Esegui il deployment e gestisci questo servizio per produrre report di riepilogo per l'API Attribution Reporting o l'API Private Aggregation.
Esegui il deployment e gestisci un servizio di aggregazione per elaborare i report aggregabili dall'API Attribution Reporting o dall'API Private Aggregation per creare un report di riepilogo.
Stato implementazione
- Aggregation Service è orato in disponibilità generale.
- Aggregation Service può essere testato con l'API Attribution Reporting e l'API Private Aggegration per l'API Protected Audience e l'archiviazione condivisa.
Il testo esplicativo illustra i termini chiave, utili per comprendere il servizio di aggregazione.
Disponibilità
| Proposta | Stato |
|---|---|
| Supporto di Aggregation Service per Amazon Web Services (AWS) tramite API Attribution Reporting e API Private Aggregation
Explainer |
Disponibile |
| Supporto di Aggregation Service per Google Cloud tra API Attribution Reporting e API Private Aggregation Explainer |
Disponibile in versione beta |
| Registrazione e mappatura dei siti di Aggregation Service ad account cloud (AWS o GCP) Domande frequenti su GitHub |
Disponibile |
| Il valore epsilon di Aggregation Service verrà mantenuto in un intervallo fino a 64, per facilitare la sperimentazione e il feedback sui diversi parametri.
Invia un feedback ARA epsilon. Invia un feedback di PAA epsilon. |
Disponibile Prima dell'aggiornamento dei valori degli intervalli epsilon, daremo un preavviso all'ecosistema. |
| Filtri dei contributi più flessibili per le query di Aggregation Service
Spiegazione |
Previsto per il secondo trimestre del 2024 |
| Processo per il recupero del budget dopo le emergenze (errori, configurazioni errate e così via)
Problema di GitHub |
Previsto per il secondo trimestre del 2024 |
| Accenture opera come uno dei Coordinators su AWS
Blog per sviluppatori |
Disponibile |
| Parte indipendente che opera come uno dei coordinatori su Google Cloud
Blog per sviluppatori |
Previsto nel terzo trimestre del 2024 |
Trattamento dati sicuro
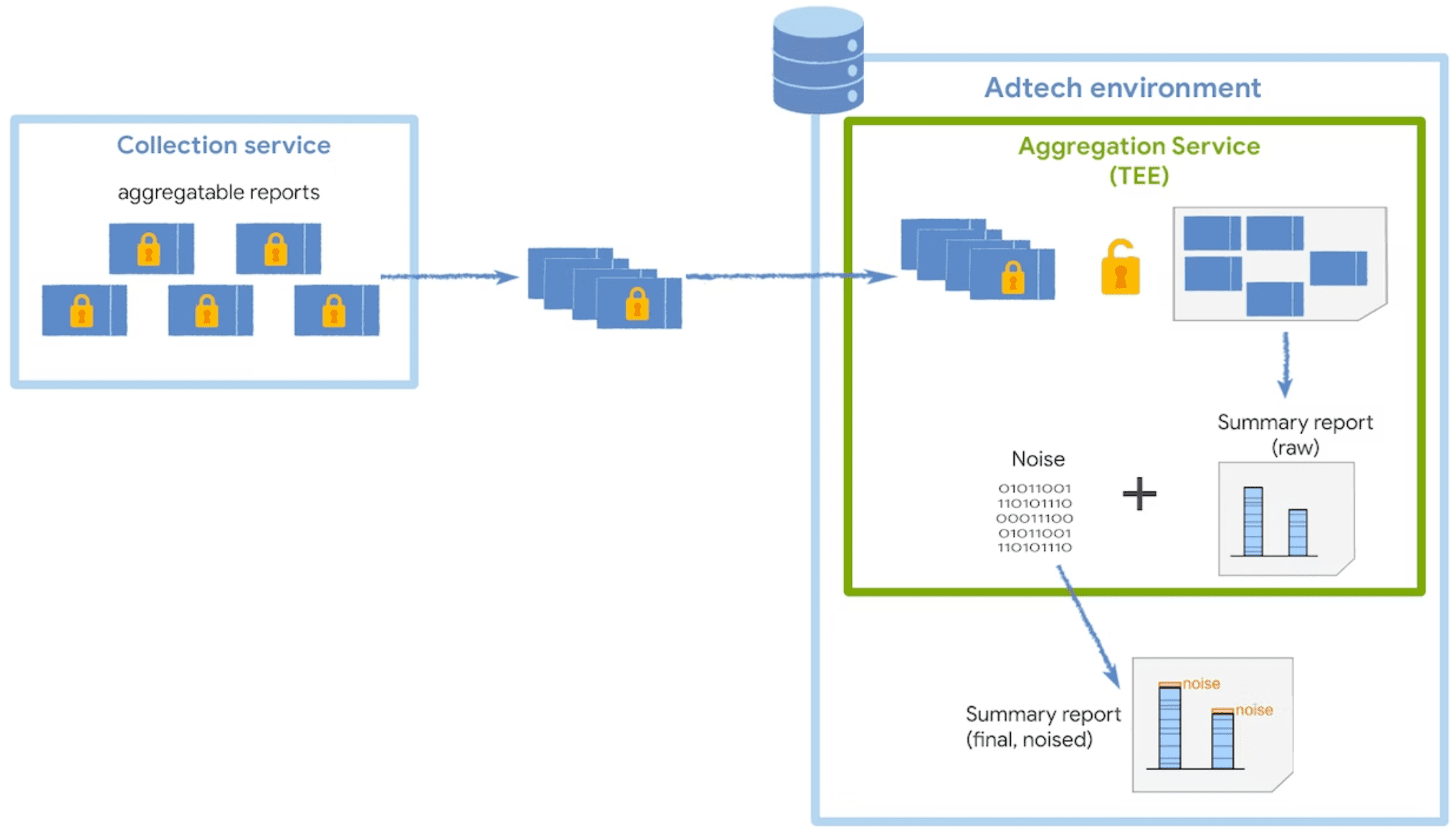
Il servizio di aggregazione decripta e combina i dati raccolti dai report aggregabili, aggiunge rumore e restituisce il report di riepilogo finale. Questo servizio viene eseguito in un ambiente di esecuzione affidabile (Trusted Execution Environment, TEE), di cui è stato eseguito il deployment su un servizio cloud che supporta le misure di sicurezza necessarie per la protezione di questi dati.
Il codice del TEE è l'unico posto nel servizio di aggregazione che ha accesso a report non elaborati e questo codice potrà essere controllato dai ricercatori della sicurezza, dai sostenitori della privacy e dai tecnici pubblicitari. Per confermare che il TEE esegua l'esatto software approvato e che i dati rimangano protetti, un coordinatore esegue l'attestazione.
Attestazione del TEE da parte del coordinatore
Il coordinatore è un'entità responsabile della gestione delle chiavi e della contabilità dei report aggregabili.
Un coordinatore ha diverse responsabilità:
- Mantieni un elenco di immagini binarie autorizzate. Queste immagini sono hash crittografici delle build del software di Aggregation Service, che Google rilascerà periodicamente. Sarà riproducibile in modo che chiunque possa verificare che le immagini siano identiche alle build di Aggregation Service.
- Utilizzare un sistema di gestione delle chiavi. Per crittografare i report aggregabili sono necessarie chiavi di crittografia per Chrome sul dispositivo di un utente. Le chiavi di decrittografia sono necessarie per dimostrare che il codice del servizio di aggregazione corrisponde alle immagini binarie.
- Monitorare i report aggregabili per evitare il riutilizzo in aggregazione per i report di riepilogo, in quanto il riutilizzo potrebbe rivelare informazioni che consentono l'identificazione personale (PII).
Regola "Nessun duplicato"
Per acquisire informazioni sui contenuti di un report aggregabile specifico, un utente malintenzionato potrebbe fare più copie del report e includerle in uno o più batch. Per questo motivo, il servizio di aggregazione applica una regola "no duplicati":
- In batch: il report aggregabile può essere visualizzato solo una volta all'interno di un batch.
- In più batch: i report aggregati non possono essere visualizzati in più gruppi né contribuire a più di un report di riepilogo.
A questo scopo, il browser assegna a ogni report aggregabile un ID condiviso.
Il browser genera l'ID condiviso da diversi punti dati, tra cui: versione API, origine report, sito di destinazione, ora registrazione origine e ora report pianificato. Questi dati provengono dal campo shared_info del report.
Aggregation Service conferma che i report tutti aggregabili con lo stesso ID condiviso siano nello stesso batch e segnala al coordinatore che l'ID condiviso è stato elaborato. Se vengono creati più batch con lo stesso ID, è possibile accettare un solo batch per l'aggregazione, mentre gli altri vengono rifiutati.
Quando esegui un'esecuzione di debug, la regola "Nessun duplicato" non viene applicata nei batch. In altre parole, i report dei batch precedenti potrebbero essere visualizzati in un'esecuzione di debug. Tuttavia, la regola viene comunque applicata all'interno di un batch. Ciò consente di sperimentare con il servizio e con varie strategie di batch, senza limitare le elaborazioni future in un ambiente di produzione.
Rumore e scalabilità
Per proteggere la privacy degli utenti, il servizio di aggregazione applica un meccanismo di rumore aggiuntivo ai dati non elaborati aggregabili ai report. Ciò significa che viene aggiunta una determinata quantità di rumore statistico a ogni valore aggregato prima della relativa release in un report di riepilogo.
Anche se non hai il controllo diretto delle modalità di aggiunta del rumore, puoi influenzare l'impatto del rumore sui suoi dati di misurazione.

Il valore del rumore viene estratto in modo casuale da una distribuzione di probabilità di Laplace e la distribuzione è la stessa indipendentemente dalla quantità di dati raccolti nei report aggregati. Maggiore è la quantità di dati raccolti, minore sarà l'impatto del rumore sui risultati del report di riepilogo. Puoi moltiplicare i dati dei report aggregabili per un fattore di scalabilità al fine di ridurre l'impatto del rumore.
Per capire in che modo viene aggiunto il rumore, i controlli e l'impatto sui report, consulta le sezioni Budget per il contributo e Ampliare il budget per i contributi in Utilizzare il rumore.
Genera report di riepilogo
La generazione del report di riepilogo dipende dall'utilizzo dell'API. Scopri di più sulla generazione di report di riepilogo per l'API Private Aggregation e l'API Attribution Reporting.
Testa il servizio di aggregazione
Ti consigliamo di leggere la guida corrispondente a ciascuna API che stai testando:
Per testare Aggregation Service su AWS, consulta queste istruzioni.
È disponibile anche uno strumento di test locale per elaborare i report aggregabili per Attribution Reporting e l'API Private Aggregation.
Il framework per i test di carico del servizio di aggregazione fornisce un framework di test suggerito.
Interagisci e condividi feedback
Aggregation Service è un elemento chiave delle API di misurazione di Privacy Sandbox. Come altre API Privacy Sandbox, questo è documentato e discusso pubblicamente su GitHub.
- GitHub: leggi il spiegatore, poni domande e partecipa alla discussione. Dai anche un'occhiata all'implementazione di Aggregation Service e fornisci feedback sull'implementazione.
- Assistenza per gli sviluppatori: poni domande e partecipa alle discussioni sul repository dell'assistenza per gli sviluppatori di Privacy Sandbox.