ให้น้ำหนักของการฝังที่ฝึกไว้แล้วล่วงหน้า และฝึกฝนส่วนที่เหลือ ทำให้โมเดลทำงานได้ไม่ดี ซึ่งอาจเป็นเพราะบริบทใน ซึ่งเลเยอร์การฝังที่ได้รับการฝึกอาจแตกต่างจากบริบท ที่เราใช้อยู่
การฝัง GloVe ที่ได้รับการฝึกบนข้อมูล Wikipedia อาจไม่สอดคล้องกับภาษาดังกล่าว ในชุดข้อมูล IMDb ของเรา ความสัมพันธ์ที่อนุมานไว้อาจต้อง การอัปเดต กล่าวคือ น้ำหนักของการฝังอาจต้องปรับตามบริบท เราทำเช่นนี้ใน 2 ระยะดังนี้
ในการทำงานครั้งแรก เมื่อน้ำหนักเลเยอร์ที่ฝังถูกหยุดนิ่ง เราจะอนุญาตให้ส่วนที่เหลือ ของเครือข่ายในการเรียนรู้ เมื่อสิ้นสุดการเรียกใช้นี้ น้ำหนักของโมเดลจะไปถึงสถานะ ดีกว่าค่านิยม ที่ยังไม่ได้เริ่มต้นเป็นอย่างมาก ในการเรียกใช้ครั้งที่ 2 เรา ทำให้เลเยอร์ที่ฝังเรียนรู้ ทำการปรับน้ำหนักทั้งหมดอย่างละเอียดได้ ในเครือข่าย เราเรียกกระบวนการนี้ว่าการใช้การฝังที่ได้รับการปรับแต่งอย่างละเอียด
การฝังที่ปรับแต่งมาอย่างดีจะช่วยให้มีความถูกต้องแม่นยำมากขึ้น อย่างไรก็ตาม สิ่งนี้ขึ้นอยู่กับ ของกำลังประมวลผลที่เพิ่มขึ้นซึ่งต้องใช้ในการฝึกเครือข่าย ระบุ ตัวอย่างที่เพียงพอ เราเองก็สามารถทำได้ เช่นเดียวกับการเรียนรู้การฝัง โดยสร้างตั้งแต่ต้น เราสังเกตเห็นว่าสำหรับ
S/W > 15Kการเริ่มใหม่ตั้งแต่ต้นอย่างมีประสิทธิภาพ ให้ความแม่นยำในระดับเดียวกับการใช้การฝังที่มีการปรับแต่ง
เราเปรียบเทียบรูปแบบลำดับต่างๆ เช่น CNN, sepCNN, RNN (LSTM และ GRU), CNN-RNN และ RNN แบบซ้อน โดยแตกต่างกันไปตาม สถาปัตยกรรมโมเดล เราพบว่า sepCNN ซึ่งเป็นตัวแปรของเครือข่ายคอนโวลูชัน (Convolutional Network) มักประหยัดข้อมูลและการประมวลผลได้มากกว่า มีประสิทธิภาพดีกว่า รุ่นอื่นๆ
โค้ดต่อไปนี้จะสร้างโมเดล sepCNN แบบสี่เลเยอร์:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
ฝึกโมเดล
เมื่อได้สร้างสถาปัตยกรรมโมเดลแล้ว เราจะต้องฝึกโมเดลต่อไป การฝึกจะเกี่ยวข้องกับการคาดการณ์ตามสถานะปัจจุบันของโมเดล การคำนวณความไม่ถูกต้องของการคาดการณ์ และอัปเดตน้ำหนักหรือ ของเครือข่ายเพื่อลดข้อผิดพลาดนี้ และทำให้โมเดลคาดการณ์ ได้ดียิ่งขึ้น เราทำซ้ำขั้นตอนนี้จนกระทั่งโมเดลของเราเริ่มบรรจบ และไม่สามารถทำได้อีกต่อไป เรียนรู้ มีพารามิเตอร์หลัก 3 ตัวที่ต้องเลือกสำหรับกระบวนการนี้ (ดูตาราง 2)
- เมตริก: วิธีวัดประสิทธิภาพของโมเดลโดยใช้ เมตริก เราใช้ความถูกต้อง เป็นเมตริกในการทดสอบของเรา
- ฟังก์ชันที่สูญเสียไป: ฟังก์ชันที่ใช้ในการคำนวณค่าการสูญเสีย กระบวนการฝึกพยายามจะลดขนาดลงโดยการปรับ ที่ให้น้ำหนักแก่เครือข่าย สำหรับปัญหาการจัดประเภท การสูญเสียครอสเอนโทรปีทำงานได้ดี
- ตัวเพิ่มประสิทธิภาพ: ฟังก์ชันที่จะกำหนดน้ำหนักของเครือข่าย อัปเดตตามเอาต์พุตของฟังก์ชันการสูญหาย เราใช้หมวดหมู่ เครื่องมือเพิ่มประสิทธิภาพ Adam ในการทดสอบของเรา
ใน Keras เราสามารถส่งต่อพารามิเตอร์การเรียนรู้เหล่านี้ไปยังโมเดลโดยใช้ คอมไพล์
ตารางที่ 2: พารามิเตอร์การเรียนรู้
| พารามิเตอร์การเรียนรู้ | ค่า |
|---|---|
| เมตริก | ความแม่นยำ |
| ฟังก์ชันสูญหาย - การจัดประเภทแบบไบนารี | binary_crossentropy |
| ฟังก์ชันสูญเสียไป - การแยกประเภทแบบหลายคลาส | sparse_categorical_crossentropy |
| ผู้เชี่ยวชาญด้านประสิทธิภาพ | อดัม |
การฝึกอบรมจริงจะเกิดขึ้นโดยใช้
Fit
ขึ้นอยู่กับขนาด
ซึ่งเป็นวิธีการที่จะใช้รอบการประมวลผลส่วนใหญ่ ในแต่ละ
การฝึกซ้ำ batch_size จำนวนตัวอย่างจากข้อมูลการฝึกของคุณ
ซึ่งใช้ในการคำนวณการขาดทุน และน้ำหนักจะได้รับการอัปเดตครั้งเดียวตามค่านี้
กระบวนการฝึกจะเสร็จสิ้น epoch เมื่อโมเดลได้เห็นข้อมูลทั้งหมดแล้ว
ชุดข้อมูลการฝึกอบรม เมื่อสิ้นสุดแต่ละ Epoch จะใช้ชุดข้อมูลการตรวจสอบความถูกต้องเพื่อ
ประเมินว่าโมเดลเรียนรู้ได้ดีเพียงใด เราทำการฝึกซ้ำโดยใช้ชุดข้อมูล
สำหรับจำนวน Epoch ที่กำหนดไว้ล่วงหน้า เราอาจเพิ่มประสิทธิภาพการทำงาน
ด้วยการหยุดตั้งแต่เนิ่นๆ
เมื่อความถูกต้องของการตรวจสอบเสถียรระหว่าง Epoch ต่อเนื่องกัน ซึ่งแสดงให้เห็นว่า
โมเดลไม่ได้ฝึกแล้ว
| ไฮเปอร์พารามิเตอร์การฝึก | ค่า |
|---|---|
| อัตราการเรียนรู้ | 1E-3 |
| ช่วงเวลาสำคัญในอดีต | 1000 |
| ขนาดกลุ่ม | 512 |
| การหยุดก่อนกำหนด | พารามิเตอร์: val_loss, ความอดทน: 1 |
ตาราง 3: ไฮเปอร์พารามิเตอร์การฝึก
โค้ด Keras ต่อไปนี้จะติดตั้งใช้งานกระบวนการฝึกโดยใช้พารามิเตอร์ ที่เลือกไว้ในตาราง 2 และ 3 ข้างต้น:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
โปรดดูตัวอย่างโค้ดสำหรับการฝึกโมเดลลำดับที่นี่