El servicio de agregación genera informes de resumen de datos de conversiones detallados y mediciones de alcance a partir de informes agregables sin procesar. Las tecnologías publicitarias tienen dos puntos de entrada agregados principales del cliente para canalizar informes al servicio de agregación, ya sea a través de la API de Attribution Reporting o de la API de Private Aggregation.
Estado de implementación
- El servicio de agregación ahora tiene disponibilidad general.
- El servicio de agregación se puede usar con la API de Attribution Reporting y la API de Private Aggregation para la API de Protected Audience y la API de Shared Storage.
Disponibilidad
| 提案 | 状态 |
|---|---|
| 跨云隐私预算服务
说明 |
可用 |
| 针对 Attribution Reporting API、Private Aggregation API 中的 Amazon Web Services (AWS) 提供汇总服务支持
说明 |
可用 |
| 针对 Attribution Reporting API、Private Aggregation API 的 Google Cloud 汇总服务支持 说明 |
可用 |
| 汇总服务网站注册和多源汇总。网站注册包括将网站映射到云账号(AWS 或 GCP)。如需汇总多个来源,这些来源必须属于同一网站。
GitHub 上的常见问题解答 Site aggregation API 文档 |
可用 |
| 汇总服务的 epsilon 值将保持在 64 以内的范围内,以便对不同的参数进行实验和反馈。
提交 ARA 小数值反馈。 提交 PAA 小样本误差反馈。 |
可用。在更新 epsilon 范围值之前,我们会提前通知生态系统。 |
| 为汇总服务查询提供了更灵活的贡献过滤功能
解说 |
可用 |
| 灾难发生后(错误、配置错误等)预算恢复流程
说明 |
可用 机制,用于查看广告技术平台使用预算恢复功能恢复的共享 ID 的百分比,并暂停计划在 2025 年上半年过度恢复的未来恢复 |
| Accenture 是 AWS 协调者之一
开发者博客 |
可用 |
| 作为 Google Cloud 协调者之一的独立方
开发者博客 |
可用 |
| 汇总服务对 Attribution Reporting API 上的汇总调试报告的支持
说明 |
可用 |
Términos y conceptos clave
Si estás considerando usar el servicio de agregación en tu flujo de trabajo de tecnología publicitaria, los siguientes términos y conceptos deberían brindarte más información sobre lo que este nuevo flujo de agregación puede ofrecer a tu equipo:
| 术语 | 说明 |
|---|---|
| 汇总服务 | 由广告技术平台运营的服务,用于处理可汇总报告以创建摘要报告。 |
| 可汇总的报告 |
Los informes agregables son informes encriptados que se envían desde dispositivos de usuarios individuales. Estos informes contienen datos sobre el comportamiento y las conversiones de los usuarios en diferentes sitios. El anunciante o la tecnología publicitaria definen las conversiones (a veces llamadas eventos de activación de atribución) y las métricas asociadas. Cada informe se encripta para evitar que varias partes accedan a los datos subyacentes. 详细了解可汇总的报告。 |
| 可汇总报告的会计核算 | 位于两个协调器中的分布式账本,用于跟踪分配的隐私预算并强制执行“无重复”规则。这是一种隐私保护机制,位于协调者中并在其中运行,可确保通过汇总服务传递的报告不会超出分配的隐私预算。 详细了解批处理策略与可汇总报告的关系。 |
| 可汇总报告的会计核算预算 | 对预算的引用,用于确保报告不会被处理多次。 |
| 可信执行环境 (TEE) |
Un entorno de ejecución confiable es una configuración especial de hardware y software informático que permite a terceros verificar las versiones exactas del software que se ejecuta en la computadora. TEEs permite que terceros verifiquen que el software hace exactamente lo que un fabricante de software afirma que sí lo hace, nada más o menos. Para obtener más información sobre los TEE que se usan para las propuestas de Privacy Sandbox, lee la explicación de los servicios de la API de Protected Audience y la explicación del servicio de agregación. |
| 协调员 |
协调者是负责密钥管理和可汇总报告的会计核算的实体。协调者维护已获批准的汇总服务配置的哈希列表,并配置对解密密钥的访问权限。 |
| 共享 ID |
计算值,由以下各项组成:shared_info、reporting_origin、destination_site(仅适用于 Attribution Reporting API)、source_registration-time(仅适用于 Attribution Reporting API)、scheduled_report_time、version。
这意味着,如果多个报告具有相同的 shared_info 字段属性,则它们属于同一共享 ID。这在可汇总报告会计中起着重要作用。
详细了解可信服务器。
|
| 汇总报告 |
Un informe de resumen es un tipo de informe de la API de Attribution Reporting y la API de Private Aggregation. Un resumen incluye datos agregados del usuario y puede tener datos de conversiones detallados con ruido agregado. Los informes de resumen se componen de informes agregados. Los informes de resumen permiten una mayor flexibilidad y un modelo de datos más rico que los informes a nivel del evento, en particular para algunos casos de uso, como los valores de conversión. |
| 举报来源 |
报告来源是接收可汇总报告的实体,也就是调用 Attribution Reporting API 的广告技术平台。可汇总报告的来源 将用户设备转到与报告关联的已知网址 来源。此报告来源应在注册期间指定。 |
| 贡献债券 | 可汇总的报告可以包含任意数量的计数器增量。例如,报告中可能包含用户在广告客户网站上查看过的商品数量。与单个来源事件相关的所有可汇总报告中的增量之和不得超过给定限制“L1=2^16”。 如需了解详情,请参阅可汇总报告说明。 |
| 噪声和缩放 | 在汇总过程中,系统会向摘要报告添加一定量的统计噪声,这也有助于保护隐私并确保最终报告提供匿名化效果衡量信息。详细了解加法噪声机制,该机制是从拉普拉斯分布中提取的。 |
| 证明 |
认证是一种用于对软件身份进行身份验证的机制,通常使用加密哈希或签名。对于汇总服务方案,证明会将广告技术平台运营的汇总服务中运行的代码与开放源代码进行匹配。 详细了解证明。 |
Obtén más información sobre los antecedentes del servicio de agregación en nuestra explicación y la lista completa de condiciones.
Casos de uso de agregación
Ten en cuenta los siguientes recorridos de los desarrolladores para la medición de anuncios y sus bibliotecas cliente de medición correspondientes.
| Caso de uso | Punto de entrada | Descripción |
|---|---|---|
| Optimización de ofertas | API de Attribution Reporting (Chrome y Android) | Utiliza informes agregados para transferir indicadores de conversión con el objetivo de optimizar las ofertas. |
| Medición multiplataforma | API de Attribution Reporting (Chrome y Android) | Usa las capacidades de medición en la Web y en las aplicaciones para obtener visibilidad del rendimiento en Chrome y Android. |
| Informes de conversiones | API de Attribution Reporting (Chrome y Android) | Crea informes de conversiones agregados adaptados a las necesidades de las campañas de los clientes (incluye las CTC y las VTC). |
| Medición del alcance de la campaña | API de Storage compartido y API de agregación privada (Chrome) | Usa las variables de vistas de anuncios entre sitios para medir el alcance de la campaña. |
| Informes demográficos | API de Storage compartido y API de agregación privada (Chrome) | Utiliza la vista de anuncios entre sitios y la información demográfica para medir el alcance por datos demográficos. |
| Análisis de la ruta de conversión | API de Storage compartido y API de agregación privada (Chrome) | Almacena las vistas de anuncios y las variables de conversión entre sitios para realizar un análisis agregado de la ruta de conversión. |
| Efectividad de conversiones y de marca | API de Storage compartido y API de agregación privada (Chrome) | Informes sobre grupos de prueba y control, y sobre la información de sondeo para medir el aumento de la marca y la incrementalidad |
| Depuración de subastas | API de Protected Audience y API de Private Aggregation (Chrome) | Usa informes agregados para depurar. |
| Distribución de ofertas | API de Protected Audience y API de Private Aggregation (Chrome) | Usa informes agregados para capturar la distribución de los valores de oferta de las subastas. |
Flujo de extremo a extremo
En el siguiente diagrama, se muestra el servicio de agregación en acción. Nos enfocaremos en el flujo de extremo a extremo, desde la recepción de los informes de la Web y los dispositivos móviles hasta la creación de los informes de resumen en el servicio de agregación.
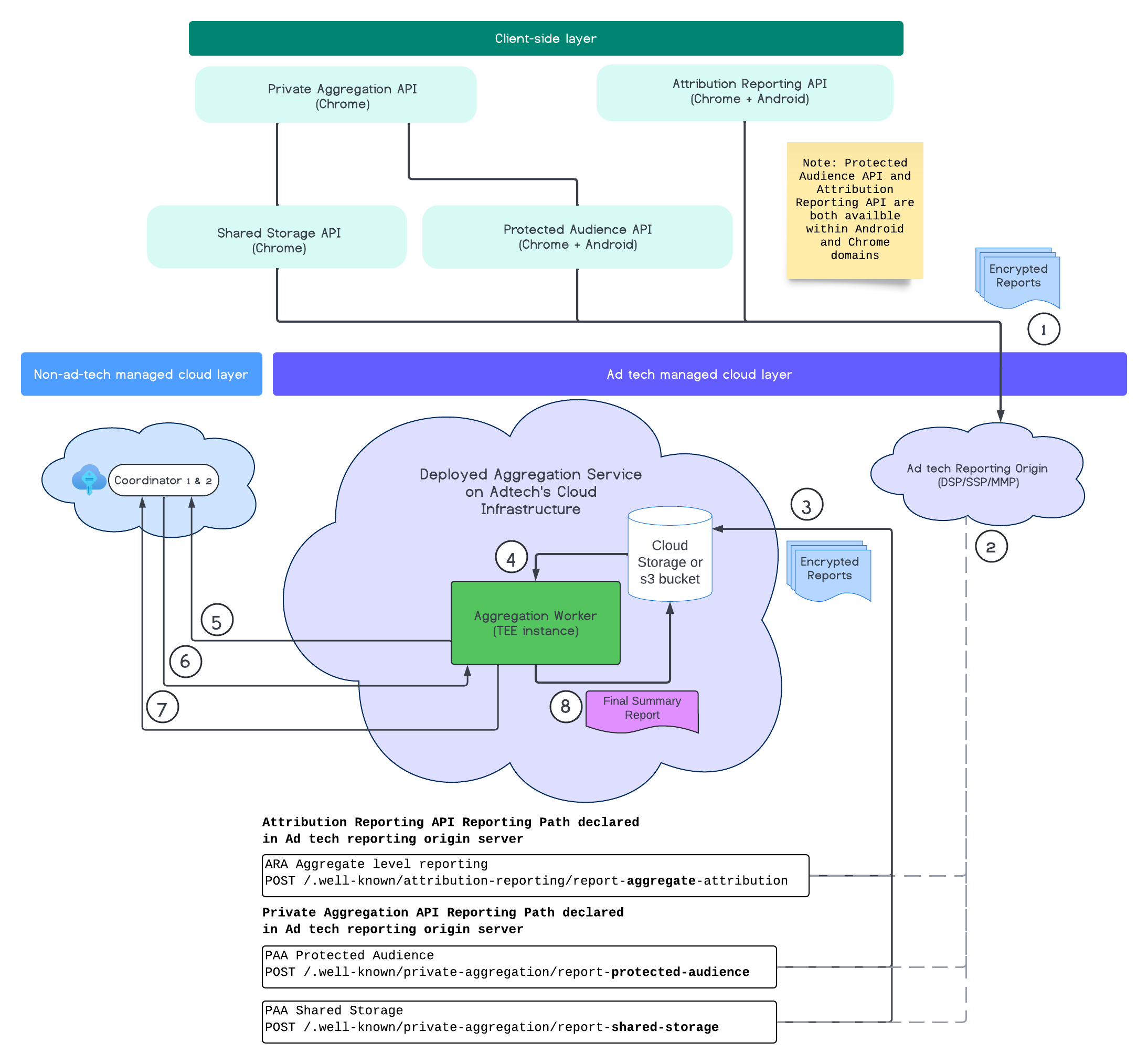
- Recupera la clave pública para generar informes encriptados.
- Informes agregables encriptados que se envían a los servidores de tecnología publicitaria para que se recopilen, transformen y agrupen.
- El servidor de tecnología publicitaria agrupa los informes (en formato avro) y los envía al servicio de agregación implementado. (La tecnología publicitaria debe completar este paso).
- Recuperar informes agregados para desencriptarlos
- Recupera claves de desencriptación de los coordinadores.
- El servicio de agregación desencripta los informes para la agregación y la contaminación.
- El servicio de contabilidad de informes agregables verifica si queda algún presupuesto de privacidad para generar un informe de resumen de los informes agregables determinados.
- Envía el informe de resumen final.
En el diagrama, puedes ver la relación general que tiene el servicio de agregación con las principales APIs de medición de clientes API de Attribution Reporting, API de Private Aggregation y coordinadores.
El flujo comienza con diferentes APIs de medición, como la API de Attribution Reporting o la API de Private Aggregation, que generan informes a partir de varias instancias de navegador. Chrome toma la clave pública del servicio de alojamiento de claves en el coordinador para encriptar los informes antes de que se envíen al origen de informes de la tecnología publicitaria. Las claves públicas se rotan cada siete días.
Una vez que el origen de informes de la tecnología publicitaria recibe estos informes, se debe configurar para recopilarlos y convertirlos al formato avro, y enviarlos a la instancia del servicio de agregación implementada. Consulta las estrategias de lotes.
Una vez que la tecnología publicitaria esté lista para procesarse por lotes, creará una solicitud por lotes al servicio de agregación, en la que se desencriptarán los informes mediante la recuperación de las claves de desencriptación del servicio de alojamiento de claves, y se agregarán y se agregarán ruidos para crear un informe de resumen. Ten en cuenta que esto depende de si hay suficiente presupuesto de privacidad para generar los informes de resumen finales.
La tecnología publicitaria aloja el extremo de origen de informes donde se recopilan los informes, y el servicio de agregación se implementa en la nube de la tecnología publicitaria.
Procesamiento por lotes de informes agregables
El flujo de informes no estaría completo sin la ayuda del servidor de origen de informes designado. Este es el origen que una plataforma de tecnología publicitaria habría enviado en el proceso de inscripción. Las principales acciones de las que es responsable el origen de los informes son recopilar, transformar y agrupar los informes agregables recibidos y prepararlos para que se envíen al servicio de agregación implementado de la tecnología publicitaria en Google Cloud o Amazon Web Services. Obtén más información para preparar tus informes agregables.
Ahora que tienes el concepto general, observa con mayor detalle los componentes que se implementarán en tu servicio de agregación.
Componentes de la nube
El servicio de agregación consta de varios componentes de servicios en la nube. Las secuencias de comandos de Terraform proporcionadas aprovisionan y configuran todos los componentes necesarios de los servicios en la nube.
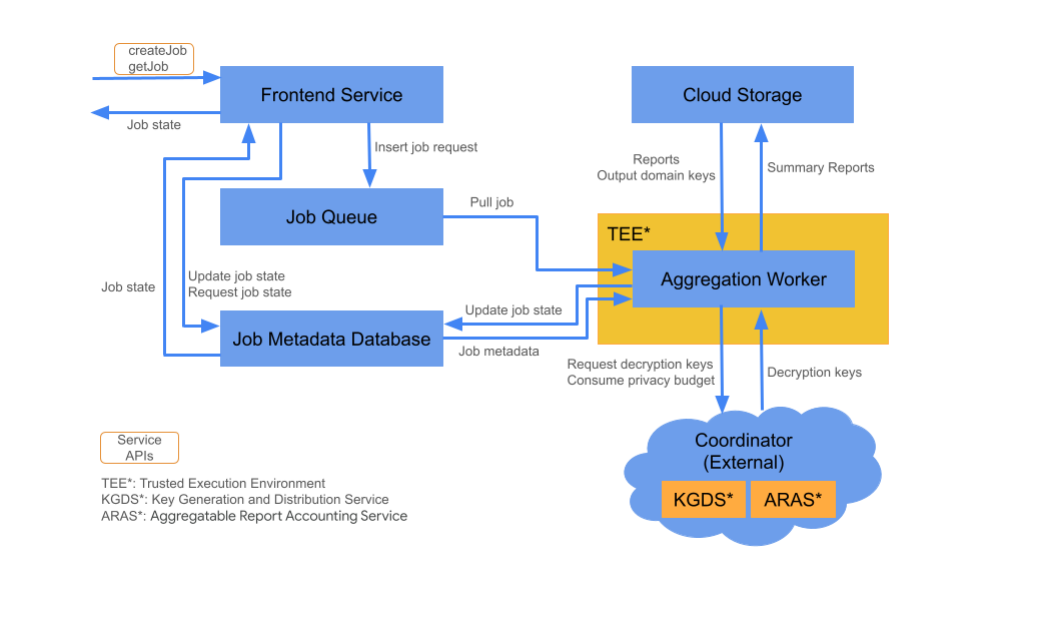
Servicio de frontend
Servicio en la nube administrado: Cloud Function (Google Cloud) o API Gateway (Amazon Web Services)
El servicio de frontend es una puerta de enlace sin servidores que funciona como punto de entrada para las llamadas a la API de Aggregation para la creación de trabajos y la recuperación de su estado. Es responsable de recibir solicitudes de los usuarios del servicio de agregación, validar los parámetros de entrada y comenzar el proceso de programación de tareas de agregación.
Hay dos APIs disponibles en el servicio de frontend:
| Extremo | Descripción |
|---|---|
createJob |
Esta API activa un trabajo del servicio de agregación. Requiere información para activar un trabajo, como el ID del trabajo, los detalles de almacenamiento de entrada, los detalles de almacenamiento de salida, el origen de los informes y mucho más. |
getJob |
Esta API muestra el estado de un trabajo para un ID de trabajo especificado. Proporciona información sobre el estado del trabajo, como "Recibido", "En curso" o "Finalizado". Además, si el trabajo está terminado, se muestra el resultado, incluidos los mensajes de error que se encontraron durante la ejecución. |
Consulta la documentación de la API de Aggregation Service.
Lista de tareas en cola
Servicio en la nube administrado: Pub/Sub (Google Cloud) o Amazon SQS (Amazon Web Services)
La lista de tareas en cola es una lista de mensajes que almacena solicitudes de trabajo para el servicio de agregación. El servicio de frontend inserta mensajes de solicitud de trabajo en la cola, que luego consume el trabajador de agregación para procesar la solicitud de trabajo.
Almacenamiento en la nube
Servicio en la nube administrado: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services) El almacenamiento en la nube se usa para almacenar archivos de entrada y salida que usa el servicio de agregación (por ejemplo, archivos de informes encriptados, informes de resumen de salida, etcétera).
Base de datos de metadatos de trabajos
Servicio de nube administrado: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
La base de datos de metadatos de trabajos almacena y realiza un seguimiento del estado de los trabajos de agregación. La base de datos registra metadatos, como la hora de creación, la hora solicitada, la hora de actualización y el estado (por ejemplo, Recibido, En curso, Finalizado, etcétera). El trabajador de agregación actualiza la base de datos de metadatos de trabajo a medida que avanza el trabajo.
Trabajador de agregación
Servicio de nube administrado: Compute Engine con espacio confidencial (Google Cloud) / Amazon Web Services EC2 con Nitro Enclave (Amazon Web Services)
El trabajador de agregación procesa las solicitudes de trabajo que inicia una solicitud de trabajo en la cola de trabajo y desencripta las entradas encriptadas con claves recuperadas del servicio de generación y distribución de claves (KGDS) en los coordinadores. Para minimizar la latencia de procesamiento de trabajos, las claves de desencriptación se almacenan en caché en el trabajador de agregación durante un período de 8 horas y se pueden usar en todos los trabajos que procesa esa instancia de trabajador.
El trabajador opera dentro de una instancia de entorno de ejecución confiable (TEE). Cada trabajador maneja solo un trabajo a la vez. La tecnología publicitaria puede configurar varios trabajadores para que procesen tareas en paralelo configurando el ajuste de escala automático. A través del ajuste de escala automático, la cantidad de trabajadores se ajusta de forma dinámica según la cantidad de mensajes que quedan en la cola de trabajos. La cantidad mínima y máxima de trabajadores para el ajuste de escala automático se puede configurar a través del archivo de entorno de Terraform. Puedes encontrar más información sobre el ajuste de escala automático en las siguientes secuencias de comandos de Terraform. [Amazon Web Services / Google Cloud]
El trabajador de agregación llama al servicio de contabilización de informes agregables para la contabilización de informes agregables. El servicio de contabilización de informes agregables se asegurará de que las tareas solo se ejecuten mientras no se haya excedido el límite del presupuesto de privacidad. (consulta la regla"Sin duplicados"). Si el presupuesto está disponible, se genera un informe de resumen con los agregados con ruido. Lee detalles adicionales sobre la contabilidad de informes agregables.
El trabajador de agregación actualiza los metadatos del trabajo en la base de datos de metadatos del trabajo, incluidos los códigos de devolución de trabajo adecuados y los contadores de errores de informes en caso de fallas parciales de informes. Los usuarios pueden recuperar el estado con la API de recuperación de estado de trabajo (getJob).
Para obtener una descripción más detallada del servicio de agregación, consulta nuestra explicación.
Próximos pasos
Ahora que conoces los aspectos más destacados del servicio de agregación, es hora de que implementes tu propia instancia del servicio de agregación a través de Google Cloud o Amazon Web Services. Consulta la sección de introducción o, si necesitas más información para operar un servicio de agregación implementado, sigue este vínculo para obtener más información sobre cómo operar el servicio de agregación.
Solución de problemas
Consulta nuestro documento Códigos de error y mitigaciones comunes para obtener descripciones más detalladas de los mensajes de error, lo que puede haber causado el error que tienes y los próximos pasos para mitigarlo.
Obtén asistencia y envía comentarios
- Si tienes preguntas sobre el producto, comentarios o solicitudes de funciones, crea un problema en nuestro repositorio de GitHub.
- Si tienes un error durante la implementación, el mantenimiento o la ejecución de trabajos con el servicio de agregación, utiliza este formulario de asistencia técnica para solicitar asistencia con la solución de problemas técnicos.
- Consulta el Panel de estado público para ver si hay problemas conocidos.