O serviço de agregação gera relatórios de resumo com dados detalhados de conversão e medições de alcance de relatórios agregáveis brutos. As adtechs têm dois pontos de entrada principais no lado do cliente para encaminhar relatórios ao serviço de agregação, seja pela API Attribution Reporting ou pela API Private Aggregation.
Status da implementação
- O Aggregation Service agora está disponível para todos os usuários.
- O Serviço de agregação pode ser usado com a API Attribution Reporting e a API Private Aggregation para a API Protected Audience e a API Shared Storage.
Disponibilidade
| Proposta | Status |
|---|---|
| Suporte ao serviço de agregação para Amazon Web Services (AWS) pela API Attribution Reporting e pela API Private Aggregate
Explicação |
Disponível |
| Suporte do serviço de agregação para o Google Cloud na API Attribution Reporting e na API Private Aggregation Explicação |
Disponível |
| Inscrição do site do serviço de agregação e agregação de várias origens. A inscrição de site inclui o mapeamento de um site para contas de nuvem (AWS ou GCP). Para agregar várias origens, elas precisam ser do mesmo site.
Perguntas frequentes no GitHub Documentação da API de agregação de sites |
Disponível |
| O valor de epsilon do serviço de agregação será mantido em um intervalo de até 64, para facilitar a experimentação e o feedback sobre diferentes parâmetros.
Enviar feedback épsilon da ARA. Enviar feedback épsilon do PAA. |
Disponível. Vamos avisar com antecedência ao ecossistema antes que os valores do intervalo de epsilon sejam atualizados. |
| Filtragem de contribuição mais flexível para consultas do serviço de agregação
Explicação |
Disponível |
| Processo de recuperação do orçamento após um desastre (erros, configurações incorretas etc.)
Explicação |
Mecanismo disponível para analisar a porcentagem de IDs compartilhados recuperados por uma adtech usando a recuperação de orçamento e suspender recuperações futuras para recuperações excessivas planejadas para o primeiro semestre de 2025 |
| A Accenture opera como um dos coordenadores na AWS
Blog para desenvolvedores |
Disponível |
| Parte independente que atua como um dos coordenadores no Google Cloud
Blog para desenvolvedores |
Disponível |
| Suporte ao serviço de agregação para gerar relatórios de depuração agregados na API Attribution Reporting
Explicação |
Disponível |
Principais termos e conceitos
Se você está pensando em usar o serviço de agregação no seu fluxo de adtech, os termos e conceitos a seguir vão dar mais informações sobre o que esse novo fluxo de agregação pode oferecer à sua equipe:
| Termo | Descrição |
|---|---|
| Serviço de agregação | Um serviço operado por adtech que processa relatórios agregáveis para criar um relatório de resumo. |
| Relatórios agregáveis |
Os relatórios agregáveis são relatórios criptografados enviados de dispositivos de usuários específicos. Esses relatórios contêm dados sobre o comportamento do usuário em vários sites e as conversões. As conversões (às vezes chamadas de eventos acionadores de atribuição) e as métricas associadas são definidas pelo anunciante ou pela adtech. Cada relatório é criptografado para evitar que várias partes acessem os dados. Saiba mais sobre relatórios agregáveis. |
| Contabilização de relatórios agregáveis | Um ledger distribuído localizado nos dois coordenadores que rastreia o orçamento de privacidade alocado e aplica a regra "Sem duplicações". Esse é o mecanismo de preservação de privacidade, localizado e executado nos coordenadores, que garante que nenhum relatório passe pelo serviço de agregação além do orçamento de privacidade alocado. Leia mais sobre as estratégias de lote e como elas se relacionam com os relatórios agregáveis. |
| Orçamento de contabilidade de relatórios agregáveis | Referências ao orçamento que garantem que os relatórios não sejam processados mais de uma vez. |
| Ambiente de execução confiável (TEE) |
Um ambiente de execução confiável é uma configuração especial de hardware e software de computador que permite as partes para verificar as versões exatas do software em execução no computador. TEEs permitem que partes externas verifiquem se o software faz exatamente o que fabricante do software afirma que sim, nada mais ou menos. Para saber mais sobre os TEEs usados para as propostas do Sandbox de privacidade, leia a explicação dos serviços da API Protected Audience e a explicação do serviço de agregação. |
| Coordenadores |
Um coordenador é uma entidade responsável pelo gerenciamento de chaves e pela contabilidade de relatórios agregáveis. O coordenador mantém uma lista de hashes de configurações aprovadas do serviço de agregação e configura o acesso às chaves de descriptografia. |
| ID compartilhado |
Valor computado que consiste em: shared_info, reporting_origin, destination_site (disponível apenas para a API Attribution Reporting), source_registration-time (disponível apenas para a API Attribution Reporting), scheduled_report_time e version.
Isso significa que vários relatórios pertencem ao mesmo ID compartilhado se tiverem os mesmos atributos do campo shared_info. Isso desempenha um papel importante na contabilização de relatórios agregáveis.
Saiba mais sobre os servidores confiáveis.
|
| Relatório de resumo |
Um relatório de resumo é um tipo de relatório da API Attribution Reporting e da API Private Aggregation. Um resumo inclui dados agregados do usuário e pode conter dados de conversão detalhados, com adição de ruído. Os relatórios de resumo são compostos por relatórios agregados. Os relatórios de resumo oferecem mais flexibilidade e um modelo de dados mais rico do que os relatórios de evento, principalmente para alguns casos de uso, como valores de conversão. |
| Origem do relatório |
A origem do relatório é a entidade que recebe relatórios agregáveis, ou seja, a adtech que chamou a API Attribution Reporting. Os relatórios agregáveis são enviados de dispositivos dos usuários para um URL conhecido associado ao relatório origem. Essa origem de relatórios precisa ser designada durante a inscrição. |
| Vinculação de contribuições | Os relatórios agregáveis podem conter um número arbitrário de incrementos de contador. Por exemplo, um relatório pode conter uma contagem de produtos que um usuário visualizou no site de um anunciante. A soma dos incrementos em todos os relatórios agregáveis relacionados a um único evento de origem não pode exceder um determinado limite, "L1=2^16". Saiba mais na explicação sobre os relatórios agregáveis. |
| Ruído e dimensionamento | Uma certa quantidade de ruído estatístico é adicionada aos relatórios de resumo como parte do processo de agregação, que também funciona para preservar a privacidade e garantir que os relatórios finais forneçam informações de medição anonimizadas. Leia mais sobre o mecanismo de ruído aditivo, que é extraído da distribuição de Laplace. |
| Declaração |
O atestado é um mecanismo para autenticar a identidade do software, geralmente com hashes criptográficos ou assinaturas. Para a proposta de serviço de agregação, o atestado corresponde o código em execução no serviço de agregação operado por tecnologias de publicidade com o código-fonte aberto. Saiba mais sobre atestados. |
Leia mais sobre o histórico do serviço de agregação em nosso texto explicativo e na lista completa de termos.
Casos de uso de agregação
Considere as seguintes jornadas de desenvolvedores para a medição de anúncios e as bibliotecas de cliente de medição correspondentes.
| Caso de uso | Ponto de entrada | Descrição |
|---|---|---|
| Otimização de lances | API Attribution Reporting (Chrome e Android) | Use relatórios agregados para processar indicadores de conversão para otimizar os lances. |
| Medição em várias plataformas | API Attribution Reporting (Chrome e Android) | Use os recursos de medição na Web e no app para ter visibilidade da performance no Chrome e no Android. |
| Relatórios de conversão | API Attribution Reporting (Chrome e Android) | Crie relatórios de conversão agregados adaptados às necessidades da campanha dos clientes (incluindo CTCs e VTCs). |
| Medição do alcance da campanha | API Shared Storage e API Private Aggregation (Chrome) | Use variáveis de visualização de anúncios entre sites para medir o alcance da campanha. |
| Relatórios demográficos | API Shared Storage e API Private Aggregation (Chrome) | Use a visualização de anúncios entre sites e as informações demográficas para medir o alcance por demografia. |
| Análise do caminho de conversão | API Shared Storage e API Private Aggregation (Chrome) | Armazene as variáveis de visualização de anúncios entre sites e de conversão para realizar a análise agregada do caminho de conversão. |
| Brand Lift e Conversion Lift | API Shared Storage e API Private Aggregation (Chrome) | Relatórios sobre grupos de teste/controle e informações de pesquisa para medir o aumento da marca e a incrementabilidade. |
| Depuração de leilões | API Protected Audience e API Private Aggregation (Chrome) | Use relatórios agregados para depuração. |
| Distribuição de lances | API Protected Audience e API Private Aggregation (Chrome) | Use relatórios agregados para capturar a distribuição dos valores de lances para leilões. |
Fluxo completo
O diagrama a seguir mostra o serviço de agregação em ação. Vamos nos concentrar no fluxo completo, desde o recebimento dos relatórios da Web e de dispositivos móveis até a criação dos relatórios de resumo no serviço de agregação.
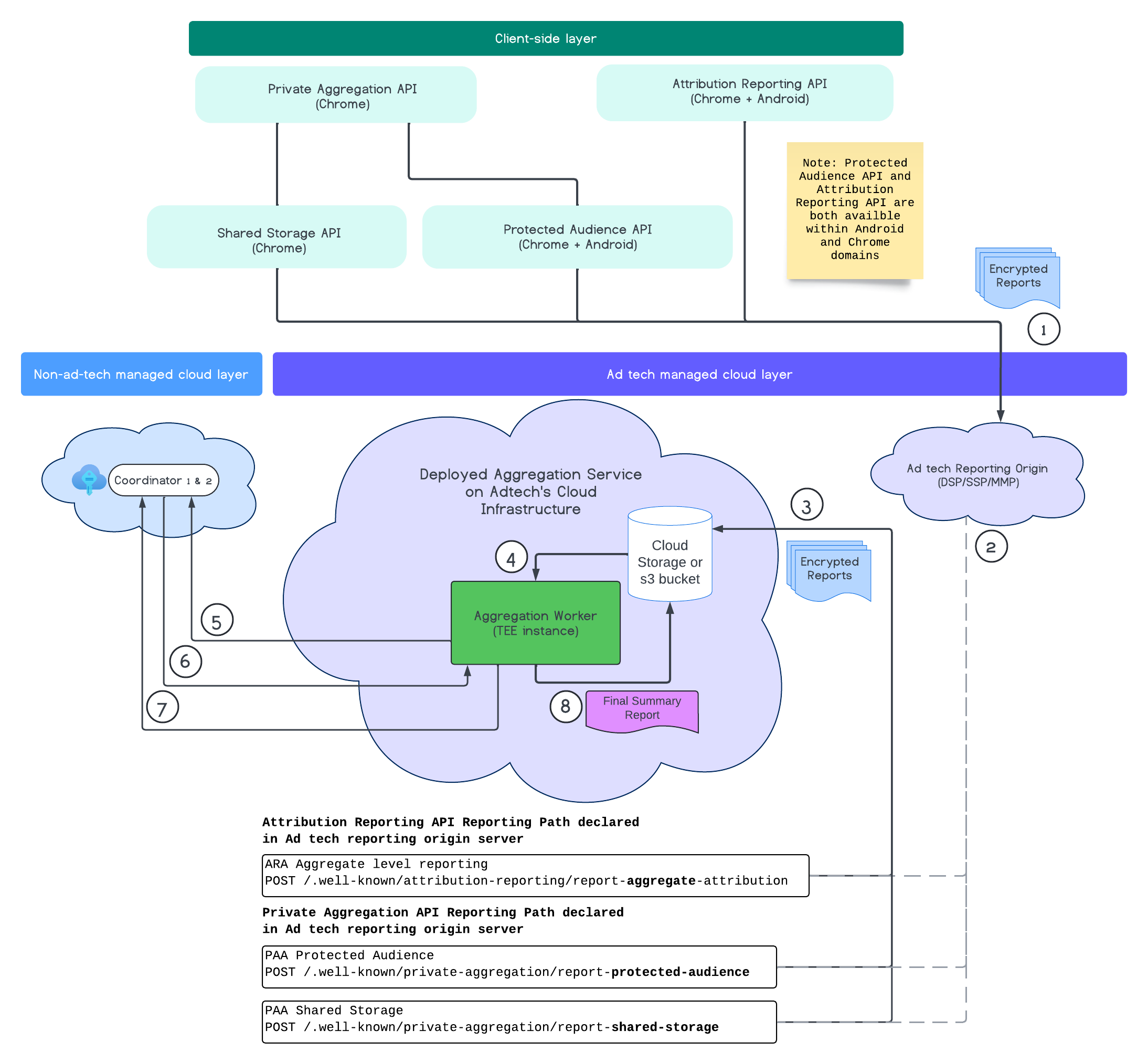
- Buscar a chave pública para gerar relatórios criptografados.
- Relatórios criptografados e agregáveis enviados aos servidores de adtechs para coleta, transformação e agrupamento.
- O servidor de adtech agrupa relatórios (formato avro) e os envia para o serviço de agregação implantado. Precisa ser preenchido pela adtech.
- Extrair relatórios agregados para descriptografar.
- Recuperar chaves de descriptografia dos coordenadores.
- O serviço de agregação descriptografa relatórios para agregação e geração de ruído.
- O serviço de contabilização de relatórios agregáveis verifica se há algum orçamento de privacidade restante para gerar um relatório de resumo dos relatórios agregáveis.
- Envie o relatório resumido final.
No diagrama, é possível ver a relação geral que o serviço de agregação tem com as principais APIs de medição de clientes API Attribution Reporting, API Private Aggregation e os coordenadores.
O fluxo começa com diferentes APIs Measurement, como a API Attribution Reporting ou a API Private Aggregation, que geram relatórios de várias instâncias do navegador. O Chrome usa a chave pública do serviço de hospedagem de chaves no coordenador para criptografar os relatórios antes de enviá-los à origem de relatórios da adtech. As chaves públicas são alternadas a cada sete dias.
Depois que a origem de relatórios da adtech receber esses relatórios, ela precisa ser configurada para coletar e converter esses relatórios para o formato avro e enviá-los à instância do serviço de agregação implantada. Confira as estratégias de lote.
Quando a adtech estiver pronta para gerar lotes, ela vai criar uma solicitação em lote para o serviço de agregação, em que os relatórios são descriptografados com a recuperação das chaves de descriptografia do serviço de hospedagem de chaves, agregados e ruídos para criar um relatório de resumo. Isso depende se há orçamento de privacidade suficiente para gerar os relatórios de resumo finais.
O endpoint de origem de relatórios da adtech, onde os relatórios são coletados, é hospedado pela adtech, e o serviço de agregação é implantado na nuvem da adtech.
Relatórios agregáveis em lote
O fluxo de relatórios não seria completo sem a ajuda do servidor de origem de relatórios designado. Essa é a origem que uma adtech teria enviado no processo de registro. As principais ações que a origem de relatórios é responsável por realizar são coletar, transformar e agrupar os relatórios agregáveis recebidos e prepará-los para serem enviados ao serviço de agregação implantado da adtech no Google Cloud ou nos Amazon Web Services. Saiba como preparar seus relatórios agregáveis.
Agora que você já tem o conceito geral, confira os componentes que serão implantados no serviço de agregação.
Componentes do Cloud
O serviço de agregação consiste em vários componentes de serviço de nuvem. Os scripts do Terraform fornecidos provisionam e configuram todos os componentes necessários do serviço de nuvem.
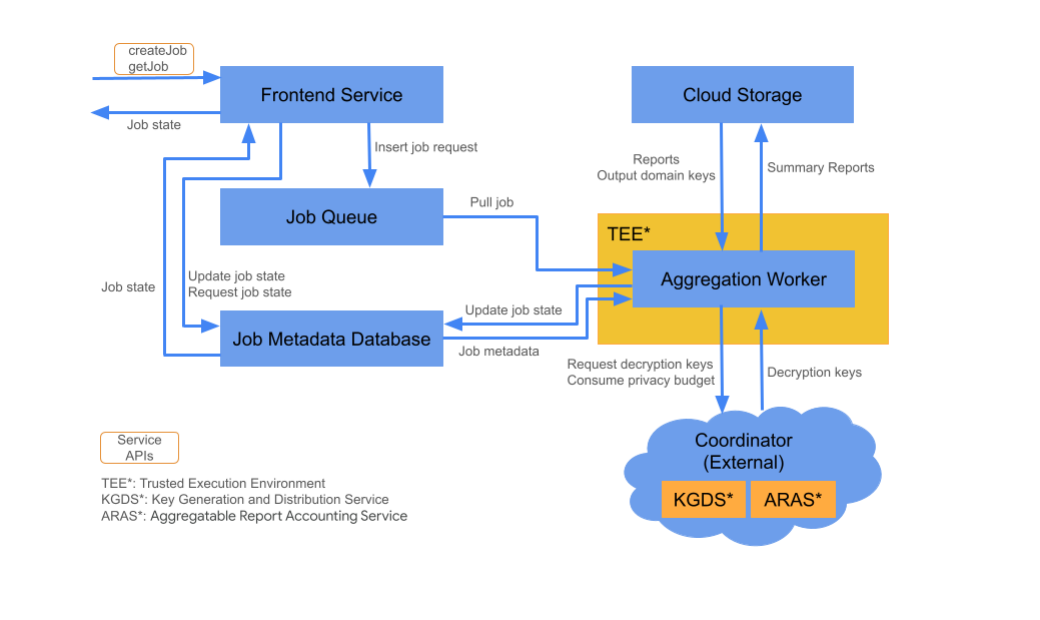
Serviço de front-end
Serviço gerenciado do Cloud:Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
O serviço de front-end é um gateway sem servidor que serve como ponto de entrada para chamadas da API Aggregation para criação e recuperação do estado de jobs. Ele é responsável por receber solicitações dos usuários do serviço de agregação, validar parâmetros de entrada e iniciar o processo de programação de jobs de agregação.
Duas APIs estão disponíveis no serviço de front-end:
| Endpoint | Descrição |
|---|---|
createJob |
Essa API aciona um job do serviço de agregação. Ele exige informações para acionar um job, como ID do job, detalhes de armazenamento de entrada, detalhes de armazenamento de saída, origem do relatório e muito mais. |
getJob |
Essa API retorna o status de um job para um ID de job especificado. Ele fornece informações sobre o estado do job, como "Recebido", "Em andamento" ou "Concluído". Além disso, se o job for concluído, ele vai mostrar o resultado, incluindo as mensagens de erro encontradas durante a execução. |
Confira a documentação da API Aggregation Service.
Fila de jobs
Serviço de nuvem gerenciado:Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
A fila de jobs é uma fila de mensagens que armazena solicitações de jobs para o serviço de agregação. O serviço de front-end insere mensagens de solicitação de job na fila, que são consumidas pelo Aggregation Worker para processar a solicitação de job.
Cloud Storage
Serviço de nuvem gerenciado:Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services). O armazenamento em nuvem é usado para armazenar arquivos de entrada e saída usados pelo serviço de agregação (exemplos: arquivos de relatório criptografados, relatórios de resumo de saída etc.).
Banco de dados de metadados do job
Serviço de nuvem gerenciado:Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
O Job Metadata Database armazena e rastreia o status dos jobs de agregação. O banco de dados registra metadados, como hora de criação, hora solicitada, hora de atualização e estado (exemplos: recebido, em andamento, concluído etc.). O Aggregation Worker atualiza o banco de dados de metadados do job conforme o job avança.
Worker de agregação
Serviço de nuvem gerenciado:Compute Engine com espaço confidencial (Google Cloud) / Amazon Web Services EC2 com Nitro Enclave (Amazon Web Services).
O worker de agregação processa solicitações de jobs iniciadas por uma solicitação de job na fila de jobs, descriptografando as entradas criptografadas usando chaves extraídas do serviço de geração e distribuição de chaves (KGDS, na sigla em inglês) nos coordenadores. Para minimizar a latência de processamento de jobs, as chaves de descriptografia são armazenadas em cache no worker de agregação por um período de 8 horas e podem ser usadas em jobs processados por essa instância de worker.
O worker opera em uma instância do ambiente de execução confiável (TEE). Cada worker processa apenas um job por vez. A adtech pode configurar vários workers para processar jobs em paralelo definindo a configuração de escalonamento automático. Com o escalonamento automático, o número de workers é ajustado dinamicamente pelo número de mensagens restantes na fila de jobs. O número mínimo e máximo de workers para o escalonamento automático pode ser configurado no arquivo de ambiente do Terraform. Confira mais informações sobre o escalonamento automático nos scripts do Terraform a seguir. [Amazon Web Services / Google Cloud]
O worker de agregação chama o serviço de contabilização de relatórios agregáveis para a contabilização de relatórios agregáveis. O serviço de contabilidade de relatórios agregáveis garante que os jobs só sejam executados se não tiverem excedido o limite de orçamento de privacidade. Consulte a regra"Sem duplicações". Se o orçamento estiver disponível, um relatório resumido será gerado usando os agregados com ruído. Leia mais detalhes sobre a contabilização de relatórios agregáveis.
O worker de agregação atualiza os metadados do job no banco de dados de metadados do job, incluindo os códigos de retorno adequados e contadores de erros de relatório em caso de falhas parciais. Os usuários podem buscar o estado usando a API de recuperação do estado do job (getJob).
Para uma descrição mais detalhada do serviço de agregação, consulte nosso texto explicativo.
Próximas etapas
Agora que você já conhece os destaques do serviço de agregação, é hora de implantar sua própria instância dele pelo Google Cloud ou Amazon Web Services. Confira a seção de início. Se precisar de mais informações sobre como operar um serviço de agregação implantado, clique neste link para saber mais sobre como operar o serviço de agregação.
Solução de problemas
Consulte nosso documento Códigos de erro e mitigações comuns para ver descrições mais detalhadas das mensagens de erro, o que pode ter causado o erro que você está enfrentando e as próximas etapas para mitigação.
Receber suporte e enviar feedback
- Para perguntas sobre o produto, feedback e solicitações de recursos, crie um problema no nosso repositório do GitHub.
- Se você estiver com um erro ao implantar, manter ou executar trabalhos com o serviço de agregação, use este formulário de suporte técnico para solicitar suporte técnico.
- Verifique se há problemas conhecidos no Painel de status público.