इस सेक्शन में, हम अपनी टेक्नोलॉजी को बनाने, उसे ट्रेनिंग देने, और उसका आकलन करने पर काम करेंगे
मॉडल. तीसरे चरण में, हमने
हमारे S/W अनुपात का इस्तेमाल करके, एन-ग्राम मॉडल या क्रम वाले मॉडल का इस्तेमाल करने का विकल्प चुना गया.
अब समय आ गया है कि आप डेटा की कैटगरी तय करने वाले हमारे एल्गोरिदम को लिखें और उसे ट्रेनिंग दें. हम इस्तेमाल करेंगे
TensorFlow को
tf.keras
इसके लिए एपीआई.
Keras की मदद से मशीन लर्निंग मॉडल बनाने का मतलब है, उन्हें एक-दूसरे से जोड़ना लेयर, डेटा-प्रोसेसिंग बिल्डिंग ब्लॉक, बिलकुल वैसे ही जैसे हम लेगो को इकट्ठा करते हैं ब्रिक्स. ये लेयर, हमें अपने हिसाब से हुए बदलावों का क्रम तय करने की अनुमति देती हैं हमारे इनपुट के आधार पर काम करने के लिए. हमारे लर्निंग एल्गोरिदम में एक टेक्स्ट इनपुट इस्तेमाल होता है, इसलिए और एक सिंगल क्लासिफ़िकेशन का आउटपुट देता है, तो हम लेयर का एक लीनियर स्टैक बना सकते हैं इसका इस्तेमाल करके क्रम में चलने वाला मॉडल एपीआई.
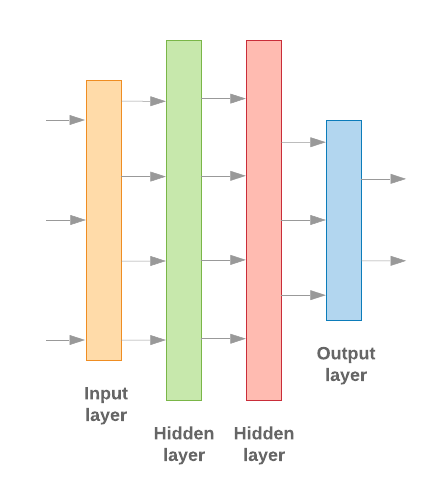
इमेज 9: लेयर का लीनियर स्टैक
इनपुट लेयर और इंटरमीडिएट लेयर को अलग-अलग तरीके से बनाया जाएगा, यह इस बात पर निर्भर करता है कि हम एन-ग्राम तैयार कर रहे हैं या क्रम मॉडल बना रहे हैं. लेकिन इस बात से कोई फ़र्क़ नहीं पड़ता कि मॉडल किस तरह का है, दिए गए सवाल के लिए आखिरी लेयर वही रहेगी.
आखिरी लेयर बनाना
जब हमारे पास केवल 2 क्लास (बाइनरी क्लासिफ़िकेशन) होती हैं, तो हमारे मॉडल को
सिंगल प्रॉबबिलिटी स्कोर. उदाहरण के लिए, दिए गए इनपुट सैंपल के लिए 0.2 आउटपुट करना
इसका मतलब है कि “20% भरोसा है कि यह सैंपल पहली क्लास (क्लास 1) में है. इससे 80% लोग
यह दूसरी क्लास (क्लास 0) में है.” ऐसा प्रॉबबिलिटी स्कोर देने के लिए,
ऐक्टिवेशन फ़ंक्शन
आखिरी लेयर का साइज़
सिगमॉइड फ़ंक्शन,
और
लॉस फ़ंक्शन
मॉडल को ट्रेनिंग देने के लिए, उसका इस्तेमाल
बाइनरी क्रॉस-एंट्रॉपी.
(बाईं ओर दी गई इमेज 10 देखें).
दो से ज़्यादा क्लास (मल्टी-क्लास क्लासिफ़िकेशन) होने पर, हमारा मॉडल
हर क्लास के लिए एक प्रॉबबिलिटी स्कोर देना चाहिए. इन स्कोर का कुल योग इतना होना चाहिए
1. उदाहरण के लिए, {0: 0.2, 1: 0.7, 2: 0.1} दिखाने का मतलब है कि “20% भरोसा है कि
यह सैंपल क्लास 0 में है. यह 1 क्लास की तुलना में 70% और 10% है
क्लास 2.” ये स्कोर पाने के लिए, आखिरी लेयर का ऐक्टिवेशन फ़ंक्शन
सॉफ़्टमैक्स होना चाहिए और मॉडल को ट्रेनिंग देने के लिए इस्तेमाल किए जाने वाले लॉस फ़ंक्शन को
कैटगरीकल क्रॉस-एंट्रॉपी. (दाईं ओर दी गई इमेज 10 देखें).
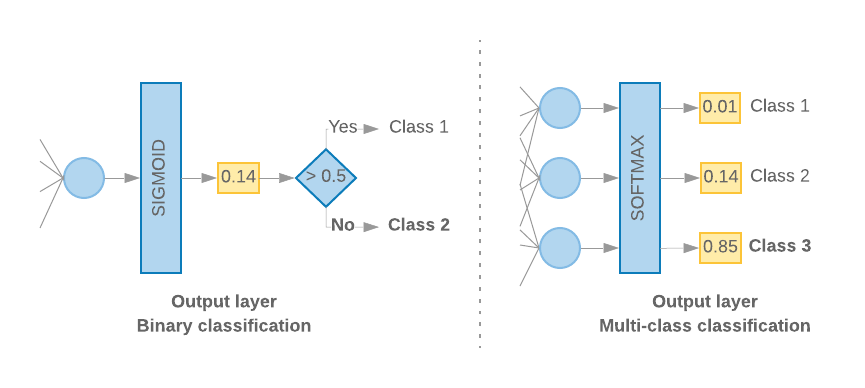
इमेज 10: आखिरी लेयर
यह कोड एक ऐसे फ़ंक्शन के बारे में बताता है जो क्लास की संख्या को इनपुट के तौर पर लेता है, और लेयर यूनिट की सही संख्या देता है (बाइनरी के लिए 1 इकाई) वर्गीकरण; या फिर हर क्लास के लिए एक यूनिट) और सही ऐक्टिवेशन फ़ंक्शन:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
नीचे दिए गए दो सेक्शन में, बाकी मॉडल बनाने के बारे में जानकारी दी जाती है एन-ग्राम मॉडल और सीक्वेंस मॉडल की लेयर.
S/W का अनुपात छोटा होने पर, हमने पाया है कि एन-ग्राम मॉडल बेहतर परफ़ॉर्म करते हैं
क्रम मॉडल की तुलना में. मॉडल की संख्या ज़्यादा होने पर क्रम वाले मॉडल बेहतर होते हैं
जिसमें छोटे, सघन वेक्टर होते हैं. ऐसा इसलिए होता है, क्योंकि रिश्तों को एम्बेड करना
घना स्पेस होता है, जो कई सैंपल में सबसे अच्छी तरह होता है.
बिल्ड एन-ग्राम मॉडल [विकल्प A]
हम उन मॉडल को रेफ़र करते हैं जो टोकन को अलग से प्रोसेस करते हैं खाते के शब्द का क्रम). कई लेयर वाले सामान्य पर्सपेट्रोन (इनमें ये शामिल हैं लॉजिस्टिक रिग्रेशन ग्रेडिएंट बूस्टिंग मशीन, और वेक्टर मशीन मॉडल पर काम करता है) सभी कैटगरी इस कैटगरी में आती हैं; वे इसके बारे में कोई जानकारी इस्तेमाल नहीं कर सकते टेक्स्ट का क्रम.
हमने ऊपर बताए गए कुछ एन-ग्राम मॉडल की परफ़ॉर्मेंस की तुलना की और हमने देखा कि कई लेयर वाले पर्सेप्ट्रॉन (एमएलपी) आम तौर पर अन्य विकल्प. MLP को परिभाषित करना और समझना आसान होता है, ये अच्छी सटीक होती हैं, और इसके लिए बहुत कम कैलकुलेशन की ज़रूरत होती है.
नीचे दिया गया कोड, tf.keras में दो लेयर वाले MLP मॉडल को परिभाषित करता है. इसमें रेगुलराइज़ेशन के लिए ड्रॉपआउट लेयर को रोकने के लिए ओवरफ़िटिंग ट्रेनिंग सैंपल में बदल सकते हैं.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
बिल्ड क्रम का मॉडल [Option B]
हम उन मॉडल को देखते हैं जो टोकन के आस-पास होने से सीख सकते हैं मॉडल. इसमें मॉडल के CNN और RNN क्लास शामिल हैं. डेटा को इस तौर पर पहले से प्रोसेस किया जाता है इन मॉडल के लिए सीक्वेंस वेक्टर.
आम तौर पर, क्रम वाले मॉडल में सीखने के लिए बड़ी संख्या में पैरामीटर होते हैं. पहला इन मॉडल में लेयर एक एम्बेडिंग लेयर है, जो एक सघन सदिश स्पेस में शब्दों के बीच में. एक-दूसरे से जुड़ी बातों को समझने से काम हो जाता है अच्छी तरह से पढ़ें.
इस बात की संभावना ज़्यादा है कि किसी दिए गए डेटासेट में मौजूद शब्द, उस डेटासेट के लिए यूनीक न हों. इसलिए, हम ऐसा कर सकते हैं अन्य डेटासेट का इस्तेमाल करके, हमारे डेटासेट के शब्दों के बीच के संबंध के बारे में जानें. ऐसा करने के लिए, हम दूसरे डेटासेट से सीखी गई एम्बेडिंग को अपने एम्बेडिंग लेयर. इन एम्बेडिंग को पहले से ट्रेन किया गया कहा जाता है एम्बेड करना. पहले से ट्रेन की गई एम्बेडिंग का इस्तेमाल करने से, मॉडल को सीखने की प्रक्रिया.
पहले से ट्रेन किए गए ऐसे एम्बेडिंग मौजूद हैं जिन्हें बड़ी स्क्रीन का इस्तेमाल करके ट्रेनिंग दी गई है कॉर्पोरा, जैसे कि GloVe. ग्लोवी के पास को कई कॉर्पोरा (मुख्य तौर पर Wikipedia) पर ट्रेनिंग दी गई है. हमने अपनी ट्रेनिंग की सीक्वेंस मॉडल में GloVe एम्बेड के वर्शन का इस्तेमाल किया गया और देखा गया कि अगर हम ने पहले से ट्रेन किए गए एम्बेडिंग के बोझ को कम कर दिया. साथ ही, बाकी के नेटवर्क, मॉडल ने अच्छा प्रदर्शन नहीं किया. ऐसा इसलिए हो सकता है, क्योंकि यह मुमकिन है कि एम्बेडिंग लेयर की ट्रेनिंग दी गई हो और वह कॉन्टेक्स्ट से अलग हो जिसमें हम उसका इस्तेमाल कर रहे थे.
Wikipedia के डेटा पर ट्रेन किए गए ग्लोवी एम्बेड करने की प्रोसेस, शायद भाषा के हिसाब से न हो पैटर्न हैं. अनुमानित संबंधों के लिए कुछ चीज़ों की ज़रूरत पड़ सकती है अपडेट करना—उदाहरण के लिए, एम्बेड करने के वेट को संदर्भ के हिसाब से ट्यून करने की ज़रूरत हो सकती है. हम ऐसा इन महीनों में करते हैं दो स्टेज:
पहली बार में, एम्बेडिंग लेयर का वेट फ़्रीज़ होने के बाद, हम बाकी काम करने की अनुमति देते हैं उस नेटवर्क का सबसे अच्छा इस्तेमाल किया जा सकता है. इस दौड़ के अंत में, मॉडल का वेट किसी स्थिति तक पहुंच जाता है शुरू न की गई वैल्यू से कहीं बेहतर है. दूसरी बार में, हम इससे एम्बेडिंग लेयर को सीखने की सुविधा भी मिलती है, ताकि सभी वेट में अच्छे से बदलाव किए जा सकें नेटवर्क में. हम इस प्रोसेस को फ़ाइन-ट्यून एम्बेड करने की सुविधा का इस्तेमाल करने के तौर पर देखते हैं.
एम्बेड की गई फ़ाइलों को बेहतर तरीके से एम्बेड करने से, ज़्यादा सटीक नतीजे मिलते हैं. हालांकि, यह बात अगर नेटवर्क को ट्रेनिंग देने के लिए, ज़्यादा कंप्यूट पावर की ज़रूरत पड़ती है, तो यह देखते हुए काफ़ी संख्या में सैंपल मिल जाते हैं, तो हम एम्बेड करना सीखने की तरह ही काम कर सकते हैं शुरुआत से मिल रहे हैं. हमें पता चला है कि नए सिरे से
S/W > 15Kकी शुरुआत से यह सुविधा, बेहतर तरीके से एम्बेड करने की सुविधा के इस्तेमाल से करीब-करीब उतनी ही सटीक होती है.
हमने अलग-अलग क्रम के मॉडल की तुलना की है, जैसे कि CNN, sepCNN, RNN (LSTM &GRU), CNN-RNN और स्टैक किए गए RNN के बीच मॉडल आर्किटेक्चर के बारे में ज़्यादा जानें. हमने पाया कि sepCNN, एक कॉन्वलूशनल नेटवर्क वैरिएंट है जो अक्सर, डेटा और इनपुट के हिसाब से ज़्यादा सटीक होता है. इसलिए, यह अन्य मॉडल.
यह कोड, चार लेयर वाला sepCNN मॉडल बनाता है:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
अपने मॉडल को ट्रेन करें
अब जब हमने मॉडल आर्किटेक्चर बना लिया है, तो हमें मॉडल को ट्रेनिंग देनी होगी. ट्रेनिंग में मॉडल की मौजूदा स्थिति के आधार पर अनुमान लगाना शामिल है, यह पता लगाना कि अनुमान कितना गलत है और आकलन के महत्व को अपडेट करना या इस गड़बड़ी को कम करने और मॉडल को अनुमान लगाने के लिए, नेटवर्क के पैरामीटर चुनें किया है. हम इस प्रक्रिया को तब तक दोहराते हैं, जब तक कि हमारा मॉडल अलग नहीं हो जाता और सीखें. इस प्रक्रिया के लिए तीन मुख्य पैरामीटर चुने जाने हैं (टेबल 2.)
- मेट्रिक: मेट्रिक. हमने सटीक होने का इस्तेमाल किया है के तौर पर करते हैं.
- लॉस फ़ंक्शन: नुकसान की वैल्यू का हिसाब लगाने के लिए इस्तेमाल किया जाने वाला फ़ंक्शन इसके बाद, ट्रेनिंग प्रोसेस में कीमतों को ट्यून करके कम करने की कोशिश की जाती है नेटवर्क का वज़न. क्लासिफ़िकेशन से जुड़ी समस्याओं के लिए, क्रॉस-एंट्रॉपी लॉस सबसे सही तरीके से काम करता है.
- ऑप्टिमाइज़र: यह एक फ़ंक्शन है, जो तय करता है कि नेटवर्क का महत्व कैसे होगा लॉस फ़ंक्शन के आउटपुट के आधार पर अपडेट किया जाता है. हमने हमारे प्रयोगों में Adam ऑप्टिमाइज़र.
Keras में, इन लर्निंग पैरामीटर को मॉडल में पास करने के लिए कंपाइल तरीका.
टेबल 2: लर्निंग पैरामीटर
| लर्निंग पैरामीटर | मान |
|---|---|
| मेट्रिक | सटीक |
| लॉस फ़ंक्शन - बाइनरी क्लासिफ़िकेशन | binary_crossentropy |
| लॉस फ़ंक्शन - मल्टी-क्लास क्लासिफ़िकेशन | sparse_categorical_crossentropy |
| ऑप्टिमाइज़र | एडम |
असल ट्रेनिंग, इसके लिए इस्तेमाल होने वाले
fit वाले तरीके का इस्तेमाल करें.
आपके आकार पर निर्भर करते हुए
डेटासेट में, ज़्यादातर कंप्यूट साइकल इसी तरीके से खर्च किए जाएंगे. हर एक में
ट्रेनिंग में बार-बार इस्तेमाल किया जाता है. आपके ट्रेनिंग डेटा में से batch_size सैंपल मिले हैं
इसका इस्तेमाल नुकसान का हिसाब लगाने के लिए किया जाता है. साथ ही, इस वैल्यू के आधार पर वेट को एक बार अपडेट किया जाता है.
जब मॉडल पूरा डेटा देख लेता है, तब ट्रेनिंग की प्रोसेस में epoch पूरा हो जाता है
ट्रेनिंग डेटासेट. हर epoch के आखिर में, हम पुष्टि करने वाले डेटासेट का इस्तेमाल इन कामों के लिए करते हैं
यह आकलन कर सकती हैं कि मॉडल कितना सीख रहा है. हम डेटासेट का इस्तेमाल करके, ट्रेनिंग को दोहराते हैं
युगों की पहले से तय संख्या के लिए. हम इसे जल्द ही बंद करके, इसे ऑप्टिमाइज़ कर सकते हैं,
जब पुष्टि करने की सटीक वैल्यू, लगातार आने वाले epoch के बीच स्थिर हो जाती है, जिससे पता चलता है कि
मॉडल अब ट्रेनिंग में नहीं है.
| ट्रेनिंग हाइपर पैरामीटर | मान |
|---|---|
| सीखने की दर | 1e-3 |
| युग (एपक) | 1000 |
| बैच का साइज़ | 512 |
| समय से पहले रुकने की जगह | पैरामीटर: val_loss, धैर्य: 1 |
तीसरी टेबल: हाइपर पैरामीटर को ट्रेनिंग देना
यह Keras कोड, पैरामीटर का इस्तेमाल करके ट्रेनिंग प्रोसेस लागू करता है टेबल 2 और 3 से ऊपर:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
कृपया क्रम के मॉडल की ट्रेनिंग के लिए, कोड के उदाहरण यहां देखें.