Алгоритмы классификации текста лежат в основе множества программных систем, которые обрабатывают текстовые данные в больших масштабах. Программное обеспечение электронной почты использует классификацию текста, чтобы определить, отправляется ли входящее письмо в папку «Входящие» или фильтруется в папку «Спам». Дискуссионные форумы используют классификацию текста, чтобы определить, следует ли помечать комментарии как неприемлемые.
Это два примера классификации тем, которые относят текстовый документ к одной из заранее определенных тем. Во многих задачах классификации тем эта категоризация основана в первую очередь на ключевых словах в тексте.
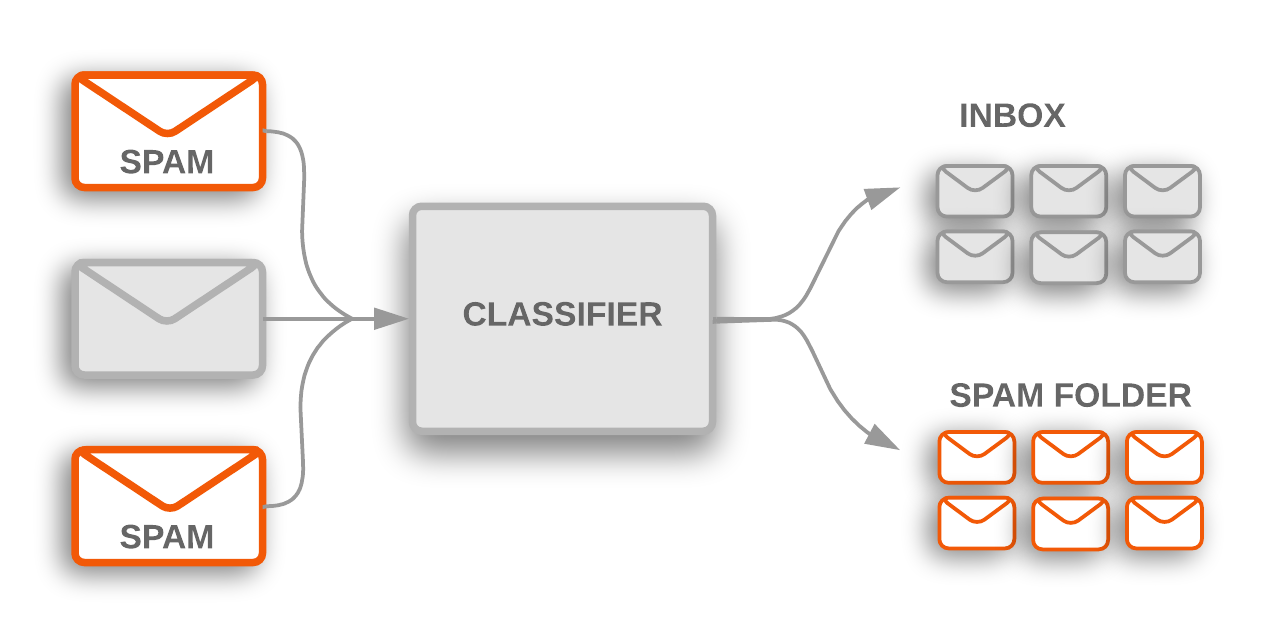
Рисунок 1. Классификация тем используется для пометки входящих спам-сообщений, которые фильтруются в папку со спамом.
Еще одним распространенным типом классификации текста является анализ настроений , целью которого является выявление полярности текстового контента: типа мнения, которое он выражает. Это может принимать форму двоичного рейтинга «нравится/не нравится» или более детального набора параметров, например звездного рейтинга от 1 до 5. Примеры анализа настроений включают анализ сообщений в Твиттере, чтобы определить, понравился ли людям фильм «Черная пантера» или экстраполируя мнение широкой публики о новой марке обуви Nike из обзоров Walmart.
Это руководство научит вас некоторым ключевым передовым практикам машинного обучения для решения задач классификации текста. Вот что вы узнаете:
- Высокоуровневый комплексный рабочий процесс для решения задач классификации текста с использованием машинного обучения.
- Как выбрать правильную модель для вашей задачи классификации текста
- Как реализовать выбранную вами модель с помощью TensorFlow
Рабочий процесс классификации текста
Вот общий обзор рабочего процесса, используемого для решения проблем машинного обучения:
- Шаг 1: Сбор данных
- Шаг 2. Изучите свои данные
- Шаг 2.5: Выберите модель*
- Шаг 3. Подготовьте данные
- Шаг 4. Создайте, обучите и оцените свою модель
- Шаг 5. Настройте гиперпараметры
- Шаг 6. Разверните свою модель

Рисунок 2. Рабочий процесс решения задач машинного обучения.
В следующих разделах подробно объясняется каждый шаг и то, как его реализовать для текстовых данных.