텍스트 분류 알고리즘은 텍스트 데이터를 대규모로 처리하는 다양한 소프트웨어 시스템의 핵심입니다. 이메일 소프트웨어는 텍스트 분류를 사용하여 수신 메일이 받은편지함으로 전송되는지 스팸 폴더로 필터링되는지 확인합니다. 토론 포럼은 텍스트 분류를 사용하여 부적절한 댓글로 신고해야 하는지 판단합니다.
다음은 텍스트 문서를 사전 정의된 주제 집합 중 하나로 분류하는 주제 분류의 두 가지 예입니다. 많은 주제 분류 문제에서 이 분류는 주로 텍스트의 키워드를 기반으로 합니다.
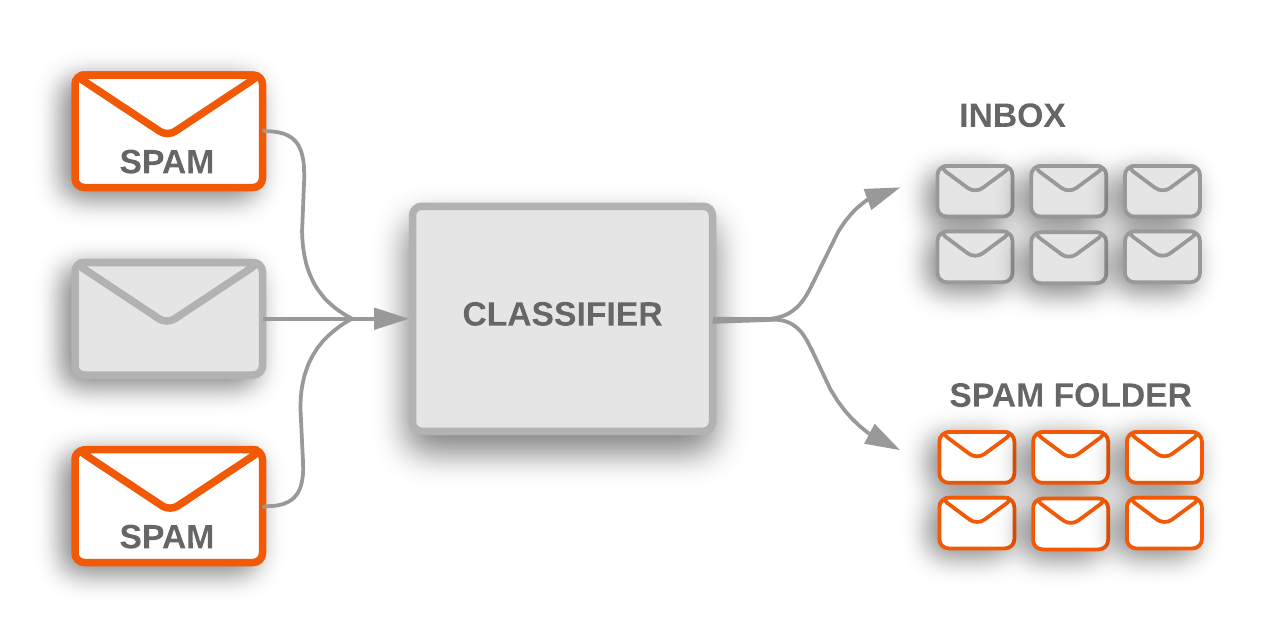
그림 1: 주제 분류를 사용하면 수신 스팸 이메일을 신고하여 스팸 폴더로 필터링합니다.
또 다른 일반적인 텍스트 분류 유형은 감정 분석으로, 텍스트 콘텐츠의 양극성, 즉 콘텐츠가 표현하는 의견의 유형을 파악하는 것이 목표입니다. 이는 바이너리 좋아요/싫어요 평점 또는 1~5까지의 별표 평점 등 더 세분화된 옵션의 형태를 취할 수 있습니다. 감정 분석의 예로는 트위터 게시물을 분석하여 사람들이 블랙 팬서 영화를 좋아했는지 확인하거나, 월마트 리뷰에서 신제품 Nike 신발에 대한 일반 대중의 의견을 추정한 경우를 들 수 있습니다.
이 가이드에서는 텍스트 분류 문제를 해결하기 위한 몇 가지 주요 머신러닝 권장사항을 설명합니다. 학습할 내용은 다음과 같습니다.
- 머신러닝을 사용한 텍스트 분류 문제 해결을 위한 고급 엔드 투 엔드 워크플로
- 텍스트 분류 문제에 적합한 모델을 선택하는 방법
- TensorFlow를 사용하여 선택한 모델을 구현하는 방법
텍스트 분류 워크플로
다음은 머신러닝 문제를 해결하는 데 사용하는 워크플로를 간략히 설명합니다.

그림 2: 머신러닝 문제 해결 워크플로
다음 섹션에서는 각 단계를 자세히 설명하고 텍스트 데이터에 이를 구현하는 방법을 설명합니다.