En esta sección, trabajaremos para crear, entrenar y evaluar nuestro
un modelo de responsabilidad compartida. En el Paso 3,
decidió usar un modelo n-grama o un modelo de secuencia, con nuestra proporción S/W.
Ahora, es momento de escribir el algoritmo de clasificación y entrenarlo. Usaremos
TensorFlow con el
tf.keras
API para esto.
La creación de modelos de aprendizaje automático con Keras consiste en ensamblar de procesamiento de datos, como ensambláramos Lego ladrillos. Estas capas nos permiten especificar la secuencia de transformaciones que queremos para realizar en nuestra entrada. Como nuestro algoritmo de aprendizaje recibe una sola entrada de texto y genera una clasificación única, podemos crear una pila lineal de capas con el Modelo secuencial en la API de Cloud.
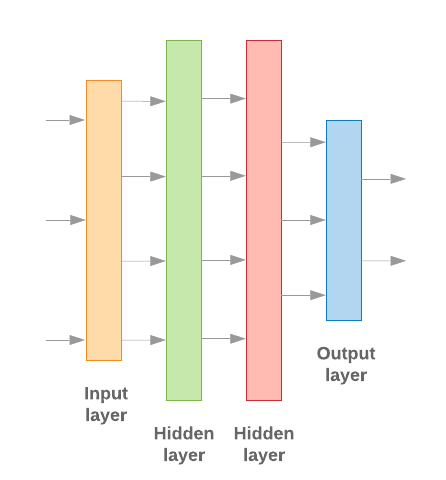
Figura 9: Pila lineal de capas
Las capas de entrada y las intermedias se construirán de manera diferente. dependiendo de si estamos creando un n-grama o un modelo de secuencia. Sin embargo, independientemente del tipo de modelo, la última capa será la misma para un problema determinado.
Construcción de la última capa
Cuando solo tenemos 2 clases (clasificación binaria), nuestro modelo debería generar un
puntuación de probabilidad única. Por ejemplo, generar 0.2 para una muestra de entrada determinada
significa "un 20% de confianza de que esta muestra esté en la primera clase (clase 1) y un 80% de esa
está en la segunda clase (clase 0)". Para dar como resultado una puntuación de probabilidad, el
función de activación
de la última capa debe ser una
función sigmoidea,
y las
función de pérdida
que se usa para entrenar el modelo
entropía cruzada binaria.
(Consulta la figura 10, izquierda).
Cuando hay más de 2 clases (clasificación de clases múltiples), nuestro modelo
debería generar una puntuación de probabilidad por clase. La suma de estas puntuaciones debe ser
1) Por ejemplo, generar {0: 0.2, 1: 0.7, 2: 0.1} significa "un 20% de confianza de que
esta muestra está en la clase 0, el 70% que está en la clase 1 y el 10% que está en
clase 2”. Para obtener estas puntuaciones, la función de activación de la última capa
debe ser softmax, y la función de pérdida usada para entrenar el modelo debería ser
entropía cruzada categórica. Consulta la figura 10, a la derecha.
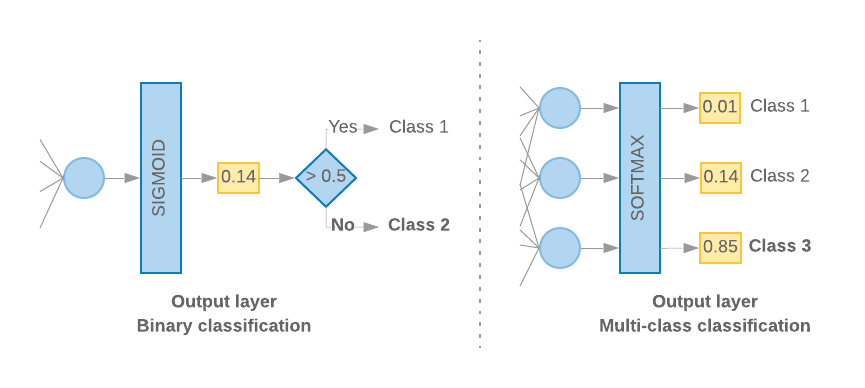
Figura 10: Última capa
El siguiente código define una función que toma el número de clases como entrada. y genera el número adecuado de unidades de capa (1 unidad para objetos binarios la clasificación, de lo contrario, 1 unidad para cada clase) y la activación correspondiente función:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
En las siguientes dos secciones, se explica cómo crear el modelo restante capas para modelos n-grama y modelos de secuencia.
Cuando la proporción S/W es pequeña, descubrimos que los modelos n-grama tienen un mejor rendimiento.
que los modelos de secuencia. Los modelos de secuencia son mejores cuando hay una gran cantidad
de vectores pequeños y densos. Esto se debe a que las relaciones de incorporación se aprenden en
espacio denso, y esto sucede mejor con muchas muestras.
Compilar un modelo n-grama [opción A]
Nos referimos a los modelos que procesan los tokens de forma independiente (sin tener en cuenta orden de palabras de la cuenta) como modelos n-grama. Perceptrones simples de varias capas (incluidos regresión logística máquinas de boosting de gradientes, y máquinas vectoriales de soporte) son parte de esta categoría; no puede usar ninguna información sobre y el orden de los textos.
Comparamos el rendimiento de algunos de los modelos n-grama mencionados anteriormente y observaron que los perceptrones multicapa (MLP) suelen tener un mejor rendimiento que otras opciones. Los MLP son fáciles de definir y comprender, proporcionan una buena precisión y requieren relativamente poco procesamiento.
El siguiente código define un modelo de MLP de dos capas en tf.keras y agrega algunos Capas de retirado para regularización para evitar sobreajuste hasta muestras de entrenamiento.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Modelo de secuencia de compilación [opción B]
Nos referimos a los modelos que pueden aprender de la proximidad de los tokens como secuencias e implementar modelos automáticamente. Esto incluye las clases de modelos CNN y RNN. Los datos se procesan previamente como vectores de secuencia para estos modelos.
Los modelos de secuencia suelen tener una mayor cantidad de parámetros para aprender. La primera en estos modelos es una capa de incorporación, que aprende la relación entre las palabras en un espacio vectorial denso. Aprender las relaciones de palabras funciona entre muchas muestras.
Lo más probable es que las palabras de un conjunto de datos determinado no sean exclusivas de ese conjunto de datos. Por lo tanto, podemos aprender la relación entre las palabras en nuestro conjunto de datos mediante otros conjuntos de datos. Para hacerlo, podemos transferir una incorporación que aprendimos de otro conjunto de datos a nuestro capa de incorporación. Estas incorporaciones se conocen como previamente entrenadas las incorporaciones. El uso de una incorporación previamente entrenada le da al modelo una ventaja en la de aprendizaje automático.
Hay incorporaciones previamente entrenadas disponibles que se entrenaron con modelos corpus, como GloVe. GloVe tiene entrenarse con varios corpus (principalmente Wikipedia). Probamos entrenar nuestro secuenciales usando una versión de incorporaciones GloVe y observamos que si se congeló el peso de las incorporaciones previamente entrenadas y se entrenó solo el resto redes, los modelos no tuvieron un buen rendimiento. Esto podría deberse a que el contexto en con la que se entrenó la capa de incorporación, pueden ser diferentes del contexto en la que la utilicábamos.
Es posible que las incorporaciones de GloVe entrenadas con datos de Wikipedia no se alineen con el lenguaje en el conjunto de datos de IMDb. Las relaciones inferidas pueden necesitar actualizando, es decir, es posible que los pesos de incorporación necesiten un ajuste contextual. Lo hacemos en dos etapas:
En la primera ejecución, con los pesos de la capa de incorporación congelados, permitimos el resto. de la red para aprender. Al final de esta ejecución, los pesos del modelo alcanzan un estado que es mucho mejor que sus valores no inicializados. Para la segunda ejecución, permitir que la capa de incorporación también aprenda y realice ajustes finos a todos los pesos en la red. Nos referimos a este proceso como el uso de una incorporación ajustada.
Las incorporaciones ajustadas generan una mayor exactitud. Sin embargo, esto ocurre en el el aumento de la potencia de procesamiento necesaria para entrenar la red. Dado un una cantidad suficiente de muestras, podríamos aprender lo mismo que una incorporación desde cero. Observamos que, para
S/W > 15K, empezar desde cero de manera efectiva produce casi la misma exactitud que con el uso de la incorporación ajustada.
Comparamos diferentes modelos de secuencia, como CNN, sepCNN, RNN (LSTM y GRU), CNN-RNN y RNN apilado, lo que varía la arquitecturas de modelos de AA. Descubrimos que sepCNN, una variante de red convolucional que suele ser más eficiente en datos y en procesamiento, tiene un mejor rendimiento que el con otros modelos.
El siguiente código construye un modelo sepCNN de cuatro capas:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Entrena tu modelo
Ahora que construimos la arquitectura del modelo, debemos entrenar el modelo. El entrenamiento implica hacer una predicción basada en el estado actual del modelo calcular qué tan incorrecta es la predicción y actualizar las ponderaciones o parámetros de la red para minimizar este error y hacer que el modelo prediga mejor. Repetimos este proceso hasta que el modelo converja y ya no pueda aprender. Hay tres parámetros clave que debes elegir para este proceso (consulta la Tabla 2).
- Métrica: Cómo medir el rendimiento de nuestro modelo con una métrica. Utilizamos la exactitud. como la métrica en nuestros experimentos.
- Función de pérdida: Es una función que se usa para calcular un valor de pérdida. que el proceso de entrenamiento intenta minimizar a través del ajuste los pesos de la red. Para los problemas de clasificación, la pérdida de entropía cruzada funciona bien.
- Optimizador: una función que decide cómo serán los pesos de la red. según el resultado de la función de pérdida. Usamos la popular Adam en nuestros experimentos.
En Keras, podemos pasar estos parámetros de aprendizaje a un modelo con el compilar .
Tabla 2: Parámetros de aprendizaje
| Parámetro de aprendizaje | Valor |
|---|---|
| Métrica | exactitud |
| Función de pérdida: clasificación binaria | binary_crossentropy |
| Función de pérdida: clasificación de clases múltiples | sparse_categorical_crossentropy |
| Optimizador | Daniel |
El entrenamiento real se realiza
fit.
Según el tamaño de tu
conjunto de datos, este es el método con el que se consumirán la mayoría de los ciclos de procesamiento. En cada
iteración de entrenamiento, se batch_size la cantidad de muestras de tus datos de entrenamiento
que se usan para calcular la pérdida, y los pesos se actualizan una vez, según este valor.
El proceso de entrenamiento completa una epoch una vez que el modelo haya visto todo
conjunto de datos de entrenamiento. Al final de cada ciclo de entrenamiento, usamos el conjunto de datos de validación para
evaluar qué tan bien aprende el modelo. Repetimos el entrenamiento con el conjunto de datos
para un número predeterminado de ciclos de entrenamiento. Podemos optimizar esto si detenemos temprano
cuando la exactitud de la validación se estabiliza entre ciclos de entrenamiento consecutivos, lo que muestra que
el modelo ya no se entrena.
| Hiperparámetro de entrenamiento | Valor |
|---|---|
| Tasa de aprendizaje | 1e-3 |
| Ciclos de entrenamiento | 1000 |
| Tamaño del lote | 512 |
| Interrupción anticipada | parámetro: val_loss, paciencia: 1 |
Tabla 3: Hiperparámetros de entrenamiento
El siguiente código Keras implementa el proceso de entrenamiento con los parámetros elegidas en las Tablas 2 y 3 arriba:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Encuentra ejemplos de código para entrenar el modelo de secuencia aquí.