Los algoritmos de clasificación de texto son el centro de una variedad de sistemas de software que procesan datos de texto a gran escala. El software de correo electrónico usa la clasificación de texto para determinar si el correo electrónico entrante se envía a Recibidos o se filtra en la carpeta de spam. Los foros de discusión usan la clasificación de texto para determinar si los comentarios deben marcarse como inapropiados.
Estos son dos ejemplos de clasificación de temas, que categorizan un documento de texto en uno de un conjunto predefinido de temas. En muchos problemas de clasificación de temas, esta categorización se basa principalmente en las palabras clave del texto.
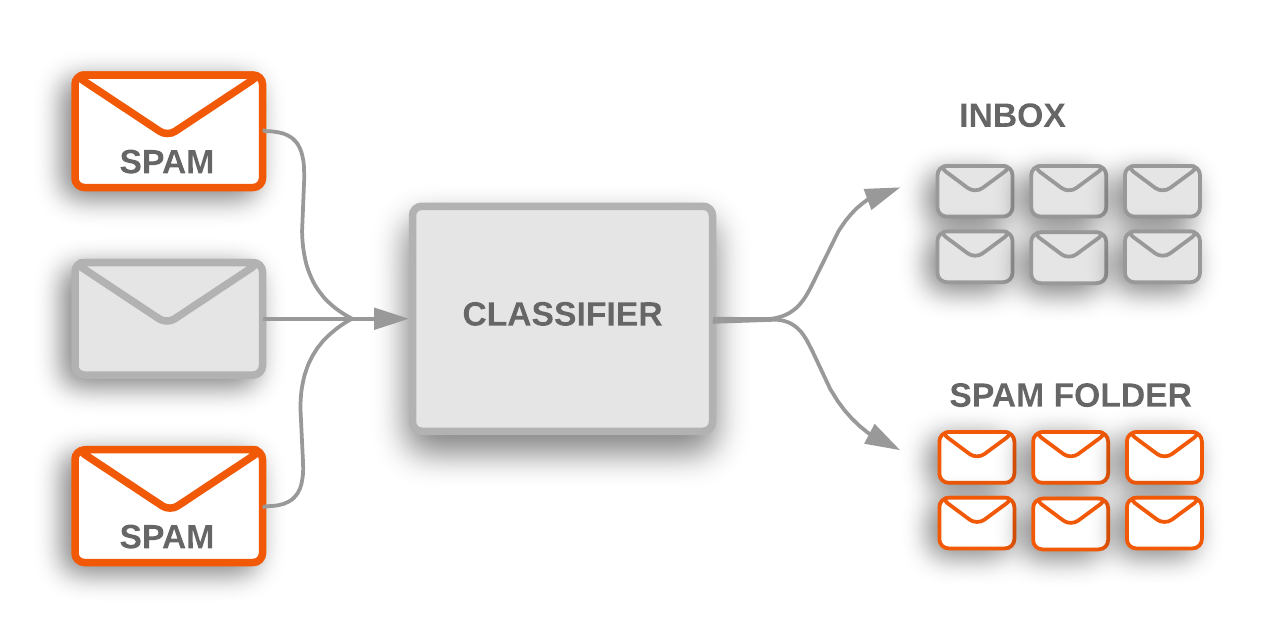
Figura 1: La clasificación del tema se usa para marcar los correos electrónicos de spam entrantes, que se filtran en una carpeta de spam.
Otro tipo común de clasificación de texto es el análisis de opiniones, cuyo objetivo es identificar la polaridad del contenido del texto: el tipo de opinión que expresa. Esto puede tener la forma de una calificación binaria con “Me gusta” o “No me gusta”, o un conjunto más detallado de opciones, como una calificación por estrellas del 1 al 5. Algunos ejemplos de análisis de opiniones incluyen analizar las publicaciones en Twitter para determinar si a la gente le gustó la película de Pantera Negra o extrapolar la opinión del público general sobre una marca nueva de calzado Nike a partir de las opiniones de Walmart.
En esta guía, aprenderás algunas prácticas recomendadas sobre el aprendizaje automático. A continuación, le indicamos qué aprenderá:
- Flujo de trabajo integral de alto nivel para resolver problemas de clasificación de texto
- Cómo elegir el modelo correcto para tu problema de clasificación de texto
- Cómo implementar el modelo que prefieras con TensorFlow
Flujo de trabajo de clasificación de texto
Esta es una descripción general de alto nivel del flujo de trabajo que se usa para resolver problemas de aprendizaje automático:
- Paso 1: Recopila datos
- Paso 2: Explora tus datos
- Paso 2.5: Elige un modelo*
- Paso 3: Prepare sus datos
- Paso 4: Compila, entrena y evalúa tu modelo
- Paso 5: Ajusta los hiperparámetros
- Paso 6: Implementa tu modelo

Figura 2: Flujo de trabajo para resolver problemas de aprendizaje automático
En las siguientes secciones, se explica cada paso en detalle y cómo implementarlos en los datos de texto.