文本分类算法是大规模处理文本数据的各种软件系统的核心。电子邮件软件使用文本分类来确定传入的邮件是发送到收件箱还是过滤到垃圾邮件文件夹。论坛使用文本分类来确定是否应将评论标记为不当内容。
这是主题分类的两个示例,它们将文本文档分为一组预定义的主题。在许多主题分类问题中,这种分类主要基于文本中的关键字。
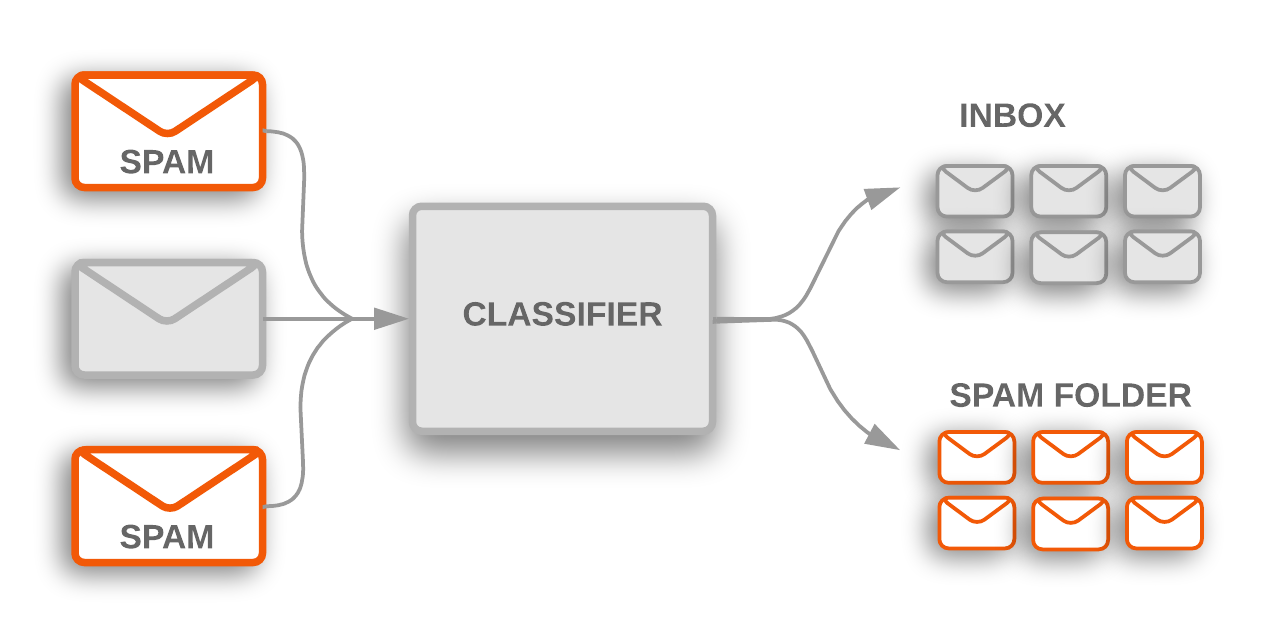
图 1:主题分类用于标记收到的垃圾邮件,这些邮件会被过滤到垃圾邮件文件夹中。
另一种常见的文本分类类型是情感分析,其目标是识别文本内容的两极性:它所表达的观点类型。这可以采用“喜欢/不喜欢”这样的二元评分形式,或者一组更细化的选项,例如星级(从 1 到 5)。情感分析的示例包括分析 Twitter 帖子以确定人们是否喜欢《黑豹》电影,或利用一般消费者对沃尔玛新款耐克鞋的观点进行推断。
本指南将向您介绍解决文本分类问题的一些关键机器学习最佳做法。您将学习以下内容:
- 使用机器学习解决文本分类问题的端到端端到端工作流
- 如何针对文本分类问题选择合适的模型
- 如何使用 TensorFlow 实现所选模型
文本分类工作流
下面是用于解决机器学习问题的工作流的简要概览:

图 2:解决机器学习问题的工作流程
以下部分详细介绍了每个步骤,以及如何针对文本数据实现这些步骤。