집계 서비스는 집계 가능한 원시 보고서에서 상세한 전환 데이터 및 도달범위 측정의 요약 보고서를 생성합니다. 광고 기술에는 클라이언트 측에 Attribution Reporting API 또는 Private Aggregation API를 통해 보고서를 집계 서비스로 전달하는 두 가지 주요 집계 진입점이 있습니다.
구현 상태
- 집계 서비스가 정식 버전으로 전환되었습니다.
- Aggregation Service는 Protected Audience API 및 Shared Storage API의 Attribution Reporting API 및 Private Aggregation API와 함께 사용할 수 있습니다.
가용성
| 提案 | 状态 |
|---|---|
| 针对 Attribution Reporting API、Private Aggregation API 中的 Amazon Web Services (AWS) 提供汇总服务支持
说明 |
可用 |
| 跨 Attribution Reporting API、Private Aggregation API 为 Google Cloud 提供汇总服务支持 说明文档 |
可用 |
| 汇总服务网站注册和多源汇总。网站注册包括将网站映射到云账号(AWS 或 GCP)。若要汇总多个源站,这些源站必须属于同一个网站。
GitHub 上的常见问题解答 网站汇总 API 文档 |
可用 |
| 汇总服务的 epsilon 值将保持一个不超过 64 的范围,以方便对不同参数的实验和反馈。
提交 ARA 小数值反馈。 提交 PAA 小数值反馈。 |
可用。在更新 epsilon 范围值之前,我们会提前通知整个生态系统。 |
| 为汇总服务查询提供更灵活的贡献过滤功能
解说 |
可用 |
| 灾难后(错误、配置错误等)的预算恢复流程
解说 |
提供 机制,用于审核广告技术平台使用预算挽回功能找回的共享 ID 所占百分比,以及针对 2025 年上半年计划恢复的过多账号恢复请求暂停未来恢复机制 |
| Accenture 是 AWS 协调者之一
开发者博客 |
可用 |
| 担任 Google Cloud 协调员之一的独立方
开发者博客 |
可用 |
| 汇总服务对 Attribution Reporting API 上的汇总调试报告的支持
说明 |
可用 |
주요 용어 및 개념
광고 기술 워크플로에서 집계 서비스를 사용하려는 경우 다음 용어와 개념을 통해 이 새로운 집계 흐름이 팀에 어떤 이점을 제공할 수 있는지 자세히 알아보세요.
| 术语 | 说明 |
|---|---|
| 汇总服务 | 由广告技术平台运营的服务,用于处理可汇总报告以创建摘要报告。 |
| 可汇总的报告 |
可汇总报告是从各个用户设备发送的加密报告。这些报告包含有关跨网站用户行为和转化的数据。转化(有时称为归因触发器事件)和关联的指标由广告主或广告技术平台定义。每个报告都会加密,以防止多方访问基础数据。 详细了解可汇总的报告。 |
| 可汇总报告的会计核算 | 位于两个协调器中的分布式账本,用于跟踪分配的隐私预算并强制执行“无重复”规则。这是一种隐私保护机制,位于协调者中并在其中运行,可确保通过汇总服务传递的报告不会超出分配的隐私预算。 详细了解批处理策略与可汇总报告的关系。 |
| 可汇总报告的会计核算预算 | 对预算的引用,用于确保报告不会被处理多次。 |
| 可信执行环境 (TEE) |
可信执行环境是计算机硬件和软件的一种特殊配置, 验证计算机上运行的软件的确切版本。TEEs 允许外部各方验证软件是否完全按照 软件制造商声称可以,不多或少。 如需详细了解用于 Privacy Sandbox 提案的 TEE,请参阅 Protected Audience API 服务说明文档 以及汇总服务说明。 |
| 协调员 |
协调者是负责密钥管理和可汇总报告的会计核算的实体。协调者维护已获批准的汇总服务配置的哈希列表,并配置对解密密钥的访问权限。 |
| 共享 ID |
计算值,由以下各项组成:shared_info、reporting_origin、destination_site(仅适用于 Attribution Reporting API)、source_registration-time(仅适用于 Attribution Reporting API)、scheduled_report_time、version。
这意味着,如果多个报告具有相同的 shared_info 字段属性,则它们属于同一共享 ID。这在可汇总报告会计中起着重要作用。
详细了解可信服务器。
|
| 汇总报告 |
요약 보고서는 Attribution Reporting API 및 Private Aggregation API 보고서 유형입니다. 요약 보고서에는 집계된 사용자 데이터가 포함되며 노이즈가 추가된 세부적인 전환 데이터가 포함될 수 있습니다. 요약 보고서는 집계 보고서로 구성됩니다. 요약 보고서를 사용하면 특히 전환 가치와 같은 일부 사용 사례에서 이벤트 수준 보고보다 더 유연하고 풍부한 데이터 모델을 사용할 수 있습니다. |
| 举报来源 |
报告来源是接收可汇总报告的实体,也就是调用 Attribution Reporting API 的广告技术平台。可汇总报告的来源 将用户设备转到与报告关联的已知网址 来源。此报告来源应在注册期间指定。 |
| 贡献债券 | 可汇总的报告可以包含任意数量的计数器增量。例如,报告中可能包含用户在广告客户网站上查看过的商品数量。与单个来源事件相关的所有可汇总报告中的增量之和不得超过给定限制“L1=2^16”。 如需了解详情,请参阅可汇总报告说明。 |
| 噪声和缩放 | 在汇总过程中,系统会向摘要报告添加一定量的统计噪声,这也有助于保护隐私并确保最终报告提供匿名化效果衡量信息。详细了解加法噪声机制,该机制是从拉普拉斯分布中提取的。 |
| 证明 |
认证是一种用于对软件身份进行身份验证的机制,通常使用加密哈希或签名。对于汇总服务方案,证明会将广告技术平台运营的汇总服务中运行的代码与开放源代码进行匹配。 详细了解证明。 |
설명 및 용어집에서 집계 서비스의 배경에 대해 자세히 알아보세요.
집계 사용 사례
광고 측정 및 해당 측정 클라이언트 라이브러리의 다음 개발자 여정을 고려해 보세요.
| 사용 사례 | 진입점 | 설명 |
|---|---|---|
| 입찰 최적화 | Attribution Reporting API (Chrome 및 Android) | 집계된 보고서를 사용하여 입찰가 최적화를 위해 전환 신호를 처리합니다. |
| 교차 플랫폼 측정 | Attribution Reporting API (Chrome 및 Android) | 교차 웹 및 앱 측정 기능을 사용하여 Chrome과 Android 전반의 실적을 파악하세요. |
| 전환 보고 | Attribution Reporting API (Chrome 및 Android) | 고객의 캠페인 요구사항에 맞게 집계된 전환 보고를 만듭니다 (CTC 및 VTC 포함). |
| 캠페인 도달범위 측정 | Shared Storage API 및 Private Aggregation API (Chrome) | 교차 사이트 광고 조회 변수를 사용하여 캠페인 도달범위를 측정합니다. |
| 인구통계 보고 | Shared Storage API 및 Private Aggregation API (Chrome) | 교차 사이트 광고 조회수 및 인구통계 정보를 사용하여 인구통계별 도달범위를 측정합니다. |
| 전환 경로 분석 | Shared Storage API 및 Private Aggregation API (Chrome) | 집계된 전환 경로 분석을 실행하기 위해 교차 사이트 광고 조회 및 전환 변수를 저장합니다. |
| 브랜드 및 전환 상승도 | Shared Storage API 및 Private Aggregation API (Chrome) | 브랜드 효과 및 증분을 측정하기 위한 테스트/대조군 및 폴링 정보에 관한 보고 |
| 입찰 디버깅 | Protected Audience API 및 Private Aggregation API (Chrome) | 집계된 보고서를 디버깅에 사용합니다. |
| 입찰가 분포 | Protected Audience API 및 Private Aggregation API (Chrome) | 집계된 보고서를 사용하여 입찰의 입찰가 값 분포를 파악합니다. |
엔드 투 엔드 흐름
다음 다이어그램은 집계 서비스가 작동하는 모습을 보여줍니다. 웹 및 모바일에서 보고서를 수신하여 집계 서비스에서 요약 보고서를 만드는 엔드 투 엔드 흐름에 중점을 둡니다.
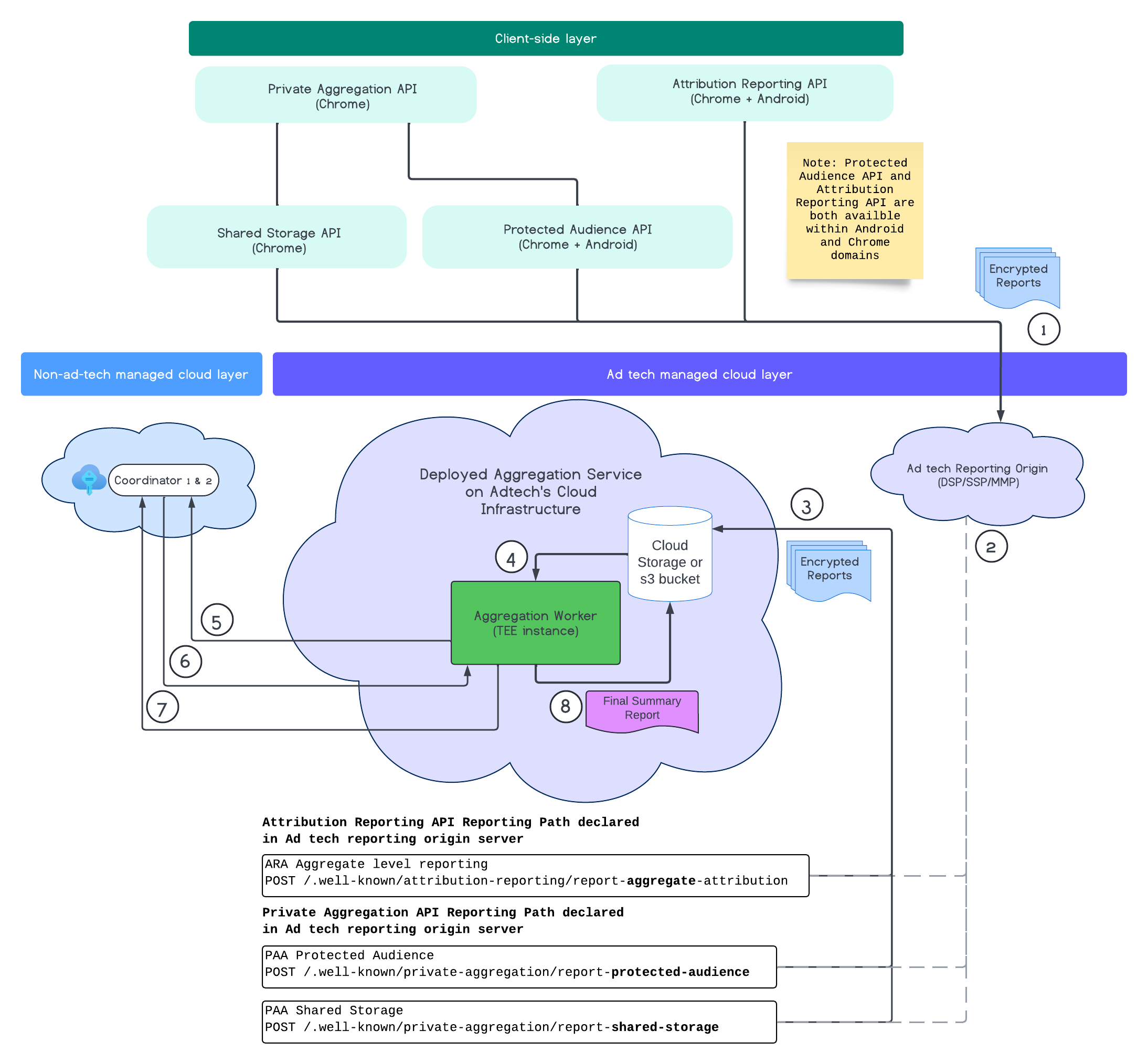
- 공개 키를 가져와 암호화된 보고서를 생성합니다.
- 수집, 변환, 일괄 처리를 위해 광고 기술 서버로 전송되는 암호화된 집계 가능 보고서입니다.
- 광고 기술 서버는 보고서 (avro 형식)를 일괄 처리하여 배포된 집계 서비스로 전송합니다. (광고 기술에서 완료해야 함)
- 집계된 보고서를 검색하여 복호화합니다.
- 조정자로부터 복호화 키를 가져옵니다.
- 집계 서비스는 집계 및 노이즈 제거를 위해 보고서를 복호화합니다.
- 집계 가능한 보고서 회계 서비스는 지정된 집계 가능한 보고서의 요약 보고서를 생성하기 위해 남은 개인 정보 보호 예산이 있는지 확인합니다.
- 최종 요약 보고서를 제출합니다.
다이어그램에서 집계 서비스와 기본 클라이언트 측정 API인 Attribution Reporting API, Private Aggregation API, 조정자와의 전반적인 관계를 확인할 수 있습니다.
흐름은 Attribution Reporting API 또는 Private Aggregation API와 같은 다양한 측정 API로 시작하여 여러 브라우저 인스턴스에서 보고서를 생성합니다. Chrome은 보고서가 광고 기술의 보고 출처로 전송되기 전에 보고서를 암호화하기 위해 코디네이터의 키 호스팅 서비스에서 공개 키를 가져옵니다. 공개 키는 7일마다 순환됩니다.
광고 기술의 보고 출처가 이러한 보고서를 수신하면 보고 출처는 이러한 보고서를 수집하여 avro 형식으로 변환하고 배포된 집계 서비스 인스턴스로 전송하도록 구성해야 합니다. 일괄 처리 전략을 확인하세요.
광고 기술이 일괄 처리할 준비가 되면 광고 기술은 집계 서비스에 대한 일괄 요청을 생성합니다. 여기서 키 호스팅 서비스에서 복호화 키를 검색하여 보고서를 복호화하고 집계 및 노이즈 처리하여 요약 보고서를 만듭니다. 이는 최종 요약 보고서를 생성하기에 충분한 개인 정보 보호 예산이 있는지에 따라 달라집니다.
보고서가 수집되는 광고 기술 보고 출처 엔드포인트는 광고 기술에서 호스팅되며 집계 서비스는 광고 기술의 클라우드에 배포됩니다.
집계 가능한 보고서 일괄 처리
지정된 보고 출처 서버의 도움이 없다면 보고 흐름이 완료되지 않습니다. 광고 기술이 등록 프로세스에서 제출한 출처입니다. 보고 출처에서 담당하는 주요 작업은 수신된 집계 가능한 보고서를 수집, 변환, 일괄 처리하고 Google Cloud 또는 Amazon Web Services에 있는 광고 기술의 배포된 집계 서비스로 전송할 준비를 하는 것입니다. 집계 가능한 보고서를 준비하는 방법을 자세히 알아보세요.
이제 일반적인 개념을 알았으므로 집계 서비스에 배포될 구성요소를 자세히 살펴보겠습니다.
Cloud 구성요소
집계 서비스는 다양한 클라우드 서비스 구성요소로 구성됩니다. 제공된 Terraform 스크립트는 필요한 모든 클라우드 서비스 구성요소를 프로비저닝하고 구성합니다.
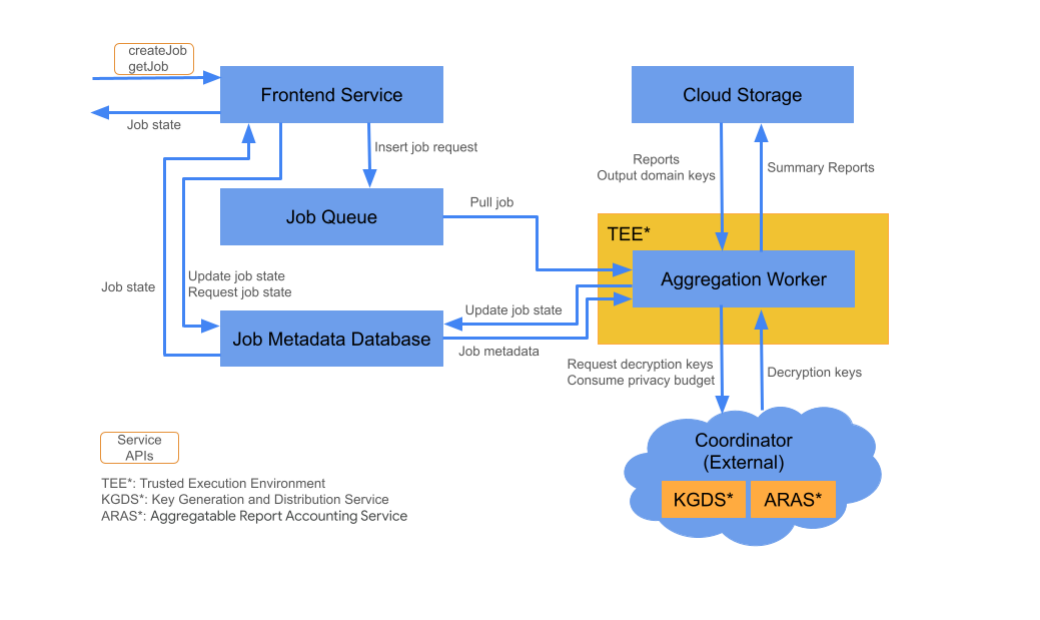
프런트엔드 서비스
관리형 Cloud 서비스: Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
프런트엔드 서비스는 작업 생성 및 작업 상태 검색을 위한 집계 API 호출의 진입점 역할을 하는 서버리스 게이트웨이입니다. 집계 서비스 사용자의 요청을 수신하고, 입력 매개변수를 검증하고, 집계 작업 예약 프로세스를 시작합니다.
프런트엔드 서비스에서 사용할 수 있는 API는 두 가지입니다.
| 엔드포인트 | 설명 |
|---|---|
createJob |
이 API는 집계 서비스 작업을 트리거합니다. 작업 ID, 입력 저장소 세부정보, 출력 저장소 세부정보, 보고 출처와 같은 작업을 트리거하는 데 필요한 정보가 필요합니다. |
getJob |
이 API는 지정된 작업 ID의 작업 상태를 반환합니다. '수신됨', '진행 중', '완료됨'과 같은 작업 상태에 관한 정보를 제공합니다. 또한 작업이 완료되면 작업 실행 중에 발생한 오류 메시지를 포함하여 작업 결과가 표시됩니다. |
Aggregation Service API 문서를 확인하세요.
작업 대기열
관리형 클라우드 서비스: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
작업 큐는 집계 서비스의 작업 요청을 저장하는 메시지 큐입니다. 프런트엔드 서비스는 작업 요청 메시지를 대기열에 삽입하고 집계 작업자가 이를 사용하여 작업 요청을 처리합니다.
클라우드 스토리지
관리형 클라우드 서비스: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services) 클라우드 스토리지는 집계 서비스에서 사용하는 입력 및 출력 파일 (예: 암호화된 보고서 파일, 출력 요약 보고서 등)을 저장하는 데 사용됩니다.
작업 메타데이터 데이터베이스
관리형 클라우드 서비스: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
작업 메타데이터 데이터베이스는 집계 작업의 상태를 저장하고 추적합니다. 데이터베이스는 생성 시간, 요청 시간, 업데이트 시간, 상태 (예: 수신됨, 진행 중, 완료됨 등)와 같은 메타데이터를 기록합니다. 집계 작업자는 작업이 진행됨에 따라 작업 메타데이터 데이터베이스를 업데이트합니다.
집계 작업자
관리형 클라우드 서비스: 기밀 공간이 있는 Compute Engine (Google Cloud) / Nitro Enclave가 있는 Amazon Web Services EC2 (Amazon Web Services)
집계 작업자는 작업 큐의 작업 요청으로 시작된 작업 요청을 처리하여 코디네이터의 키 생성 및 배포 서비스 (KGDS)에서 가져온 키를 사용하여 암호화된 입력을 복호화합니다. 작업 처리 지연 시간을 최소화하기 위해 복호화 키는 8시간 동안 집계 작업자에 캐시되며, 이 작업자 인스턴스에서 처리하는 작업 전반에서 사용할 수 있습니다.
작업자는 신뢰할 수 있는 실행 환경 (TEE) 인스턴스 내에서 작동합니다. 각 작업자는 한 번에 하나의 작업만 처리합니다. 광고 기술은 자동 확장 구성을 설정하여 여러 작업자가 작업을 동시에 처리하도록 구성할 수 있습니다. 자동 확장을 통해 작업 큐에 남아 있는 메시지 수를 기준으로 작업자 수가 동적으로 조정됩니다. 자동 확장의 최소 및 최대 작업자 수는 Terraform 환경 파일을 통해 구성할 수 있습니다. 자동 확장에 관한 자세한 내용은 다음 Terraform 스크립트를 참고하세요. [Amazon Web Services / Google Cloud]
집계 작업자는 집계 가능한 보고서 회계를 위해 집계 가능한 보고서 회계 서비스를 호출합니다. 집계 가능한 보고서 회계 서비스는 아직 개인 정보 보호 예산 한도를 초과하지 않는 한 작업이 실행되도록 합니다. ('중복 없음' 규칙 참고) 예산을 사용할 수 있으면 노이즈가 있는 집계를 사용하여 요약 보고서가 생성됩니다. 집계 가능한 보고서 회계에 관한 추가 세부정보를 확인하세요.
집계 작업자는 적절한 작업 반환 코드와 부분 보고 실패의 경우 오류 카운터를 포함하여 작업 메타데이터 데이터베이스의 작업 메타데이터를 업데이트합니다. 사용자는 작업 상태 검색 API (getJob)를 사용하여 상태를 가져올 수 있습니다.
집계 서비스에 대한 자세한 설명은 설명 자료를 참고하세요.
다음 단계
이제 집계 서비스의 주요 내용을 살펴봤으므로 Google Cloud 또는 Amazon Web Services를 통해 집계 서비스의 자체 인스턴스를 배포할 차례입니다. 시작하기 섹션을 확인하거나 배포된 집계 서비스를 운영하는 방법에 관한 자세한 내용이 필요한 경우 이 링크를 따라 집계 서비스 운영에 대해 자세히 알아보세요.
문제 해결
오류 메시지, 발생한 오류의 원인, 완화 조치의 다음 단계에 관한 자세한 설명은 일반적인 오류 코드 및 완화 조치 문서를 참고하세요.
지원받기 및 의견 보내기
- 제품 관련 질문, 의견, 기능 요청은 GitHub 저장소에서 문제를 만드세요.
- 집계 서비스로 작업을 배포, 유지 관리 또는 실행하는 중에 오류가 발생한 경우 기술 문제 해결 지원을 요청하려면 이 기술 지원 양식을 사용하세요.
- 공개 상태 대시보드에서 알려진 문제를 확인하세요.