Wenn Sie aggregierbare Berichte im Batch-Verfahren erstellen, sollten Sie die Batch-Strategien so optimieren, dass die Datenschutzlimits nicht überschritten werden. Im Folgenden finden Sie einige empfohlene Strategien für das Senden von Berichtsbatches an den Aggregationsdienst.
Meldungen erfassen
Beachten Sie beim Erstellen von Berichten für einen Batch Folgendes:
Upload-Wiederholungsversuche melden
Hinweis:Die Kriterien für Wiederholungen können sich ändern. Die Informationen in diesem Abschnitt werden in diesem Fall aktualisiert.
Sowohl auf der Web- als auch auf der Betriebssystemplattform versucht eine Plattform dreimal, den Bericht zu senden. Wenn der Bericht nach dem dritten Versuch jedoch nicht gesendet werden kann, wird er nicht gesendet. Der ursprüngliche Wert scheduled_report_time wird beibehalten, unabhängig davon, wann der Bericht gesendet werden kann. Der Zeitplan für Wiederholungen unterscheidet sich je nach Plattform:
- Ein Webbrowser sendet Berichte, wenn er online ist. Wenn der Bericht nicht gesendet werden kann, wird fünf Minuten auf den zweiten Versuch gewartet und dann 15 Minuten auf den dritten. Wenn der Browser offline geht, erfolgt der nächste Wiederholungsversuch eine Minute, nachdem er wieder online ist. Beim Senden von Berichten im Web gibt es keine maximale Verzögerung. Das bedeutet, dass der Bericht unabhängig davon, wie lange er zuvor erstellt wurde, nach der Wiederherstellung der Internetverbindung gemäß der Wiederauffrufrichtlinie gesendet wird.
- Ein Android-Smartphone hat eine stabile Netzwerkverbindung. Der Job zum Senden von Berichten wird also einmal pro Stunde ausgeführt. Wenn ein Bericht also nicht gesendet werden kann, wird der Versand in der nächsten Stunde und in der darauffolgenden Stunde noch einmal versucht. Wenn das Gerät keine Verbindung hat, versucht es, den Bericht mit dem nächsten Berichtsjob noch einmal zu senden, der ausgeführt wird, nachdem das Gerät wieder mit dem Netzwerk verbunden ist. Die maximale Verzögerung beträgt 28 Tage. Das bedeutet, dass das Gerät keinen Bericht sendet, der vor mehr als 28 Tagen generiert wurde.
Auf Berichte warten
Wir empfehlen, beim Erfassen von Berichten für die Batchverarbeitung auf verspätet zugestellte Berichte zu warten. Verspätete Berichte können anhand des Werts für scheduled_report_time ermittelt werden, der dem Zeitpunkt des Eingangs des Berichts entspricht. Anhand der Zeitdifferenz zwischen diesen Berichten können Sie besser einschätzen, wie lange Sie auf verspätete Berichte warten sollten. Wenn Sie beispielsweise verzögerte Berichte erfassen, sehen Sie im Feld scheduled_report_time nach, wie lange es gedauert hat, bis 90%, 95 % und 99% der Berichte eingegangen sind. Anhand dieser Daten lässt sich ermitteln, wie lange auf verspätete Berichte gewartet werden muss.
Mit sofort zusammengefassten Berichten können Sie die Wahrscheinlichkeit von verzögerten Berichten verringern.
Die folgende Abbildung zeigt, wie spät ankommende Berichte entsprechend der geplanten Berichtszeit in den entsprechenden Batches gespeichert werden. „Batch T“ steht für scheduled_report_time und „T+X“ für die Wartezeit auf verzögerte Berichte. Dies führt zu einem Zusammenfassungsbericht, der den Großteil der Berichte enthält, die im Batch enthalten sind und der der geplanten Berichtszeit entspricht.
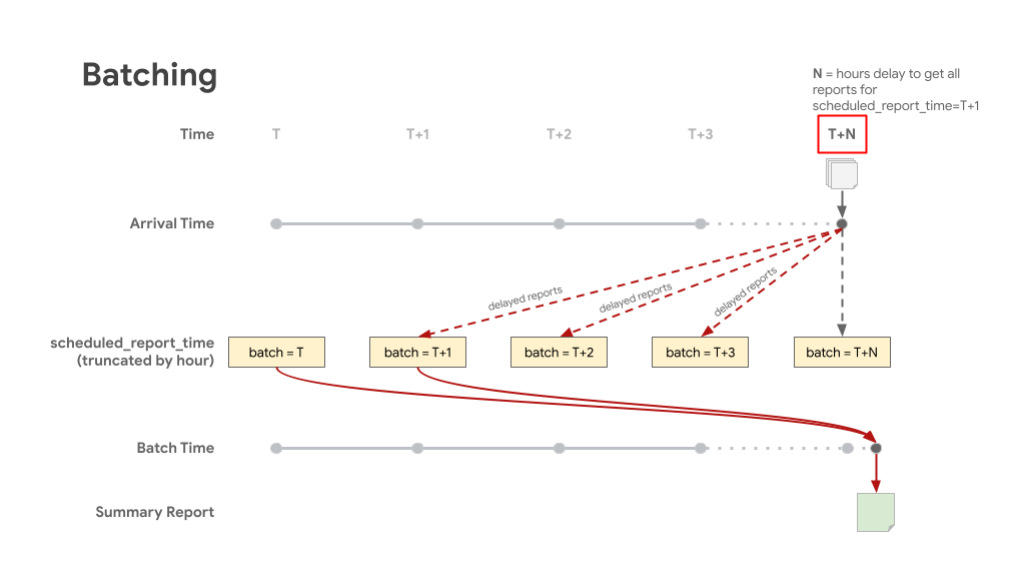
Aggregierbare Berichte
Der Aggregationsdienst achtet auf die Regel „Keine Duplikate“. Diese Regel erzwingt, dass alle aggregierbaren Berichte mit derselben freigegebenen ID im selben Batch enthalten sein müssen.
Nach dem Erfassen sollten die Berichte so gruppiert werden, dass alle Berichte mit derselben gemeinsamen ID zu einem Batch gehören.
Wenn ein Bericht bereits in einem anderen Batch verarbeitet wurde, kann die Verarbeitung zu einem Fehler aufgrund eines erschöpften Datenschutzbudgets führen. Die korrekte Batchverarbeitung von Berichten verhindert, dass Batches aufgrund der Regel "Keine Duplikate" abgelehnt werden.
Eine gemeinsame ID ist ein Schlüssel, der für jeden Bericht generiert wird, um die aggregierbare Berichtserfassung zu verfolgen. Die gemeinsame ID sorgt dafür, dass Berichte mit derselben gemeinsamen ID nur zu einem zusammengefassten Bericht beitragen. Das bedeutet, dass alle Berichte, die einer gemeinsamen ID zugeordnet sind, in einem einzigen Batch enthalten sein müssen. Wenn Bericht X und Bericht Y beispielsweise dieselbe gemeinsame ID haben, müssen sie in denselben Batch aufgenommen werden, damit Berichte nicht wegen Duplizierung verworfen werden.
In der folgenden Abbildung sehen Sie die shared_info-Komponenten, die zum Generieren einer gemeinsamen ID gehasht werden.
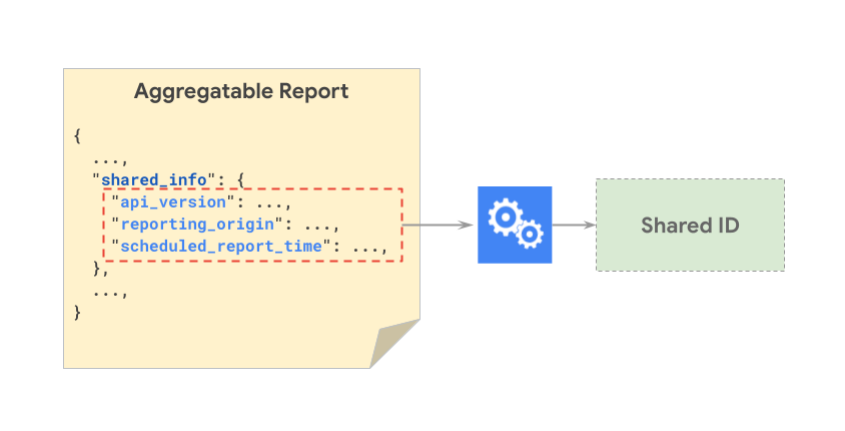
In der folgenden Abbildung sehen Sie, wie zwei verschiedene Berichte dieselbe gemeinsame ID haben können:

Hinweis:scheduled_report_time wird auf die Stunde und source_registration_time auf den Tag genau gekürzt. Außerdem wird report_id nicht für die Erstellung freigegebener IDs verwendet. Die Zeitauflösung kann in Zukunft aktualisiert werden.
Berichte innerhalb von Batches duplizieren
Das Feld shared_info in einem aggregierbaren Bericht enthält eine UUID im Feld report_id, mit der sich doppelte Berichte in einem Batch identifizieren lassen. Wenn ein Batch mehrere Berichte mit derselben report_id enthält, wird nur der erste Bericht zusammengefasst. Die anderen werden als Duplikate betrachtet und ohne Meldung entfernt. Die Aggregation wird wie gewohnt fortgesetzt und es werden keine Fehler gesendet.
Es ist zwar nicht erforderlich, aber Anbieter von Anzeigentechnologien können mit einer Leistungssteigerung rechnen, wenn sie vor der Aggregation doppelte Berichte mit denselben Berichts-IDs herausfiltern.
Die report_id ist für jeden Bericht eindeutig.
Berichte für mehrere Batches duplizieren
Jedem Bericht wird eine gemeinsame ID zugewiesen. Diese ID wird aus kombinierten Datenpunkten generiert, die aus dem Feld shared_info des Berichts stammen. Mehrere Berichte können dieselbe ID haben und jeder Batch kann mehrere gemeinsame IDs enthalten. Alle Berichte mit derselben freigegebenen ID müssen demselben Batch zugeordnet werden. Wenn Berichte mit derselben gemeinsamen ID in mehrere Batches aufgenommen werden, wird nur der erste Batch akzeptiert und die anderen als Duplikate abgelehnt. Um dies zu vermeiden, müssen Batches richtig erstellt werden.
Die folgende Abbildung zeigt ein Beispiel, in dem Berichte mit derselben freigegebenen ID in mehreren Batches dazu führen können, dass der spätere Batch fehlschlägt. In der Abbildung sehen Sie, dass zwei oder mehr Berichte mit derselben gemeinsamen ID e679aa in verschiedenen Batches 1 und 2 zusammengefasst werden. Da das Budget für alle Berichte mit der gemeinsamen ID e679aa bei der Generierung des Zusammenfassungsberichts für Batch 1 aufgebraucht ist, ist Batch 2 nicht zulässig und schlägt mit einem Fehler fehl.
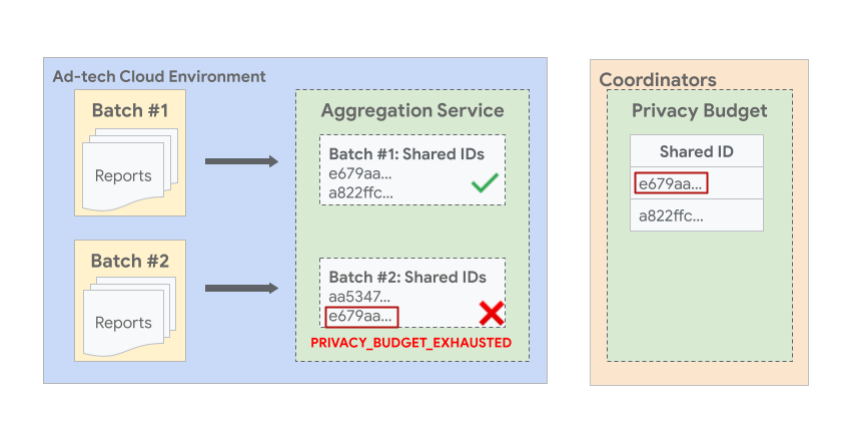
Batchberichte
Im Folgenden finden Sie empfohlene Methoden zum Erstellen von Berichtspaketen, um Duplikate zu vermeiden und die Abrechnung zusammengefasster Berichte zu optimieren.
Batch nach Werbetreibendem
Hinweis:Diese Strategie wird nur für die Aggregation von Attributionsberichten empfohlen.
Die private Aggregation hat kein attribution_destination-Feld, bei dem es sich um den Werbetreibenden handelt. Wir empfehlen, Berichte nach Werbetreibenden zu gruppieren, d. h. Berichte für einen einzelnen Werbetreibenden in denselben Batch aufzunehmen, um das Limit für aggregierbare Berichte pro Batch zu vermeiden. „Werbetreibender“ ist ein Feld, das bei der Generierung der freigegebenen ID berücksichtigt wird. Daher können Berichte mit demselben Werbetreibenden dieselbe freigegebene ID haben. Um Fehler zu vermeiden, müssen sie sich also im selben Batch befinden.
Batch nach Zeit
Es wird empfohlen, bei der Batchverarbeitung den für den Bericht geplanten Zeitpunkt des Berichts (shared_info.scheduled_report_time) zu berücksichtigen. Die Zeit für geplante Berichte wird bei der Generierung der gemeinsamen ID auf die Stunde gekürzt. Daher sollten Berichte mindestens in stündlichen Intervallen zusammengefasst werden. Das bedeutet, dass alle Berichte mit derselben geplanten Berichtszeit innerhalb derselben Stunde in denselben Batch aufgenommen werden sollten, um Berichte mit derselben gemeinsamen ID in mehreren Batches zu vermeiden, was zu Jobfehlern führt.
Batchhäufigkeit und Rauschen
Es wird empfohlen, die Auswirkung von Abweichungen auf die Häufigkeit der Verarbeitung von aggregierten Berichten zu berücksichtigen. Wenn aggregierbare Berichte häufiger in Batches verarbeitet werden, z. B. einmal pro Stunde, werden weniger Conversion-Ereignisse berücksichtigt und Abweichungen haben einen größeren relativen Einfluss. Wenn die Häufigkeit verringert und Berichte einmal pro Woche verarbeitet werden, haben Störfaktoren eine geringere relative Auswirkung. Experimentieren Sie mit dem Noise Lab, um die Auswirkungen von Rauschen auf Batches besser zu verstehen.