Ngành chăm sóc sức khoẻ dựa trên dữ liệu dựa vào khả năng nhanh chóng tạo ra thông tin chi tiết đáng tin cậy và có thể hành động.
Mặc dù tiêu chuẩn FHIR mang lại nhiều lợi ích cho các nhà phát triển xây dựng giải pháp y tế kỹ thuật số thế hệ mới, nhưng cấu trúc lồng nhau quá mức của tiêu chuẩn này có thể gây khó khăn cho việc phân tích.
Để giúp nhà phát triển dễ dàng xây dựng các giải pháp giúp giảm bớt sự phức tạp khi làm việc với dữ liệu FHIR, chúng tôi cung cấp FHIR Data Pipes (Kênh dữ liệu FHIR), một bộ công cụ: quy trình ETL để chuyển đổi tài nguyên thành giản đồ Parquet-on-FHIR, lớp định nghĩa chế độ xem và trình kết nối công cụ truy vấn.
FHIR Data Pipes được thiết kế để có khả năng mở rộng theo chiều ngang và các tuỳ chọn triển khai linh hoạt (tại chỗ hoặc trên đám mây). Đồng thời, bạn có thể triển khai trên một máy duy nhất.
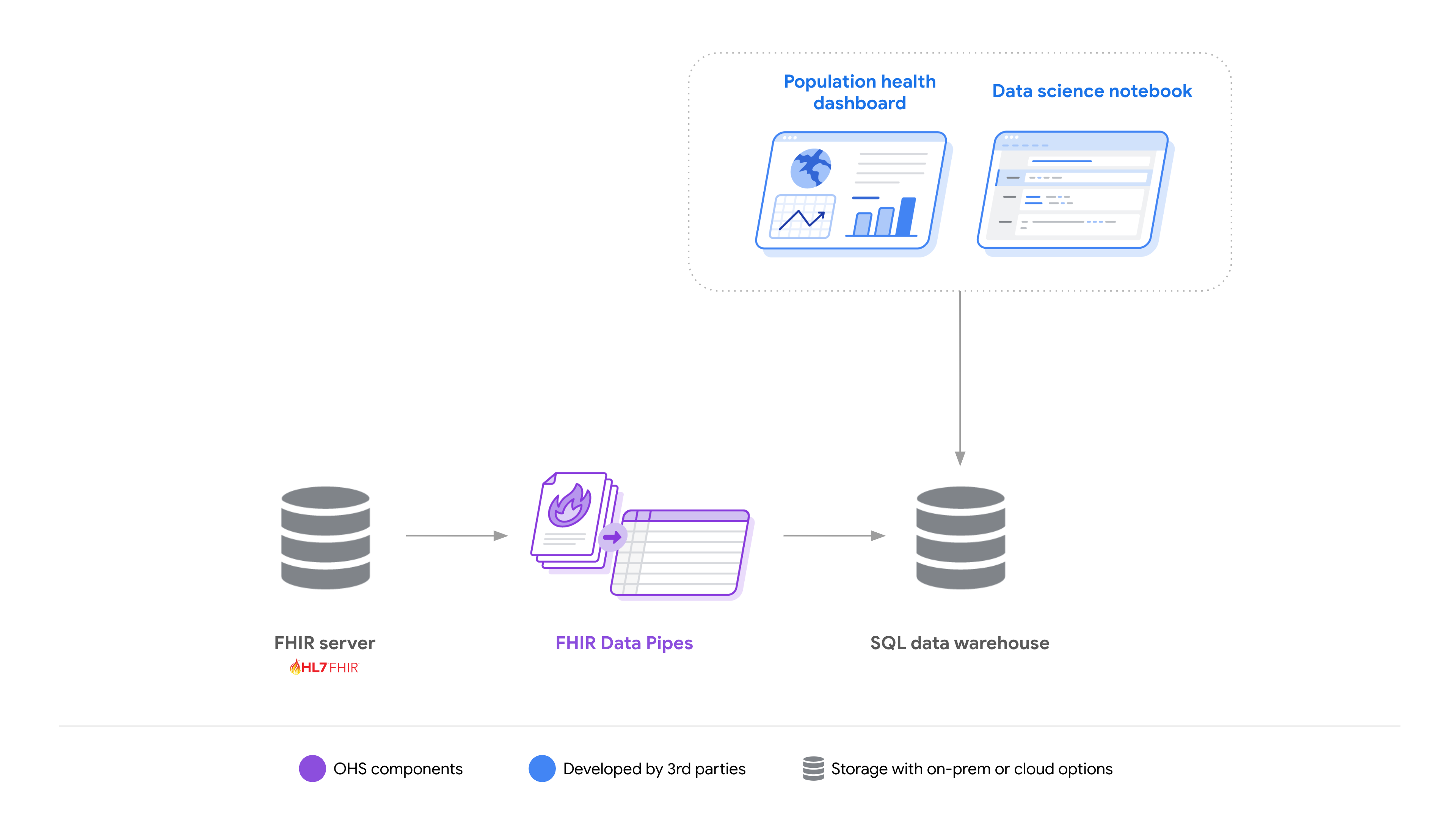
Nhờ đó, các nhà phát triển có thể dễ dàng xây dựng và triển khai các giải pháp phân tích bằng nhiều công nghệ cho nhiều trường hợp sử dụng.
Tìm hiểu thêm về Quy trình dữ liệu FHIR và các thành phần của quy trình này: