在这一部分中,我们将学习如何构建、训练和评估
模型。在第 3 步中,我们
利用 S/W 比率,选择使用 N 元语法模型或序列模型。
现在,可以编写分类算法并对其进行训练了。我们将使用
TensorFlow
tf.keras
API。
使用 Keras 构建机器学习模型的关键就在于如何组装在一起 设计层、数据处理组件,就像我们用来组装乐高积木 积木。这些层允许我们指定想要的转换序列, 对输入执行的任何任务。当我们的学习算法接受单一文本输入时 并输出单一分类,就可以创建线性堆栈 使用 序列模型 API。
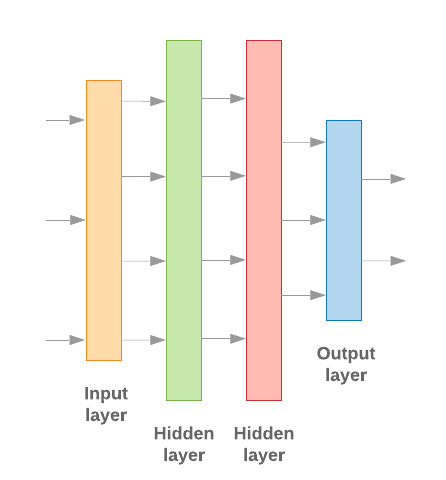
图 9:线性层堆栈
输入层和中间层的构建方式不同, 具体取决于我们构建的是 N 元语法还是序列模型。但是 无论模型类型如何,对于给定问题,最后一层都是相同的。
构建最后一层
当我们只有 2 个类别(二元分类)时,模型应输出
概率得分。例如,针对给定输入样本输出 0.2
指“该样本属于第一类(第 1 类)的置信度为 20%,
它属于第二类(0 类)。”要输出这样的概率得分,
激活函数
应该是
S 型函数、
和
损失函数
用来训练模型的
二元交叉熵。
(参见左侧图 10)。
当类别超过 2 个(多类别分类)时,我们的模型
每个类别输出一个概率得分。这些分数的总和应为
1.例如,输出 {0: 0.2, 1: 0.7, 2: 0.1} 表示
该样本属于类别 0,70% 属于类别 1,10% 属于类别
类别 2”。为了输出这些得分,需要
应该为 softmax,用于训练模型的损失函数应为
分类交叉熵。(参见右侧图 10)。
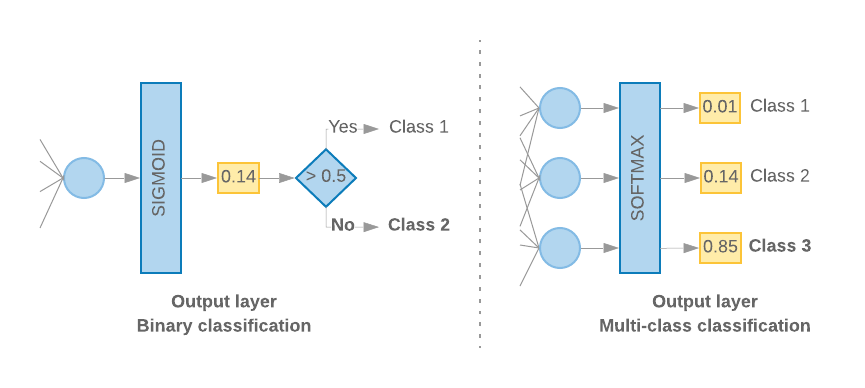
图 10:最后一层
以下代码定义了一个将类数量作为输入的函数。 并输出适当数量的层单元(对于二元, 分类;否则,每门课程 1 个单元)并进行相应的激活 函数:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
以下两部分将逐步介绍如何创建其余模型 用于 N 元语法模型和序列模型的多层。
我们发现,当 S/W 比率较小时,n-gram 模型的表现更好
序列模型。存在大量实体样本时,序列模型
大量小的密集向量。这是因为嵌入关系是在
这种情况最好在许多样本上出现。
构建 N 元语法模型 [选项 A]
我们指的是独立处理词元(不考虑 账号词序)作为 N 元语法模型进行预测。简单的多层感知机(包括 逻辑回归 梯度提升机, 和支持向量机模型) 都属于这一类别;因此无法使用 文本排序。
我们比较了上述一些 N 元语法模型的表现, 发现,多层感知机 (MLP) 的性能通常优于 其他选项MLP 易于定义和理解,准确性高, 所需的计算相对较少。
以下代码在 tf.keras 中定义了一个两层 MLP 模型,并在此基础上添加了几个 用于正则化的丢弃层 以防止 过拟合 训练样本。
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
构建序列模型 [选项 B]
我们将能够从词元的相邻性中学习的模型称为序列, 模型。这包括模型的 CNN 和 RNN 类。数据作为 序列向量。
序列模型通常需要学习更多参数。第一个 即一个嵌入层, 在密集向量空间中单词之间的相对位置。学习字词关系的工作原理 优于许多样本。
给定数据集内的字词很可能不是该数据集中唯一的字词。因此,我们可以 使用其他数据集学习数据集中单词之间的关系。 为此,我们可以将从其他数据集中学到的嵌入转移到我们的 嵌入层。这些嵌入称为“预训练” 嵌入。使用预训练嵌入可让模型 学习过程。
一些预训练嵌入已使用大型语言模型 语料库,例如 GloVe。手套有 已基于多个语料库(主要是维基百科)进行训练。我们测试了 序列模型,并观察到如果 我们冻结了预训练嵌入的权重, 模型表现不佳。这可能是因为 嵌入层训练的 可能与上下文不同, 使用它的方法
使用维基百科数据训练的 GloVe 嵌入可能与该语言不一致 IMDb 数据集内的任何规律。推断的关系可能需要一些 即,嵌入权重可能需要上下文调整。我们会在 两个阶段:
在第一次运行中,嵌入层权重冻结后,我们允许其余部分 进行学习。在本次运行结束时,模型权重达到某个状态, 比它们的未初始化值要好得多。第二次运行时, 让嵌入层也能学习,并微调所有权重。 。我们将此过程称为使用微调嵌入的过程。
微调嵌入可以提高准确性。不过, 训练网络所需的增加计算能力的费用。假设 拥有足够数量的样本, 从头开始。我们发现,从零开始,
S/W > 15K产生的准确率与使用微调嵌入时大致相同。
我们比较了不同的序列模型,例如 CNN、sepCNN、 RNN(LSTM 和 GRU)、CNN-RNN 和堆叠 RNN, 模型架构。我们发现,sepCNN 是一种 通常可提高数据效率和计算效率, 其他模型。
<ph type="x-smartling-placeholder">以下代码可构建一个四层 sepCNN 模型:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
训练模型
现在我们已经构建了模型架构,接下来需要训练模型了。 训练涉及根据模型的当前状态进行预测, 计算预测的错误程度,更新权重或 网络参数,以尽可能减少此错误,并使模型 。我们重复这个过程,直到模型收敛 学习。在此过程中,需要选择三个关键参数(请参阅表格 2.)
- 指标:如何使用 metric。我们使用准确率 用作实验指标
- 损失函数:用于计算损失值的函数 训练过程随后会尝试通过调优权重来最小化 网络权重。对于分类问题,交叉熵损失非常有效。
- Optimizer:一个函数,用于确定网络权重 根据损失函数的输出进行更新。我们使用了热门的 Adam 优化工具。
在 Keras 中,我们可以使用 编译 方法。
表 2:学习参数
| 学习参数 | 值 |
|---|---|
| 指标 | 准确性 |
| 损失函数 - 二元分类 | binary_crossentropy |
| 损失函数 - 多类别分类 | sparse_categorical_crossentropy |
| 优化器 | 小亚 |
实际训练是使用
fit 方法结合使用。
根据您的文件的大小
数据集,这将是大部分计算周期将用在的方法。在每个
训练迭代,训练数据中有 batch_size 个样本
用于计算损失,权重会根据该值更新一次。
一旦模型完成整个训练过程,即完成 epoch
训练数据集。在每个周期结束时,我们使用验证数据集
评估模型的学习效果。我们使用数据集重复训练,
预先确定的周期数。我们可以提前停止测试
验证准确率在连续的周期之间趋于稳定,这表明
模型不再训练。
| 训练超参数 | 值 |
|---|---|
| 学习速率 | 1e-3 |
| 周期 | 1000 |
| 批次大小 | 512 |
| 早停法 | 参数:val_loss,耐心等待:1 |
表 3:训练超参数
以下 Keras 代码使用 在表 2 和上述第 3 项:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
如需查看用于训练序列模型的代码示例,请点击此处。